 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeroGS: Hierarchical Guidance for Robust 3D Gaussian Splatting under Sparse Views
Mar 03, 20263D Gaussian Splatting (3DGS) has recently emerged as a promising approach in novel view synthesis, combining photorealistic rendering with real-time efficiency. However, its success heavily relies on dense camera coverage; under sparse-view conditions, insufficient supervision leads to irregular Gaussian distributions, characterized by globally sparse coverage, blurred background, and distorted high-frequency areas. To address this, we propose HeroGS, Hierarchical Guidance for Robust 3D Gaussian Splatting, a unified framework that establishes hierarchical guidance across the image, feature, and parameter levels. At the image level, sparse supervision is converted into pseudo-dense guidance, globally regularizing the Gaussian distributions and forming a consistent foundation for subsequent optimization. Building upon this, Feature-Adaptive Densification and Pruning (FADP) at the feature level leverages low-level features to refine high-frequency details and adaptively densifies Gaussians in background regions. The optimized distributions then support Co-Pruned Geometry Consistency (CPG) at parameter level, which guides geometric consistency through parameter freezing and co-pruning, effectively removing inconsistent splats. The hierarchical guidance strategy effectively constrains and optimizes the overall Gaussian distributions, thereby enhancing both structural fidelity and rendering quality. Extensive experiments demonstrate that HeroGS achieves high-fidelity reconstructions and consistently surpasses state-of-the-art baselines under sparse-view conditions.
SAPNet++: Evolving Point-Prompted Instance Segmentation with Semantic and Spatial Awareness
Feb 25, 2026Single-point annotation is increasingly prominent in visual tasks for labeling cost reduction. However, it challenges tasks requiring high precision, such as the point-prompted instance segmentation (PPIS) task, which aims to estimate precise masks using single-point prompts to train a segmentation network. Due to the constraints of point annotations, granularity ambiguity and boundary uncertainty arise the difficulty distinguishing between different levels of detail (eg. whole object vs. parts) and the challenge of precisely delineating object boundaries. Previous works have usually inherited the paradigm of mask generation along with proposal selection to achieve PPIS. However, proposal selection relies solely on category information, failing to resolve the ambiguity of different granularity. Furthermore, mask generators offer only finite discrete solutions that often deviate from actual masks, particularly at boundaries. To address these issues, we propose the Semantic-Aware Point-Prompted Instance Segmentation Network (SAPNet). It integrates Point Distance Guidance and Box Mining Strategy to tackle group and local issues caused by the point's granularity ambiguity. Additionally, we incorporate completeness scores within proposals to add spatial granularity awareness, enhancing multiple instance learning (MIL) in proposal selection termed S-MIL. The Multi-level Affinity Refinement conveys pixel and semantic clues, narrowing boundary uncertainty during mask refinement. These modules culminate in SAPNet++, mitigating point prompt's granularity ambiguity and boundary uncertainty and significantly improving segmentation performance. Extensive experiments on four challenging datasets validate the effectiveness of our methods, highlighting the potential to advance PPIS.
* 18 pages
Exploring the Temporal Consistency for Point-Level Weakly-Supervised Temporal Action Localization
Feb 05, 2026Point-supervised Temporal Action Localization (PTAL) adopts a lightly frame-annotated paradigm (\textit{i.e.}, labeling only a single frame per action instance) to train a model to effectively locate action instances within untrimmed videos. Most existing approaches design the task head of models with only a point-supervised snippet-level classification, without explicit modeling of understanding temporal relationships among frames of an action. However, understanding the temporal relationships of frames is crucial because it can help a model understand how an action is defined and therefore benefits localizing the full frames of an action. To this end, in this paper, we design a multi-task learning framework that fully utilizes point supervision to boost the model's temporal understanding capability for action localization. Specifically, we design three self-supervised temporal understanding tasks: (i) Action Completion, (ii) Action Order Understanding, and (iii) Action Regularity Understanding. These tasks help a model understand the temporal consistency of actions across videos. To the best of our knowledge, this is the first attempt to explicitly explore temporal consistency for point supervision action localization. Extensive experimental results on four benchmark datasets demonstrate the effectiveness of the proposed method compared to several state-of-the-art approaches.
Boosting Point-supervised Temporal Action Localization via Text Refinement and Alignment
Feb 01, 2026Recently, point-supervised temporal action localization has gained significant attention for its effective balance between labeling costs and localization accuracy. However, current methods only consider features from visual inputs, neglecting helpful semantic information from the text side. To address this issue, we propose a Text Refinement and Alignment (TRA) framework that effectively utilizes textual features from visual descriptions to complement the visual features as they are semantically rich. This is achieved by designing two new modules for the original point-supervised framework: a Point-based Text Refinement module (PTR) and a Point-based Multimodal Alignment module (PMA). Specifically, we first generate descriptions for video frames using a pre-trained multimodal model. Next, PTR refines the initial descriptions by leveraging point annotations together with multiple pre-trained models. PMA then projects all features into a unified semantic space and leverages a point-level multimodal feature contrastive learning to reduce the gap between visual and linguistic modalities. Last, the enhanced multi-modal features are fed into the action detector for precise localization. Extensive experimental results on five widely used benchmarks demonstrate the favorable performance of our proposed framework compared to several state-of-the-art methods. Moreover, our computational overhead analysis shows that the framework can run on a single 24 GB RTX 3090 GPU, indicating its practicality and scalability.
Towards Universal Modal Tracking with Online Dense Temporal Token Learning
Jul 27, 2025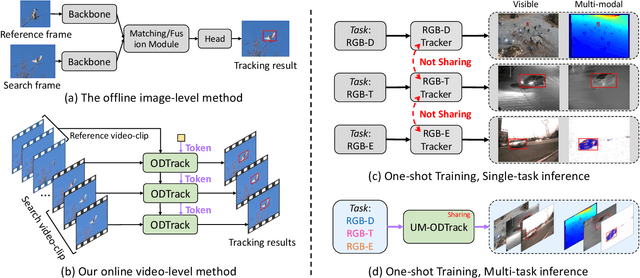


We propose a universal video-level modality-awareness tracking model with online dense temporal token learning (called {\modaltracker}). It is designed to support various tracking tasks, including RGB, RGB+Thermal, RGB+Depth, and RGB+Event, utilizing the same model architecture and parameters. Specifically, our model is designed with three core goals: \textbf{Video-level Sampling}. We expand the model's inputs to a video sequence level, aiming to see a richer video context from an near-global perspective. \textbf{Video-level Association}. Furthermore, we introduce two simple yet effective online dense temporal token association mechanisms to propagate the appearance and motion trajectory information of target via a video stream manner. \textbf{Modality Scalable}. We propose two novel gated perceivers that adaptively learn cross-modal representations via a gated attention mechanism, and subsequently compress them into the same set of model parameters via a one-shot training manner for multi-task inference. This new solution brings the following benefits: (i) The purified token sequences can serve as temporal prompts for the inference in the next video frames, whereby previous information is leveraged to guide future inference. (ii) Unlike multi-modal trackers that require independent training, our one-shot training scheme not only alleviates the training burden, but also improves model representation. Extensive experiments on visible and multi-modal benchmarks show that our {\modaltracker} achieves a new \textit{SOTA} performance. The code will be available at https://github.com/GXNU-ZhongLab/ODTrack.
SDVPT: Semantic-Driven Visual Prompt Tuning for Open-World Object Counting
Apr 24, 2025

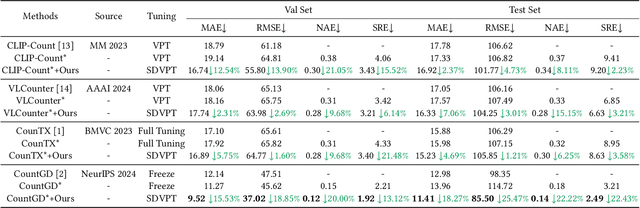
Open-world object counting leverages the robust text-image alignment of pre-trained vision-language models (VLMs) to enable counting of arbitrary categories in images specified by textual queries. However, widely adopted naive fine-tuning strategies concentrate exclusively on text-image consistency for categories contained in training, which leads to limited generalizability for unseen categories. In this work, we propose a plug-and-play Semantic-Driven Visual Prompt Tuning framework (SDVPT) that transfers knowledge from the training set to unseen categories with minimal overhead in parameters and inference time. First, we introduce a two-stage visual prompt learning strategy composed of Category-Specific Prompt Initialization (CSPI) and Topology-Guided Prompt Refinement (TGPR). The CSPI generates category-specific visual prompts, and then TGPR distills latent structural patterns from the VLM's text encoder to refine these prompts. During inference, we dynamically synthesize the visual prompts for unseen categories based on the semantic correlation between unseen and training categories, facilitating robust text-image alignment for unseen categories. Extensive experiments integrating SDVPT with all available open-world object counting models demonstrate its effectiveness and adaptability across three widely used datasets: FSC-147, CARPK, and PUCPR+.
P2Object: Single Point Supervised Object Detection and Instance Segmentation
Apr 10, 2025Object recognition using single-point supervision has attracted increasing attention recently. However, the performance gap compared with fully-supervised algorithms remains large. Previous works generated class-agnostic \textbf{\textit{proposals in an image}} offline and then treated mixed candidates as a single bag, putting a huge burden on multiple instance learning (MIL). In this paper, we introduce Point-to-Box Network (P2BNet), which constructs balanced \textbf{\textit{instance-level proposal bags}} by generating proposals in an anchor-like way and refining the proposals in a coarse-to-fine paradigm. Through further research, we find that the bag of proposals, either at the image level or the instance level, is established on discrete box sampling. This leads the pseudo box estimation into a sub-optimal solution, resulting in the truncation of object boundaries or the excessive inclusion of background. Hence, we conduct a series exploration of discrete-to-continuous optimization, yielding P2BNet++ and Point-to-Mask Network (P2MNet). P2BNet++ conducts an approximately continuous proposal sampling strategy by better utilizing spatial clues. P2MNet further introduces low-level image information to assist in pixel prediction, and a boundary self-prediction is designed to relieve the limitation of the estimated boxes. Benefiting from the continuous object-aware \textbf{\textit{pixel-level perception}}, P2MNet can generate more precise bounding boxes and generalize to segmentation tasks. Our method largely surpasses the previous methods in terms of the mean average precision on COCO, VOC, SBD, and Cityscapes, demonstrating great potential to bridge the performance gap compared with fully supervised tasks.
The Devil is in the Distributions: Explicit Modeling of Scene Content is Key in Zero-Shot Video Captioning
Mar 31, 2025
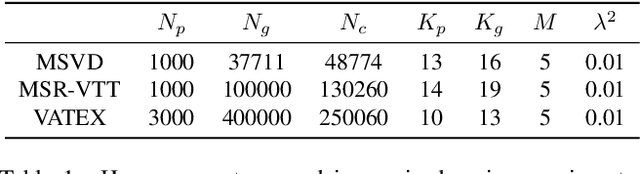

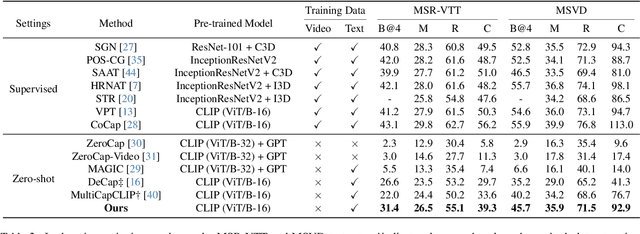
Zero-shot video captioning requires that a model generate high-quality captions without human-annotated video-text pairs for training. State-of-the-art approaches to the problem leverage CLIP to extract visual-relevant textual prompts to guide language models in generating captions. These methods tend to focus on one key aspect of the scene and build a caption that ignores the rest of the visual input. To address this issue, and generate more accurate and complete captions, we propose a novel progressive multi-granularity textual prompting strategy for zero-shot video captioning. Our approach constructs three distinct memory banks, encompassing noun phrases, scene graphs of noun phrases, and entire sentences. Moreover, we introduce a category-aware retrieval mechanism that models the distribution of natural language surrounding the specific topics in question. Extensive experiments demonstrate the effectiveness of our method with 5.7%, 16.2%, and 3.4% improvements in terms of the main metric CIDEr on MSR-VTT, MSVD, and VATEX benchmarks compared to existing state-of-the-art.
Less is More: Token Context-aware Learning for Object Tracking
Jan 01, 2025Recently, several studies have shown that utilizing contextual information to perceive target states is crucial for object tracking. They typically capture context by incorporating multiple video frames. However, these naive frame-context methods fail to consider the importance of each patch within a reference frame, making them susceptible to noise and redundant tokens, which deteriorates tracking performance. To address this challenge, we propose a new token context-aware tracking pipeline named LMTrack, designed to automatically learn high-quality reference tokens for efficient visual tracking. Embracing the principle of Less is More, the core idea of LMTrack is to analyze the importance distribution of all reference tokens, where important tokens are collected, continually attended to, and updated. Specifically, a novel Token Context Memory module is designed to dynamically collect high-quality spatio-temporal information of a target in an autoregressive manner, eliminating redundant background tokens from the reference frames. Furthermore, an effective Unidirectional Token Attention mechanism is designed to establish dependencies between reference tokens and search frame, enabling robust cross-frame association and target localization. Extensive experiments demonstrate the superiority of our tracker, achieving state-of-the-art results on tracking benchmarks such as GOT-10K, TrackingNet, and LaSOT.
MambaLCT: Boosting Tracking via Long-term Context State Space Model
Dec 18, 2024



Effectively constructing context information with long-term dependencies from video sequences is crucial for object tracking. However, the context length constructed by existing work is limited, only considering object information from adjacent frames or video clips, leading to insufficient utilization of contextual information. To address this issue, we propose MambaLCT, which constructs and utilizes target variation cues from the first frame to the current frame for robust tracking. First, a novel unidirectional Context Mamba module is designed to scan frame features along the temporal dimension, gathering target change cues throughout the entire sequence. Specifically, target-related information in frame features is compressed into a hidden state space through selective scanning mechanism. The target information across the entire video is continuously aggregated into target variation cues. Next, we inject the target change cues into the attention mechanism, providing temporal information for modeling the relationship between the template and search frames. The advantage of MambaLCT is its ability to continuously extend the length of the context, capturing complete target change cues, which enhances the stability and robustness of the tracker. Extensive experiments show that long-term context information enhances the model's ability to perceive targets in complex scenarios. MambaLCT achieves new SOTA performance on six benchmarks while maintaining real-time running speeds.