 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Component Analysis: A Principled Approach for Concept Extraction in LLMs
Jan 29, 2026Developing human understandable interpretation of large language models (LLMs) becomes increasingly critical for their deployment in essential domains. Mechanistic interpretability seeks to mitigate the issues through extracts human-interpretable process and concepts from LLMs' activations. Sparse autoencoders (SAEs) have emerged as a popular approach for extracting interpretable and monosemantic concepts by decomposing the LLM internal representations into a dictionary. Despite their empirical progress, SAEs suffer from a fundamental theoretical ambiguity: the well-defined correspondence between LLM representations and human-interpretable concepts remains unclear. This lack of theoretical grounding gives rise to several methodological challenges, including difficulties in principled method design and evaluation criteria. In this work, we show that, under mild assumptions, LLM representations can be approximated as a {linear mixture} of the log-posteriors over concepts given the input context, through the lens of a latent variable model where concepts are treated as latent variables. This motivates a principled framework for concept extraction, namely Concept Component Analysis (ConCA), which aims to recover the log-posterior of each concept from LLM representations through a {unsupervised} linear unmixing process. We explore a specific variant, termed sparse ConCA, which leverages a sparsity prior to address the inherent ill-posedness of the unmixing problem. We implement 12 sparse ConCA variants and demonstrate their ability to extract meaningful concepts across multiple LLMs, offering theory-backed advantages over SAEs.
The Geometric Mechanics of Contrastive Representation Learning: Alignment Potentials, Entropic Dispersion, and Cross-Modal Divergence
Jan 27, 2026While InfoNCE powers modern contrastive learning, its geometric mechanisms remain under-characterized beyond the canonical alignment--uniformity decomposition. We present a measure-theoretic framework that models learning as the evolution of representation measures on a fixed embedding manifold. By establishing value and gradient consistency in the large-batch limit, we bridge the stochastic objective to explicit deterministic energy landscapes, uncovering a fundamental geometric bifurcation between the unimodal and multimodal regimes. In the unimodal setting, the intrinsic landscape is strictly convex with a unique Gibbs equilibrium; here, entropy acts merely as a tie-breaker, clarifying "uniformity" as a constrained expansion within the alignment basin. In contrast, the symmetric multimodal objective contains a persistent negative symmetric divergence term that remains even after kernel sharpening. We show that this term induces barrier-driven co-adaptation, enforcing a population-level modality gap as a structural geometric necessity rather than an initialization artifact. Our results shift the analytical lens from pointwise discrimination to population geometry, offering a principled basis for diagnosing and controlling distributional misalignment.
Learning to Reason and Navigate: Parameter Efficient Action Planning with Large Language Models
May 12, 2025The remote embodied referring expression (REVERIE) task requires an agent to navigate through complex indoor environments and localize a remote object specified by high-level instructions, such as "bring me a spoon", without pre-exploration. Hence, an efficient navigation plan is essential for the final success. This paper proposes a novel parameter-efficient action planner using large language models (PEAP-LLM) to generate a single-step instruction at each location. The proposed model consists of two modules, LLM goal planner (LGP) and LoRA action planner (LAP). Initially, LGP extracts the goal-oriented plan from REVERIE instructions, including the target object and room. Then, LAP generates a single-step instruction with the goal-oriented plan, high-level instruction, and current visual observation as input. PEAP-LLM enables the embodied agent to interact with LAP as the path planner on the fly. A simple direct application of LLMs hardly achieves good performance. Also, existing hard-prompt-based methods are error-prone in complicated scenarios and need human intervention. To address these issues and prevent the LLM from generating hallucinations and biased information, we propose a novel two-stage method for fine-tuning the LLM, consisting of supervised fine-tuning (STF) and direct preference optimization (DPO). SFT improves the quality of generated instructions, while DPO utilizes environmental feedback. Experimental results show the superiority of our proposed model on REVERIE compared to the previous state-of-the-art.
Negate or Embrace: On How Misalignment Shapes Multimodal Representation Learning
Apr 16, 2025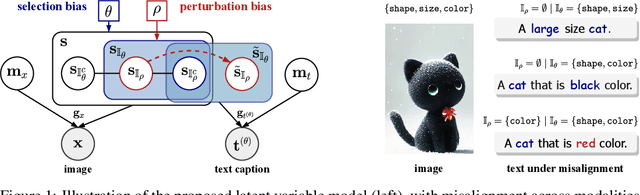

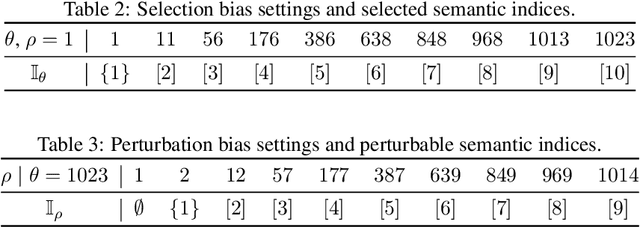

Multimodal representation learning, exemplified by multimodal contrastive learning (MMCL) using image-text pairs, aims to learn powerful representations by aligning cues across modalities. This approach relies on the core assumption that the exemplar image-text pairs constitute two representations of an identical concept. However, recent research has revealed that real-world datasets often exhibit misalignment. There are two distinct viewpoints on how to address this issue: one suggests mitigating the misalignment, and the other leveraging it. We seek here to reconcile these seemingly opposing perspectives, and to provide a practical guide for practitioners. Using latent variable models we thus formalize misalignment by introducing two specific mechanisms: selection bias, where some semantic variables are missing, and perturbation bias, where semantic variables are distorted -- both affecting latent variables shared across modalities. Our theoretical analysis demonstrates that, under mild assumptions, the representations learned by MMCL capture exactly the information related to the subset of the semantic variables invariant to selection and perturbation biases. This provides a unified perspective for understanding misalignment. Based on this, we further offer actionable insights into how misalignment should inform the design of real-world ML systems. We validate our theoretical findings through extensive empirical studies on both synthetic data and real image-text datasets, shedding light on the nuanced impact of misalignment on multimodal representation learning.
The Devil is in the Distributions: Explicit Modeling of Scene Content is Key in Zero-Shot Video Captioning
Mar 31, 2025

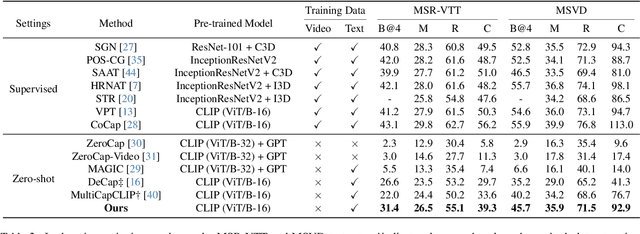
Zero-shot video captioning requires that a model generate high-quality captions without human-annotated video-text pairs for training. State-of-the-art approaches to the problem leverage CLIP to extract visual-relevant textual prompts to guide language models in generating captions. These methods tend to focus on one key aspect of the scene and build a caption that ignores the rest of the visual input. To address this issue, and generate more accurate and complete captions, we propose a novel progressive multi-granularity textual prompting strategy for zero-shot video captioning. Our approach constructs three distinct memory banks, encompassing noun phrases, scene graphs of noun phrases, and entire sentences. Moreover, we introduce a category-aware retrieval mechanism that models the distribution of natural language surrounding the specific topics in question. Extensive experiments demonstrate the effectiveness of our method with 5.7%, 16.2%, and 3.4% improvements in terms of the main metric CIDEr on MSR-VTT, MSVD, and VATEX benchmarks compared to existing state-of-the-art.
Analytic DAG Constraints for Differentiable DAG Learning
Mar 24, 2025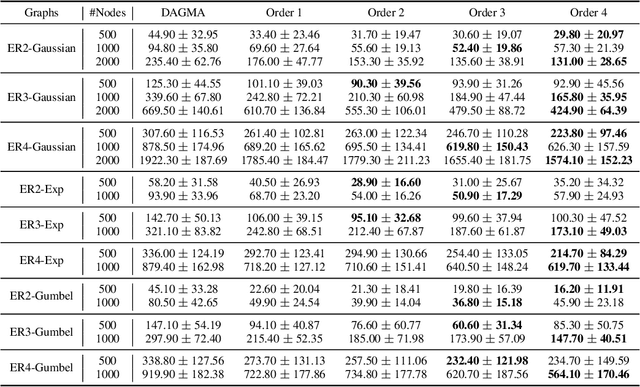
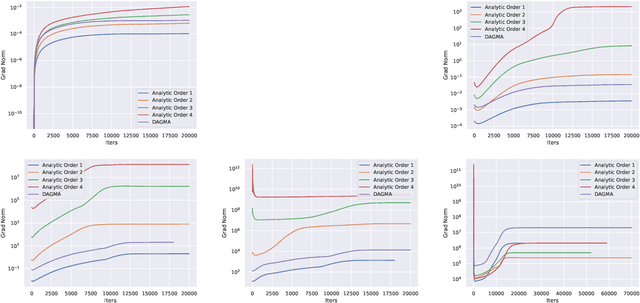
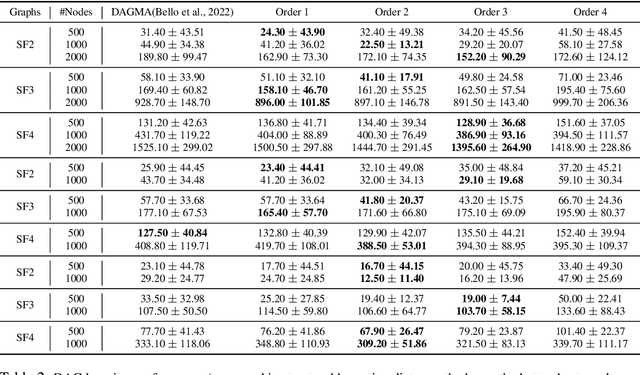

Recovering the underlying Directed Acyclic Graph (DAG) structures from observational data presents a formidable challenge, partly due to the combinatorial nature of the DAG-constrained optimization problem. Recently, researchers have identified gradient vanishing as one of the primary obstacles in differentiable DAG learning and have proposed several DAG constraints to mitigate this issue. By developing the necessary theory to establish a connection between analytic functions and DAG constraints, we demonstrate that analytic functions from the set $\{f(x) = c_0 + \sum_{i=1}^{\infty}c_ix^i | \forall i > 0, c_i > 0; r = \lim_{i\rightarrow \infty}c_{i}/c_{i+1} > 0\}$ can be employed to formulate effective DAG constraints. Furthermore, we establish that this set of functions is closed under several functional operators, including differentiation, summation, and multiplication. Consequently, these operators can be leveraged to create novel DAG constraints based on existing ones. Using these properties, we design a series of DAG constraints and develop an efficient algorithm to evaluate them. Experiments in various settings demonstrate that our DAG constraints outperform previous state-of-the-art comparators. Our implementation is available at https://github.com/zzhang1987/AnalyticDAGLearning.
* Accepted to ICLR 2025
I Predict Therefore I Am: Is Next Token Prediction Enough to Learn Human-Interpretable Concepts from Data?
Mar 12, 2025The remarkable achievements of large language models (LLMs) have led many to conclude that they exhibit a form of intelligence. This is as opposed to explanations of their capabilities based on their ability to perform relatively simple manipulations of vast volumes of data. To illuminate the distinction between these explanations, we introduce a novel generative model that generates tokens on the basis of human interpretable concepts represented as latent discrete variables. Under mild conditions, even when the mapping from the latent space to the observed space is non-invertible, we establish an identifiability result: the representations learned by LLMs through next-token prediction can be approximately modeled as the logarithm of the posterior probabilities of these latent discrete concepts, up to an invertible linear transformation. This theoretical finding not only provides evidence that LLMs capture underlying generative factors, but also strongly reinforces the linear representation hypothesis, which posits that LLMs learn linear representations of human-interpretable concepts. Empirically, we validate our theoretical results through evaluations on both simulation data and the Pythia, Llama, and DeepSeek model families.
Rethinking State Disentanglement in Causal Reinforcement Learning
Aug 24, 2024



One of the significant challenges in reinforcement learning (RL) when dealing with noise is estimating latent states from observations. Causality provides rigorous theoretical support for ensuring that the underlying states can be uniquely recovered through identifiability. Consequently, some existing work focuses on establishing identifiability from a causal perspective to aid in the design of algorithms. However, these results are often derived from a purely causal viewpoint, which may overlook the specific RL context. We revisit this research line and find that incorporating RL-specific context can reduce unnecessary assumptions in previous identifiability analyses for latent states. More importantly, removing these assumptions allows algorithm design to go beyond the earlier boundaries constrained by them. Leveraging these insights, we propose a novel approach for general partially observable Markov Decision Processes (POMDPs) by replacing the complicated structural constraints in previous methods with two simple constraints for transition and reward preservation. With the two constraints, the proposed algorithm is guaranteed to disentangle state and noise that is faithful to the underlying dynamics. Empirical evidence from extensive benchmark control tasks demonstrates the superiority of our approach over existing counterparts in effectively disentangling state belief from noise.
MINI-LLM: Memory-Efficient Structured Pruning for Large Language Models
Jul 16, 2024As Large Language Models (LLMs) grow dramatically in size, there is an increasing trend in compressing and speeding up these models. Previous studies have highlighted the usefulness of gradients for importance scoring in neural network compressing, especially in pruning medium-size networks. However, the substantial memory requirements involved in calculating gradients with backpropagation impede the utilization of gradients in guiding LLM pruning. As a result, most pruning strategies for LLMs rely on gradient-free criteria, such as weight magnitudes or a mix of magnitudes and activations. In this paper, we devise a hybrid pruning criterion, which appropriately integrates magnitude, activation, and gradient to capitalize on feature map sensitivity for pruning LLMs. To overcome memory requirement barriers, we estimate gradients using only forward passes. Based on this, we propose a Memory-effIcieNt structured prunIng procedure for LLMs (MINI-LLM) to remove no-critical channels and multi-attention heads. Experimental results demonstrate the superior performance of MINI-LLM over existing gradient-free methods on three LLMs: LLaMA, BLOOM, and OPT across various downstream tasks (classification, multiple-choice, and generation), while MINI-LLM maintains a GPU memory footprint akin to gradient-free methods.
Augmented Commonsense Knowledge for Remote Object Grounding
Jun 03, 2024



The vision-and-language navigation (VLN) task necessitates an agent to perceive the surroundings, follow natural language instructions, and act in photo-realistic unseen environments. Most of the existing methods employ the entire image or object features to represent navigable viewpoints. However, these representations are insufficient for proper action prediction, especially for the REVERIE task, which uses concise high-level instructions, such as ''Bring me the blue cushion in the master bedroom''. To address enhancing representation, we propose an augmented commonsense knowledge model (ACK) to leverage commonsense information as a spatio-temporal knowledge graph for improving agent navigation. Specifically, the proposed approach involves constructing a knowledge base by retrieving commonsense information from ConceptNet, followed by a refinement module to remove noisy and irrelevant knowledge. We further present ACK which consists of knowledge graph-aware cross-modal and concept aggregation modules to enhance visual representation and visual-textual data alignment by integrating visible objects, commonsense knowledge, and concept history, which includes object and knowledge temporal information. Moreover, we add a new pipeline for the commonsense-based decision-making process which leads to more accurate local action prediction. Experimental results demonstrate our proposed model noticeably outperforms the baseline and archives the state-of-the-art on the REVERIE benchmark.