 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiDexGrasp: Coordinated Bimanual Dexterous Grasps across Object Geometries and Sizes
Apr 08, 2026Bimanual dexterous grasping is a fundamental and promising area in robotics, yet its progress is constrained by the lack of comprehensive datasets and powerful generation models. In this work, we propose BiDexGrasp, consists of a large-scale bimanual dexterous grasp dataset and a novel generation model. For dataset, we propose a novel bimanual grasp synthesis pipeline to efficiently annotate physically feasible data for dataset construction. This pipeline addresses the challenges of high-dimensional bimanual grasping through a two-stage synthesis strategy of efficient region-based grasp initialization and decoupled force-closure grasp optimization. Powered by this pipeline, we construct a large-scale bimanual dexterous grasp dataset, comprising 6351 diverse objects with sizes ranging from 30 to 80 cm, along with 9.7 million annotated grasp data. Based on this dataset, we further introduce a bimanual-coordinated and geometry-size-adaptive dexterous grasping generation framework. The framework lies in two key designs: a bimanual coordination module and a geometry-size-adaptive grasp generation strategy to generate coordinated and high-quality grasps on unseen objects. Extensive experiments conducted in both simulation and real world demonstrate the superior performance of our proposed data synthesis pipeline and learned generative framework.
DexGrasp-Zero: A Morphology-Aligned Policy for Zero-Shot Cross-Embodiment Dexterous Grasping
Mar 17, 2026To meet the demands of increasingly diverse dexterous hand hardware, it is crucial to develop a policy that enables zero-shot cross-embodiment grasping without redundant re-learning. Cross-embodiment alignment is challenging due to heterogeneous hand kinematics and physical constraints. Existing approaches typically predict intermediate motion targets and retarget them to each embodiment, which may introduce errors and violate embodiment-specific limits, hindering transfer across diverse hands. To overcome these limitations, we propose \textit{DexGrasp-Zero}, a policy that learns universal grasping skills from diverse embodiments, enabling zero-shot transfer to unseen hands. We first introduce a morphology-aligned graph representation that maps each hand's kinematic keypoints to anatomically grounded nodes and equips each node with tri-axial orthogonal motion primitives, enabling structural and semantic alignment across different morphologies. Relying on this graph-based representation, we design a \textit{Morphology-Aligned Graph Convolutional Network} (MAGCN) to encode the graph for policy learning. MAGCN incorporates a \textit{Physical Property Injection} mechanism that fuses hand-specific physical constraints into the graph features, enabling adaptive compensation for varying link lengths and actuation limits for precise and stable grasping. Our extensive simulation evaluations on the YCB dataset demonstrate that our policy, jointly trained on four heterogeneous hands (Allegro, Shadow, Schunk, Ability), achieves an 85\% zero-shot success rate on unseen hardware (LEAP, Inspire), outperforming the state-of-the-art method by 59.5\%. Real-world experiments further evaluate our policy on three robot platforms (LEAP, Inspire, Revo2), achieving an 82\% average success rate on unseen objects.
ZeroDexGrasp: Zero-Shot Task-Oriented Dexterous Grasp Synthesis with Prompt-Based Multi-Stage Semantic Reasoning
Nov 17, 2025Task-oriented dexterous grasping holds broad application prospects in robotic manipulation and human-object interaction. However, most existing methods still struggle to generalize across diverse objects and task instructions, as they heavily rely on costly labeled data to ensure task-specific semantic alignment. In this study, we propose \textbf{ZeroDexGrasp}, a zero-shot task-oriented dexterous grasp synthesis framework integrating Multimodal Large Language Models with grasp refinement to generate human-like grasp poses that are well aligned with specific task objectives and object affordances. Specifically, ZeroDexGrasp employs prompt-based multi-stage semantic reasoning to infer initial grasp configurations and object contact information from task and object semantics, then exploits contact-guided grasp optimization to refine these poses for physical feasibility and task alignment. Experimental results demonstrate that ZeroDexGrasp enables high-quality zero-shot dexterous grasping on diverse unseen object categories and complex task requirements, advancing toward more generalizable and intelligent robotic grasping.
OmniDexGrasp: Generalizable Dexterous Grasping via Foundation Model and Force Feedback
Oct 27, 2025



Enabling robots to dexterously grasp and manipulate objects based on human commands is a promising direction in robotics. However, existing approaches are challenging to generalize across diverse objects or tasks due to the limited scale of semantic dexterous grasp datasets. Foundation models offer a new way to enhance generalization, yet directly leveraging them to generate feasible robotic actions remains challenging due to the gap between abstract model knowledge and physical robot execution. To address these challenges, we propose OmniDexGrasp, a generalizable framework that achieves omni-capabilities in user prompting, dexterous embodiment, and grasping tasks by combining foundation models with the transfer and control strategies. OmniDexGrasp integrates three key modules: (i) foundation models are used to enhance generalization by generating human grasp images supporting omni-capability of user prompt and task; (ii) a human-image-to-robot-action transfer strategy converts human demonstrations into executable robot actions, enabling omni dexterous embodiment; (iii) force-aware adaptive grasp strategy ensures robust and stable grasp execution. Experiments in simulation and on real robots validate the effectiveness of OmniDexGrasp on diverse user prompts, grasp task and dexterous hands, and further results show its extensibility to dexterous manipulation tasks.
TypeTele: Releasing Dexterity in Teleoperation by Dexterous Manipulation Types
Jul 02, 2025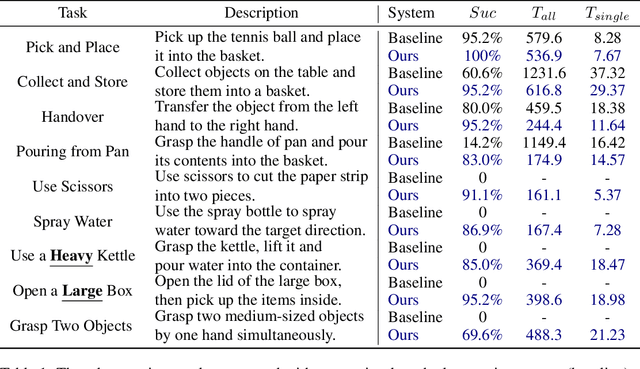


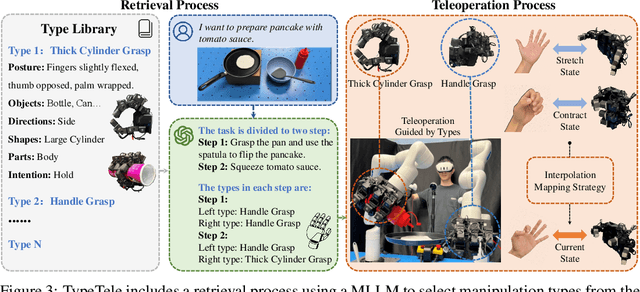
Dexterous teleoperation plays a crucial role in robotic manipulation for real-world data collection and remote robot control. Previous dexterous teleoperation mostly relies on hand retargeting to closely mimic human hand postures. However, these approaches may fail to fully leverage the inherent dexterity of dexterous hands, which can execute unique actions through their structural advantages compared to human hands. To address this limitation, we propose TypeTele, a type-guided dexterous teleoperation system, which enables dexterous hands to perform actions that are not constrained by human motion patterns. This is achieved by introducing dexterous manipulation types into the teleoperation system, allowing operators to employ appropriate types to complete specific tasks. To support this system, we build an extensible dexterous manipulation type library to cover comprehensive dexterous postures used in manipulation tasks. During teleoperation, we employ a MLLM (Multi-modality Large Language Model)-assisted type retrieval module to identify the most suitable manipulation type based on the specific task and operator commands. Extensive experiments of real-world teleoperation and imitation learning demonstrate that the incorporation of manipulation types significantly takes full advantage of the dexterous robot's ability to perform diverse and complex tasks with higher success rates.
Guiding LLM-based Smart Contract Generation with Finite State Machine
May 13, 2025Smart contract is a kind of self-executing code based on blockchain technology with a wide range of application scenarios, but the traditional generation method relies on manual coding and expert auditing, which has a high threshold and low efficiency. Although Large Language Models (LLMs) show great potential in programming tasks, they still face challenges in smart contract generation w.r.t. effectiveness and security. To solve these problems, we propose FSM-SCG, a smart contract generation framework based on finite state machine (FSM) and LLMs, which significantly improves the quality of the generated code by abstracting user requirements to generate FSM, guiding LLMs to generate smart contracts, and iteratively optimizing the code with the feedback of compilation and security checks. The experimental results show that FSM-SCG significantly improves the quality of smart contract generation. Compared to the best baseline, FSM-SCG improves the compilation success rate of generated smart contract code by at most 48%, and reduces the average vulnerability risk score by approximately 68%.
AffordDexGrasp: Open-set Language-guided Dexterous Grasp with Generalizable-Instructive Affordance
Mar 10, 2025Language-guided robot dexterous generation enables robots to grasp and manipulate objects based on human commands. However, previous data-driven methods are hard to understand intention and execute grasping with unseen categories in the open set. In this work, we explore a new task, Open-set Language-guided Dexterous Grasp, and find that the main challenge is the huge gap between high-level human language semantics and low-level robot actions. To solve this problem, we propose an Affordance Dexterous Grasp (AffordDexGrasp) framework, with the insight of bridging the gap with a new generalizable-instructive affordance representation. This affordance can generalize to unseen categories by leveraging the object's local structure and category-agnostic semantic attributes, thereby effectively guiding dexterous grasp generation. Built upon the affordance, our framework introduces Affordacne Flow Matching (AFM) for affordance generation with language as input, and Grasp Flow Matching (GFM) for generating dexterous grasp with affordance as input. To evaluate our framework, we build an open-set table-top language-guided dexterous grasp dataset. Extensive experiments in the simulation and real worlds show that our framework surpasses all previous methods in open-set generalization.
TacCap: A Wearable FBG-Based Tactile Sensor for Seamless Human-to-Robot Skill Transfer
Mar 03, 2025Tactile sensing is essential for dexterous manipulation, yet large-scale human demonstration datasets lack tactile feedback, limiting their effectiveness in skill transfer to robots. To address this, we introduce TacCap, a wearable Fiber Bragg Grating (FBG)-based tactile sensor designed for seamless human-to-robot transfer. TacCap is lightweight, durable, and immune to electromagnetic interference, making it ideal for real-world data collection. We detail its design and fabrication, evaluate its sensitivity, repeatability, and cross-sensor consistency, and assess its effectiveness through grasp stability prediction and ablation studies. Our results demonstrate that TacCap enables transferable tactile data collection, bridging the gap between human demonstrations and robotic execution. To support further research and development, we open-source our hardware design and software.
Categorical Keypoint Positional Embedding for Robust Animal Re-Identification
Dec 01, 2024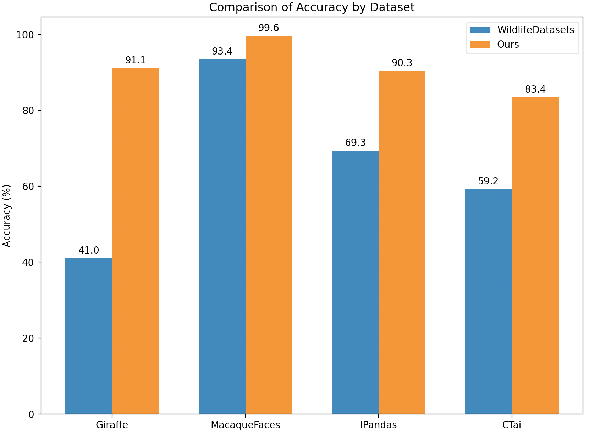
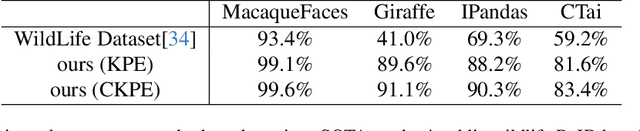

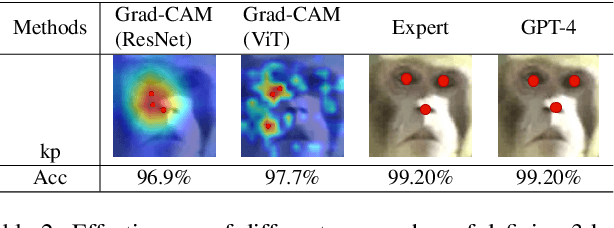
Animal re-identification (ReID) has become an indispensable tool in ecological research, playing a critical role in tracking population dynamics, analyzing behavioral patterns, and assessing ecological impacts, all of which are vital for informed conservation strategies. Unlike human ReID, animal ReID faces significant challenges due to the high variability in animal poses, diverse environmental conditions, and the inability to directly apply pre-trained models to animal data, making the identification process across species more complex. This work introduces an innovative keypoint propagation mechanism, which utilizes a single annotated image and a pre-trained diffusion model to propagate keypoints across an entire dataset, significantly reducing the cost of manual annotation. Additionally, we enhance the Vision Transformer (ViT) by implementing Keypoint Positional Encoding (KPE) and Categorical Keypoint Positional Embedding (CKPE), enabling the ViT to learn more robust and semantically-aware representations. This provides more comprehensive and detailed keypoint representations, leading to more accurate and efficient re-identification. Our extensive experimental evaluations demonstrate that this approach significantly outperforms existing state-of-the-art methods across four wildlife datasets. The code will be publicly released.
A Simple-but-effective Baseline for Training-free Class-Agnostic Counting
Mar 03, 2024



Class-Agnostic Counting (CAC) seeks to accurately count objects in a given image with only a few reference examples. While previous methods achieving this relied on additional training, recent efforts have shown that it's possible to accomplish this without training by utilizing pre-existing foundation models, particularly the Segment Anything Model (SAM), for counting via instance-level segmentation. Although promising, current training-free methods still lag behind their training-based counterparts in terms of performance. In this research, we present a straightforward training-free solution that effectively bridges this performance gap, serving as a strong baseline. The primary contribution of our work lies in the discovery of four key technologies that can enhance performance. Specifically, we suggest employing a superpixel algorithm to generate more precise initial point prompts, utilizing an image encoder with richer semantic knowledge to replace the SAM encoder for representing candidate objects, and adopting a multiscale mechanism and a transductive prototype scheme to update the representation of reference examples. By combining these four technologies, our approach achieves significant improvements over existing training-free methods and delivers performance on par with training-based ones.