 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-attributed Graph Condensation via Text Selection and Attribute Matching
Jun 02, 2026Text-Attributed Graph (TAG) is an important type of graph structured data, where each node has a text description. TAG models usually train a Graph Neural Network (GNN) and language model jointly, which leads to high space and time consumption, especially on large datasets. To mitigate this, we propose TAGSAM, a condensation method that compresses TAGs while preserving training accuracy. TAGSAM comes with two key designs, i.e., subgraph text Selection and Attribute similarity Matching, which compress the text description and graph topology of TAG, respectively. For the texts, subgraph text selection selects and merges representative text chunks from multiple related text descriptions by maximizing mutual information. For the graph topology, popular condensation methods based on Matching Training Trajectories (MTT) suffer from high variance, which hinders accuracy. Our attribute similarity matching mitigates this issue by aligning stable similarity matrices. We evaluate TAGSAM against six state-of-the-art baselines, where it showcases superior performance. For the same compressed size, TAGSAM improves upon the best-performing baseline by an average of 4.9% in accuracy. Furthermore, it maintains competitive training accuracy even when the TAG is condensed to just 1% size. Our code is available at https://github.com/SundayVHan/TAGSAM
MiCU: End-to-End Smart Home Command Understanding with Large Language Model
May 31, 2026Command understanding systems in smart home ecosystems can automate device control and substantially improve user experience. However, while they perform well on precise utterances (e.g., "turn on the bedroom light"), they struggle with ambiguous or misaligned commands (e.g., "make the bedroom cozy"). Large language models (LLMs) generalize well across various domains and can outperform traditional rule-based systems on such tasks, but their effectiveness is often constrained by scarce domain-specific data, insufficient task-specific adaptation, and high computational costs. In this paper, we propose an automated training data synthesis workflow using user logs and LLMs; then we build MiCU, a domain-specific LLM that excels at command understanding. Specifically, we employ curriculum learning to inject domain knowledge into the base LLM, then we enhance its reasoning ability via cold-start training combined with reinforcement learning (RL) guided by domain-specific thinking rules. Additionally, we introduce a token compression technique that condenses device description into a single special token, substantially reducing inference overhead and enabling \model-fast, an efficient variant optimized for long inputs. Extensive experiments show that MiCU significantly outperforms baselines, with an average accuracy gain of 20.01% across all device categories. We have deployed MiCU in the Xiaomi Home app, receiving approximately 1.7 million page views per day. Production evaluations show that MiCU reduces user correction rate by 1.57% and increases human audited accuracy by 32.05%. Our data and code are available at https://github.com/xiaomi-research/iot_spec_llm
Lakestream: A Consistent and Brokerless Data Plane for Large Foundation Model Training
May 11, 2026Modern Large Foundation Model (LFM) training has transformed the data pipeline from a static ingestion layer into a dynamic component that must co-evolve with the training process. Existing systems are ill-equipped: colocated dataloaders offer no failure isolation, while message queue-based disaggregated dataloaders operate on a record/offset abstraction that cannot express the batch-level semantics required by distributed training. We present Lakestream, a brokerless, object-store-native training data plane with three key properties. First, it introduces the Transactional Global Batch (TGB), which builds on lakehouse-style ACID storage semantics and extends them with training-specific consistency, including atomic all-rank batch visibility, a globally ordered step sequence, checkpoint-aligned lifecycle management, and end-to-end exactly-once recovery. Second, it realizes recovery and retention directly in the storage layer, by inlining producer state in the manifest and tying reclamation to distributed checkpoint state. Third, its Decentralized Adaptive Commit (DAC) algorithm sustains stable ingestion throughput as the manifest grows, without any inter-producer communication. Evaluations on large-scale multimodal pre-training and SFT workloads using 64 GPUs show that Lakestream outperforms colocated dataloader throughput while providing full failure isolation, outperforms Apache Kafka in ingestion throughput, and achieves lower consumer read latency than Kafka.
Unified Value Alignment for Generative Recommendation in Industrial Advertising
May 07, 2026Generative Recommendation (GR) reformulates recommendation as a next-token generation problem and has shown promise in industrial applications. However, extending GR to industrial advertising is non-trivial because the system must optimize not only user interest but also commercial value. Existing GR pipelines remain largely semantics-centric, making it difficult to align value signals across tokenization, decoding, and online serving. To address this issue, we propose UniVA, a Unified Value Alignment framework for advertising recommendation. We first introduce a Commercial SID tokenizer that injects value-related attributes into SID construction, yielding value-discriminative item representations. We then develop a Generation-as-Ranking SID Decoder jointly optimized by supervised learning and eCPM-aware reinforcement learning, which fuses value scores into next-item SID generation to perform generation and ranking in one decoding process. Finally, we design a value-guided personalized beam search that reuses generation-as-ranking logits as online value guidance and applies a personalized trie tree to constrain decoding to request-valid SID paths. Experiments on the Tencent WeChat Channels advertising platform show that UniVA achieves a 37.04\% improvement in offline Hit Rate@100 over the baseline and a 1.5\% GMV lift in online A/B tests.
Efficient Serving for Dynamic Agent Workflows with Prediction-based KV-Cache Management
May 07, 2026LLM-based workflows compose specialized agents to execute complex tasks, and these agents usually share substantial context, allowing KV-Cache reuse to save computation. Existing approaches either manage KV-Cache at agent level and fail to exploit the reuse opportunities within workflows, or manage cache at the workflow level but assume that each workflow calls a static sequence of agents. However, practical workflows are typically dynamic, where the sequence of invoked agents and thus induced cache reuse opportunities depend on the context of each task. To serve such dynamic workflows efficiently, we build a system dubbed PBKV (\textbf{P}rediction-\textbf{B}ased \textbf{KV}-Cache Management). For each workflow, PBKV predicts the agent invocations in several future steps by fusing the guidance from historical workflows and context of the target workflow. Based on the predictions, PBKV estimates the reuse potential of cache entries and keeps the high-potential entries in GPU memory. To be robust to prediction errors, PBKV utilizes the predictions conservatively during both cache eviction and prefetching. Experiments on three workflow benchmarks show that PBKV achieves up to $1.85\times$ speedup over LRU on dynamic workflows, and up to $1.26\times$ speedup over the SOTA baseline KVFlow on the static workflow.
MTServe: Efficient Serving for Generative Recommendation Models with Hierarchical Caches
Apr 24, 2026Generative recommendation (GR) offers superior modeling capabilities but suffers from prohibitive inference costs due to the repeated encoding of long user histories. While cross-request Key-Value (KV) cache reuse presents a significant optimization opportunity, the massive scale of individual user states creates a storage explosion that far exceeds physical GPU limits. We propose MTServe, a hierarchical cache management system that virtualizes GPU memory by leveraging host RAM as a scalable backup store. To bridge the I/O gap between tiers, MTServe introduces a suite of system-level optimizations, including a hybrid storage layout, an asynchronous data transfer pipeline, and a locality-driven replacement policy. On both public and production datasets, MTServe delivers up to 3.1* speedup while maintaining near-perfect hit ratios (>98.5%).
Scheduling LLM Inference with Uncertainty-Aware Output Length Predictions
Apr 01, 2026To schedule LLM inference, the \textit{shortest job first} (SJF) principle is favorable by prioritizing requests with short output lengths to avoid head-of-line (HOL) blocking. Existing methods usually predict a single output length for each request to facilitate scheduling. We argue that such a \textit{point estimate} does not match the \textit{stochastic} decoding process of LLM inference, where output length is \textit{uncertain} by nature and determined by when the end-of-sequence (EOS) token is sampled. Hence, the output length of each request should be fitted with a distribution rather than a single value. With an in-depth analysis of empirical data and the stochastic decoding process, we observe that output length follows a heavy-tailed distribution and can be fitted with the log-t distribution. On this basis, we propose a simple metric called Tail Inflated Expectation (TIE) to replace the output length in SJF scheduling, which adjusts the expectation of a log-t distribution with its tail probabilities to account for the risk that a request generates long outputs. To evaluate our TIE scheduler, we compare it with three strong baselines, and the results show that TIE reduces the per-token latency by $2.31\times$ for online inference and improves throughput by $1.42\times$ for offline data generation.
End-to-End Semantic ID Generation for Generative Advertisement Recommendation
Feb 12, 2026Generative Recommendation (GR) has excelled by framing recommendation as next-token prediction. This paradigm relies on Semantic IDs (SIDs) to tokenize large-scale items into discrete sequences. Existing GR approaches predominantly generate SIDs via Residual Quantization (RQ), where items are encoded into embeddings and then quantized to discrete SIDs. However, this paradigm suffers from inherent limitations: 1) Objective misalignment and semantic degradation stemming from the two-stage compression; 2) Error accumulation inherent in the structure of RQ. To address these limitations, we propose UniSID, a Unified SID generation framework for generative advertisement recommendation. Specifically, we jointly optimize embeddings and SIDs in an end-to-end manner from raw advertising data, enabling semantic information to flow directly into the SID space and thus addressing the inherent limitations of the two-stage cascading compression paradigm. To capture fine-grained semantics, a multi-granularity contrastive learning strategy is introduced to align distinct items across SID levels. Finally, a summary-based ad reconstruction mechanism is proposed to encourage SIDs to capture high-level semantic information that is not explicitly present in advertising contexts. Experiments demonstrate that UniSID consistently outperforms state-of-the-art SID generation methods, yielding up to a 4.62% improvement in Hit Rate metrics across downstream advertising scenarios compared to the strongest baseline.
DevPiolt: Operation Recommendation for IoT Devices at Xiaomi Home
Nov 18, 2025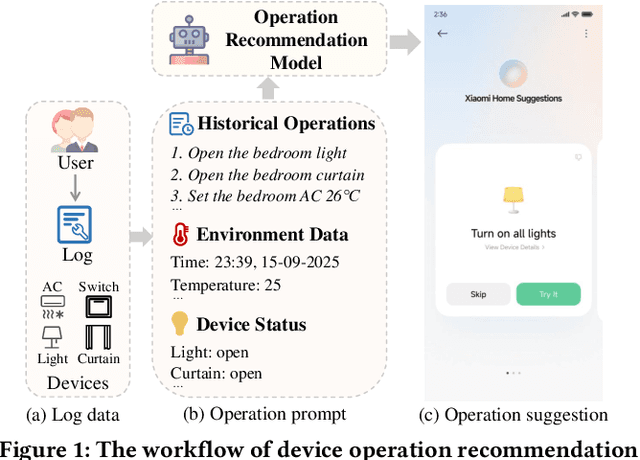
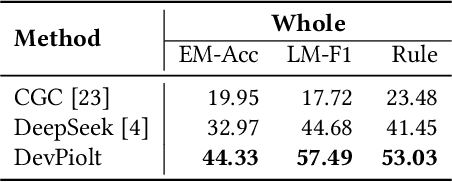
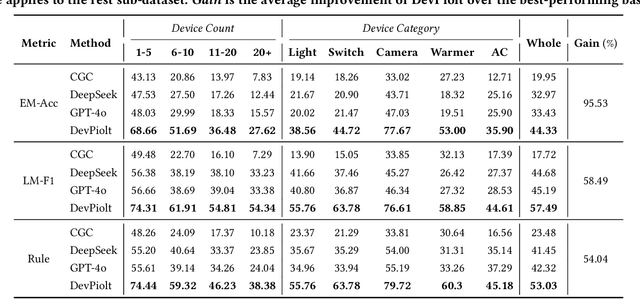
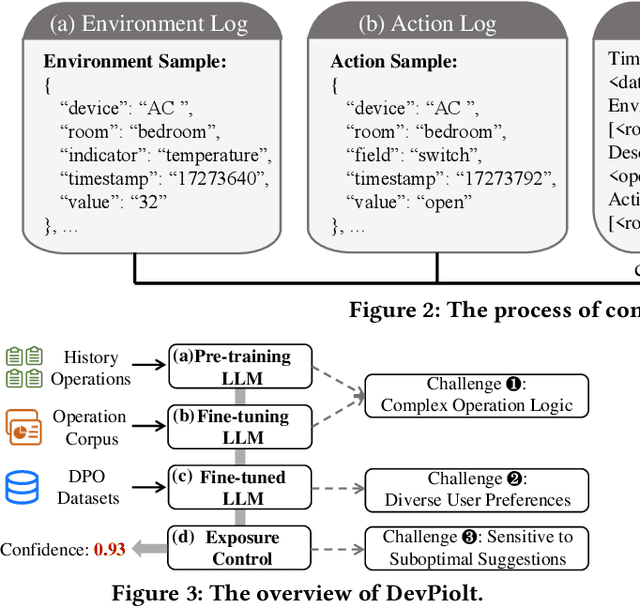
Operation recommendation for IoT devices refers to generating personalized device operations for users based on their context, such as historical operations, environment information, and device status. This task is crucial for enhancing user satisfaction and corporate profits. Existing recommendation models struggle with complex operation logic, diverse user preferences, and sensitive to suboptimal suggestions, limiting their applicability to IoT device operations. To address these issues, we propose DevPiolt, a LLM-based recommendation model for IoT device operations. Specifically, we first equip the LLM with fundamental domain knowledge of IoT operations via continual pre-training and multi-task fine-tuning. Then, we employ direct preference optimization to align the fine-tuned LLM with specific user preferences. Finally, we design a confidence-based exposure control mechanism to avoid negative user experiences from low-quality recommendations. Extensive experiments show that DevPiolt significantly outperforms baselines on all datasets, with an average improvement of 69.5% across all metrics. DevPiolt has been practically deployed in Xiaomi Home app for one quarter, providing daily operation recommendations to 255,000 users. Online experiment results indicate a 21.6% increase in unique visitor device coverage and a 29.1% increase in page view acceptance rates.
Compass: General Filtered Search across Vector and Structured Data
Oct 31, 2025The increasing prevalence of hybrid vector and relational data necessitates efficient, general support for queries that combine high-dimensional vector search with complex relational filtering. However, existing filtered search solutions are fundamentally limited by specialized indices, which restrict arbitrary filtering and hinder integration with general-purpose DBMSs. This work introduces \textsc{Compass}, a unified framework that enables general filtered search across vector and structured data without relying on new index designs. Compass leverages established index structures -- such as HNSW and IVF for vector attributes, and B+-trees for relational attributes -- implementing a principled cooperative query execution strategy that coordinates candidate generation and predicate evaluation across modalities. Uniquely, Compass maintains generality by allowing arbitrary conjunctions, disjunctions, and range predicates, while ensuring robustness even with highly-selective or multi-attribute filters. Comprehensive empirical evaluations demonstrate that Compass consistently outperforms NaviX, the only existing performant general framework, across diverse hybrid query workloads. It also matches the query throughput of specialized single-attribute indices in their favorite settings with only a single attribute involved, all while maintaining full generality and DBMS compatibility. Overall, Compass offers a practical and robust solution for achieving truly general filtered search in vector database systems.