 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicro-Act: Mitigate Knowledge Conflict in Question Answering via Actionable Self-Reasoning
Jun 05, 2025Retrieval-Augmented Generation (RAG) systems commonly suffer from Knowledge Conflicts, where retrieved external knowledge contradicts the inherent, parametric knowledge of large language models (LLMs). It adversely affects performance on downstream tasks such as question answering (QA). Existing approaches often attempt to mitigate conflicts by directly comparing two knowledge sources in a side-by-side manner, but this can overwhelm LLMs with extraneous or lengthy contexts, ultimately hindering their ability to identify and mitigate inconsistencies. To address this issue, we propose Micro-Act a framework with a hierarchical action space that automatically perceives context complexity and adaptively decomposes each knowledge source into a sequence of fine-grained comparisons. These comparisons are represented as actionable steps, enabling reasoning beyond the superficial context. Through extensive experiments on five benchmark datasets, Micro-Act consistently achieves significant increase in QA accuracy over state-of-the-art baselines across all 5 datasets and 3 conflict types, especially in temporal and semantic types where all baselines fail significantly. More importantly, Micro-Act exhibits robust performance on non-conflict questions simultaneously, highlighting its practical value in real-world RAG applications.
Before Generation, Align it! A Novel and Effective Strategy for Mitigating Hallucinations in Text-to-SQL Generation
May 24, 2024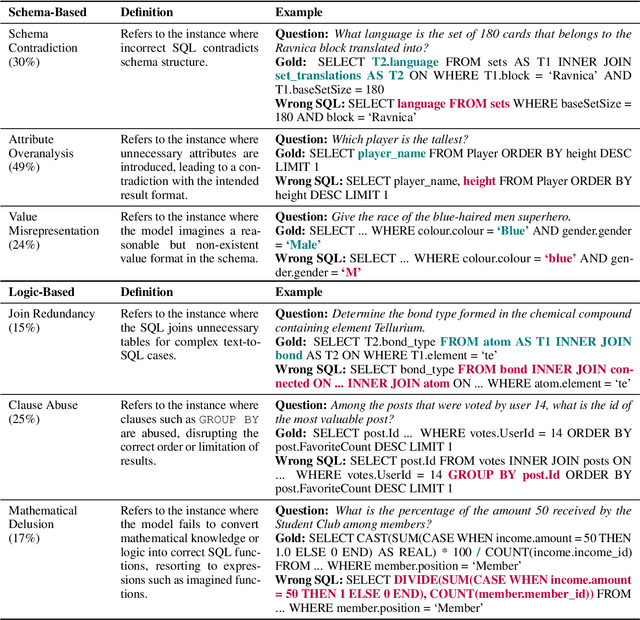
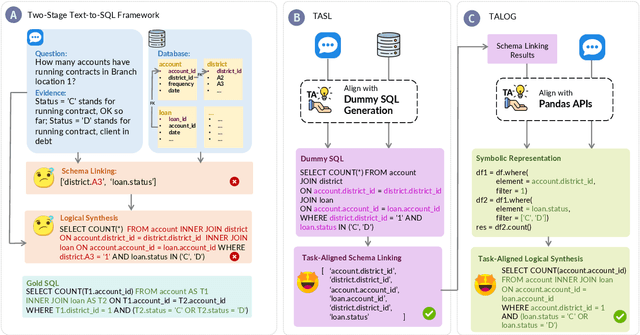
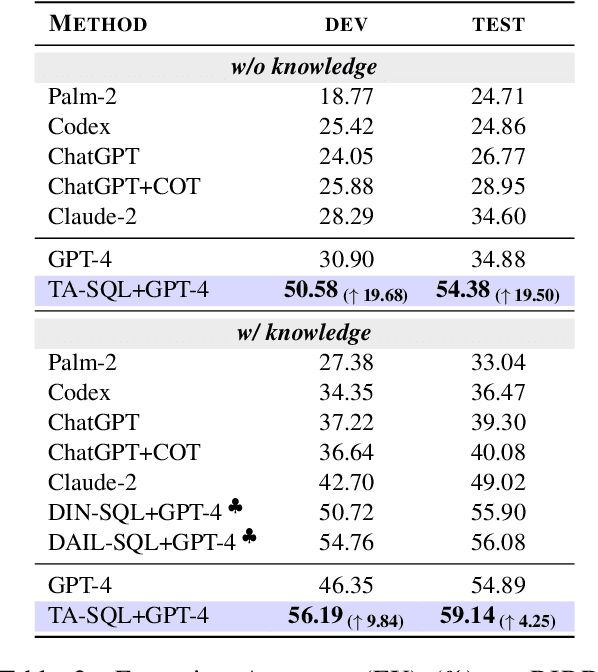
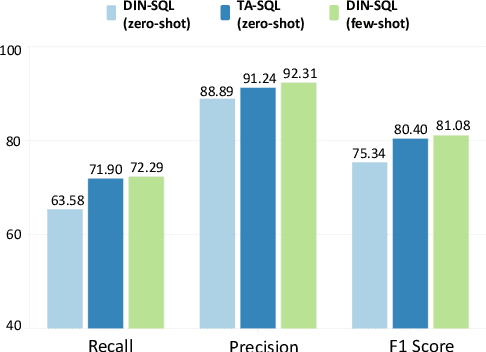
Large Language Models (LLMs) driven by In-Context Learning (ICL) have significantly improved the performance of text-to-SQL. Previous methods generally employ a two-stage reasoning framework, namely 1) schema linking and 2) logical synthesis, making the framework not only effective but also interpretable. Despite these advancements, the inherent bad nature of the generalization of LLMs often results in hallucinations, which limits the full potential of LLMs. In this work, we first identify and categorize the common types of hallucinations at each stage in text-to-SQL. We then introduce a novel strategy, Task Alignment (TA), designed to mitigate hallucinations at each stage. TA encourages LLMs to take advantage of experiences from similar tasks rather than starting the tasks from scratch. This can help LLMs reduce the burden of generalization, thereby mitigating hallucinations effectively. We further propose TA-SQL, a text-to-SQL framework based on this strategy. The experimental results and comprehensive analysis demonstrate the effectiveness and robustness of our framework. Specifically, it enhances the performance of the GPT-4 baseline by 21.23% relatively on BIRD dev and it yields significant improvements across six models and four mainstream, complex text-to-SQL benchmarks.
Tapilot-Crossing: Benchmarking and Evolving LLMs Towards Interactive Data Analysis Agents
Mar 08, 2024



Interactive Data Analysis, the collaboration between humans and LLM agents, enables real-time data exploration for informed decision-making. The challenges and costs of collecting realistic interactive logs for data analysis hinder the quantitative evaluation of Large Language Model (LLM) agents in this task. To mitigate this issue, we introduce Tapilot-Crossing, a new benchmark to evaluate LLM agents on interactive data analysis. Tapilot-Crossing contains 1024 interactions, covering 4 practical scenarios: Normal, Action, Private, and Private Action. Notably, Tapilot-Crossing is constructed by an economical multi-agent environment, Decision Company, with few human efforts. We evaluate popular and advanced LLM agents in Tapilot-Crossing, which underscores the challenges of interactive data analysis. Furthermore, we propose Adaptive Interaction Reflection (AIR), a self-generated reflection strategy that guides LLM agents to learn from successful history. Experiments demonstrate that Air can evolve LLMs into effective interactive data analysis agents, achieving a relative performance improvement of up to 44.5%.
Debiasing Recommendation with Personal Popularity
Feb 21, 2024



Global popularity (GP) bias is the phenomenon that popular items are recommended much more frequently than they should be, which goes against the goal of providing personalized recommendations and harms user experience and recommendation accuracy. Many methods have been proposed to reduce GP bias but they fail to notice the fundamental problem of GP, i.e., it considers popularity from a \textit{global} perspective of \textit{all users} and uses a single set of popular items, and thus cannot capture the interests of individual users. As such, we propose a user-aware version of item popularity named \textit{personal popularity} (PP), which identifies different popular items for each user by considering the users that share similar interests. As PP models the preferences of individual users, it naturally helps to produce personalized recommendations and mitigate GP bias. To integrate PP into recommendation, we design a general \textit{personal popularity aware counterfactual} (PPAC) framework, which adapts easily to existing recommendation models. In particular, PPAC recognizes that PP and GP have both direct and indirect effects on recommendations and controls direct effects with counterfactual inference techniques for unbiased recommendations. All codes and datasets are available at \url{https://github.com/Stevenn9981/PPAC}.
Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs
May 04, 2023



Text-to-SQL parsing, which aims at converting natural language instructions into executable SQLs, has gained increasing attention in recent years. In particular, Codex and ChatGPT have shown impressive results in this task. However, most of the prevalent benchmarks, i.e., Spider, and WikiSQL, focus on database schema with few rows of database contents leaving the gap between academic study and real-world applications. To mitigate this gap, we present Bird, a big benchmark for large-scale database grounded in text-to-SQL tasks, containing 12,751 pairs of text-to-SQL data and 95 databases with a total size of 33.4 GB, spanning 37 professional domains. Our emphasis on database values highlights the new challenges of dirty database contents, external knowledge between NL questions and database contents, and SQL efficiency, particularly in the context of massive databases. To solve these problems, text-to-SQL models must feature database value comprehension in addition to semantic parsing. The experimental results demonstrate the significance of database values in generating accurate text-to-SQLs for big databases. Furthermore, even the most effective text-to-SQL models, i.e. ChatGPT, only achieves 40.08% in execution accuracy, which is still far from the human result of 92.96%, proving that challenges still stand. Besides, we also provide an efficiency analysis to offer insights into generating text-to-efficient-SQLs that are beneficial to industries. We believe that BIRD will contribute to advancing real-world applications of text-to-SQL research. The leaderboard and source code are available: https://bird-bench.github.io/.
Graphix-T5: Mixing Pre-Trained Transformers with Graph-Aware Layers for Text-to-SQL Parsing
Jan 18, 2023



The task of text-to-SQL parsing, which aims at converting natural language questions into executable SQL queries, has garnered increasing attention in recent years, as it can assist end users in efficiently extracting vital information from databases without the need for technical background. One of the major challenges in text-to-SQL parsing is domain generalization, i.e., how to generalize well to unseen databases. Recently, the pre-trained text-to-text transformer model, namely T5, though not specialized for text-to-SQL parsing, has achieved state-of-the-art performance on standard benchmarks targeting domain generalization. In this work, we explore ways to further augment the pre-trained T5 model with specialized components for text-to-SQL parsing. Such components are expected to introduce structural inductive bias into text-to-SQL parsers thus improving model's capacity on (potentially multi-hop) reasoning, which is critical for generating structure-rich SQLs. To this end, we propose a new architecture GRAPHIX-T5, a mixed model with the standard pre-trained transformer model augmented by some specially-designed graph-aware layers. Extensive experiments and analysis demonstrate the effectiveness of GRAPHIX-T5 across four text-to-SQL benchmarks: SPIDER, SYN, REALISTIC and DK. GRAPHIX-T5 surpass all other T5-based parsers with a significant margin, achieving new state-of-the-art performance. Notably, GRAPHIX-T5-large reach performance superior to the original T5-large by 5.7% on exact match (EM) accuracy and 6.6% on execution accuracy (EX). This even outperforms the T5-3B by 1.2% on EM and 1.5% on EX.
Muskits: an End-to-End Music Processing Toolkit for Singing Voice Synthesis
May 09, 2022



This paper introduces a new open-source platform named Muskits for end-to-end music processing, which mainly focuses on end-to-end singing voice synthesis (E2E-SVS). Muskits supports state-of-the-art SVS models, including RNN SVS, transformer SVS, and XiaoiceSing. The design of Muskits follows the style of widely-used speech processing toolkits, ESPnet and Kaldi, for data prepossessing, training, and recipe pipelines. To the best of our knowledge, this toolkit is the first platform that allows a fair and highly-reproducible comparison between several published works in SVS. In addition, we also demonstrate several advanced usages based on the toolkit functionalities, including multilingual training and transfer learning. This paper describes the major framework of Muskits, its functionalities, and experimental results in single-singer, multi-singer, multilingual, and transfer learning scenarios. The toolkit is publicly available at https://github.com/SJTMusicTeam/Muskits.
Reinforced Meta-path Selection for Recommendation on Heterogeneous Information Networks
Dec 28, 2021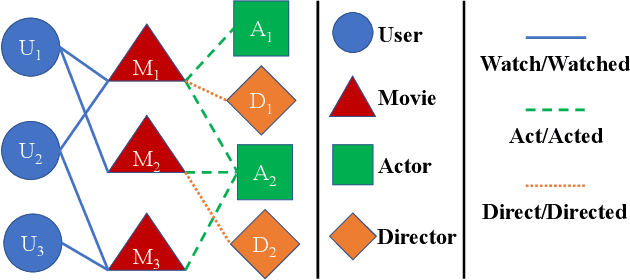
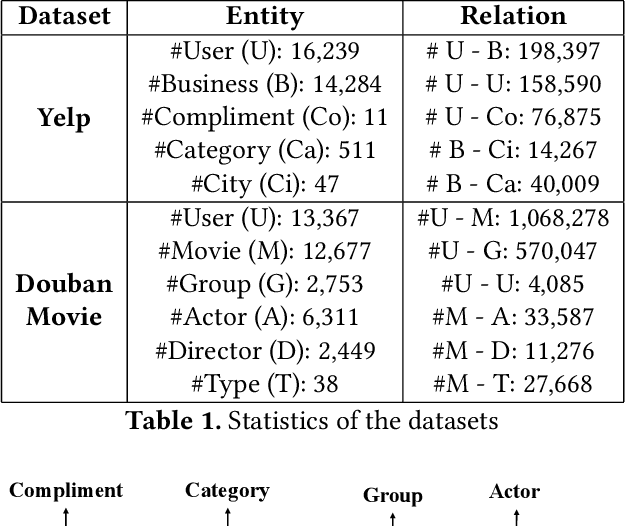
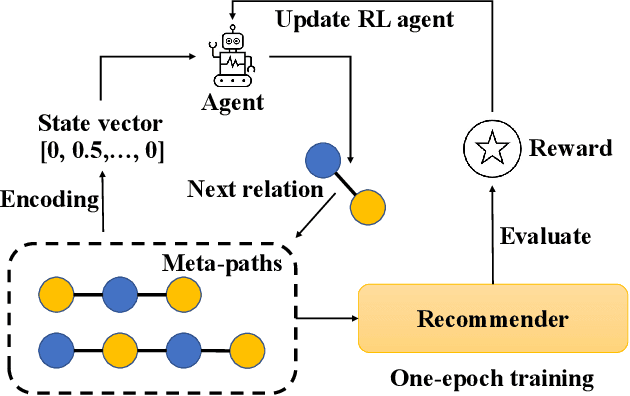
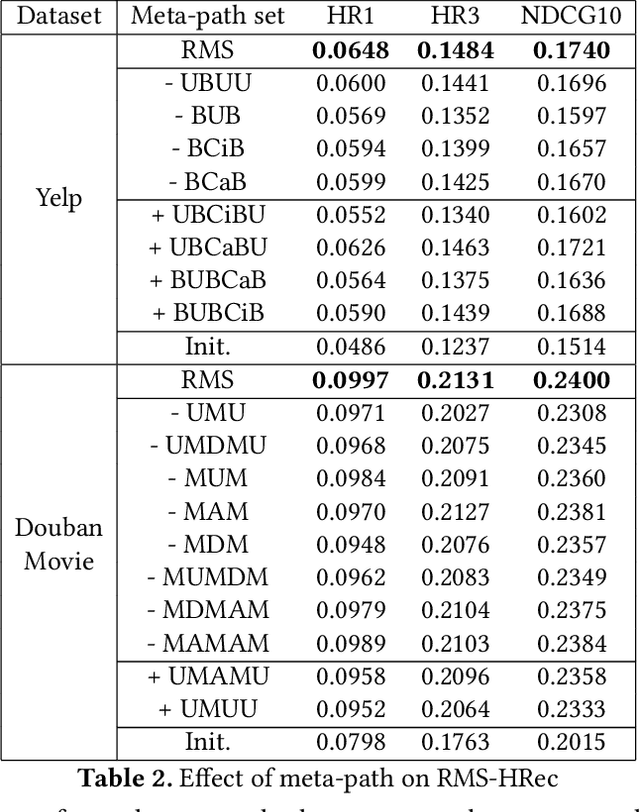
Heterogeneous Information Networks (HINs) capture complex relations among entities of various kinds and have been used extensively to improve the effectiveness of various data mining tasks, such as in recommender systems. Many existing HIN-based recommendation algorithms utilize hand-crafted meta-paths to extract semantic information from the networks. These algorithms rely on extensive domain knowledge with which the best set of meta-paths can be selected. For applications where the HINs are highly complex with numerous node and link types, the approach of hand-crafting a meta-path set is too tedious and error-prone. To tackle this problem, we propose the Reinforcement learning-based Meta-path Selection (RMS) framework to select effective meta-paths and to incorporate them into existing meta-path-based recommenders. To identify high-quality meta-paths, RMS trains a reinforcement learning (RL) based policy network(agent), which gets rewards from the performance on the downstream recommendation tasks. We design a HIN-based recommendation model, HRec, that effectively uses the meta-path information. We further integrate HRec with RMS and derive our recommendation solution, RMS-HRec, that automatically utilizes the effective meta-paths. Experiments on real datasets show that our algorithm can significantly improve the performance of recommendation models by capturing important meta-paths automatically.
Sequence-to-sequence Singing Voice Synthesis with Perceptual Entropy Loss
Oct 22, 2020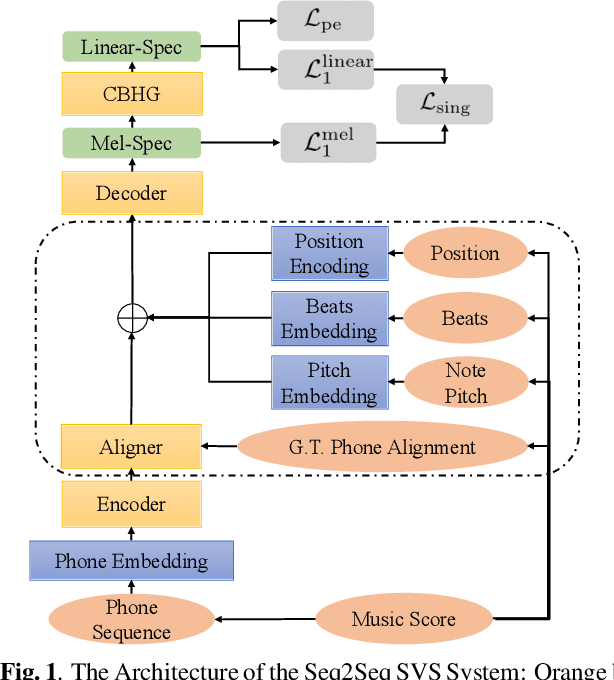
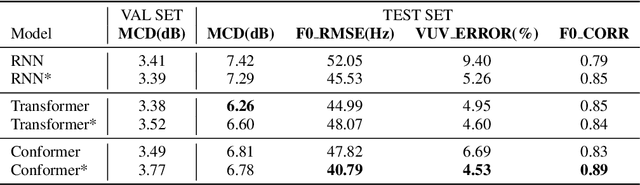
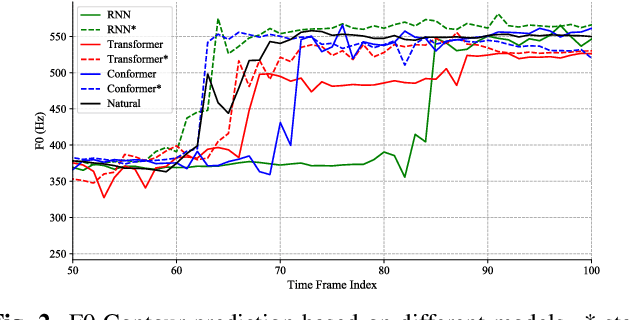
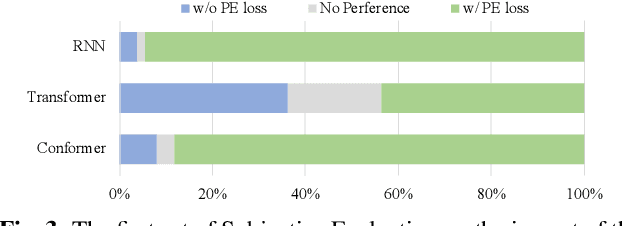
The neural network (NN) based singing voice synthesis (SVS) systems require sufficient data to train well. However, due to high data acquisition and annotation cost, we often encounter data limitation problem in building SVS systems. The NN based models are prone to over-fitting due to data scarcity. In this work, we propose a Perceptual Entropy (PE) loss derived from a psycho-acoustic hearing model to regularize the network. With a one-hour open-source singing voice database, we explore the impact of the PE loss on various mainstream sequence-to-sequence models, including the RNN-based model, transformer-based model, and conformer-based model. Our experiments show that the PE loss can mitigate the over-fitting problem and significantly improve the synthesized singing quality reflected in objective and subjective evaluations. Furthermore, incorporating the PE loss in model training is shown to help the F0-contour and high-frequency-band spectrum prediction.