 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPLA: Block Sparse Plus Linear Attention for Long Context Modeling
Jan 29, 2026Block-wise sparse attention offers significant efficiency gains for long-context modeling, yet existing methods often suffer from low selection fidelity and cumulative contextual loss by completely discarding unselected blocks. To address these limitations, we introduce Sparse Plus Linear Attention (SPLA), a framework that utilizes a selection metric derived from second-order Taylor expansions to accurately identify relevant blocks for exact attention. Instead of discarding the remaining "long tail," SPLA compresses unselected blocks into a compact recurrent state via a residual linear attention (RLA) module. Crucially, to avoid IO overhead, we derive an optimized subtraction-based formulation for RLA -- calculating the residual as the difference between global and selected linear attention -- ensuring that unselected blocks are never explicitly accessed during inference. Our experiments demonstrate that SPLA closes the performance gap in continual pretraining, surpassing dense attention models on long-context benchmarks like RULER while maintaining competitive general knowledge and reasoning capabilities.
RATTENTION: Towards the Minimal Sliding Window Size in Local-Global Attention Models
Jun 18, 2025Local-global attention models have recently emerged as compelling alternatives to standard Transformers, promising improvements in both training and inference efficiency. However, the crucial choice of window size presents a Pareto tradeoff: larger windows maintain performance akin to full attention but offer minimal efficiency gains in short-context scenarios, while smaller windows can lead to performance degradation. Current models, such as Gemma2 and Mistral, adopt conservative window sizes (e.g., 4096 out of an 8192 pretraining length) to preserve performance. This work investigates strategies to shift this Pareto frontier, enabling local-global models to achieve efficiency gains even in short-context regimes. Our core motivation is to address the intrinsic limitation of local attention -- its complete disregard for tokens outside the defined window. We explore RATTENTION, a variant of local attention integrated with a specialized linear attention mechanism designed to capture information from these out-of-window tokens. Pretraining experiments at the 3B and 12B scales demonstrate that RATTENTION achieves a superior Pareto tradeoff between performance and efficiency. As a sweet spot, RATTENTION with a window size of just 512 consistently matches the performance of full-attention models across diverse settings. Furthermore, the recurrent nature inherent in the linear attention component of RATTENTION contributes to enhanced long-context performance, as validated on the RULER benchmark. Crucially, these improvements do not compromise training efficiency; thanks to a specialized kernel implementation and the reduced window size, RATTENTION maintains training speeds comparable to existing state-of-the-art approaches.
Gated Slot Attention for Efficient Linear-Time Sequence Modeling
Sep 11, 2024



Linear attention Transformers and their gated variants, celebrated for enabling parallel training and efficient recurrent inference, still fall short in recall-intensive tasks compared to traditional Transformers and demand significant resources for training from scratch. This paper introduces Gated Slot Attention (GSA), which enhances Attention with Bounded-memory-Control (ABC) by incorporating a gating mechanism inspired by Gated Linear Attention (GLA). Essentially, GSA comprises a two-layer GLA linked via softmax, utilizing context-aware memory reading and adaptive forgetting to improve memory capacity while maintaining compact recurrent state size. This design greatly enhances both training and inference efficiency through GLA's hardware-efficient training algorithm and reduced state size. Additionally, retaining the softmax operation is particularly beneficial in "finetuning pretrained Transformers to RNNs" (T2R) settings, reducing the need for extensive training from scratch. Extensive experiments confirm GSA's superior performance in scenarios requiring in-context recall and in T2R settings.
MR-BEN: A Comprehensive Meta-Reasoning Benchmark for Large Language Models
Jun 20, 2024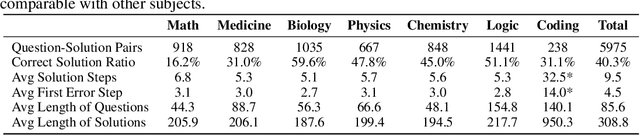
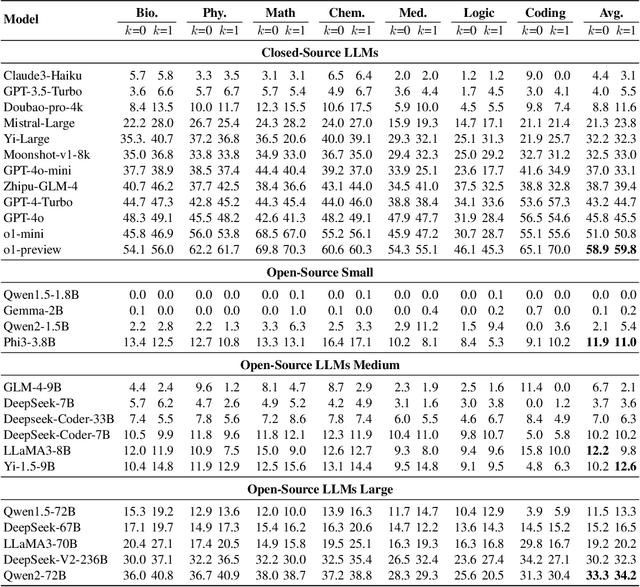
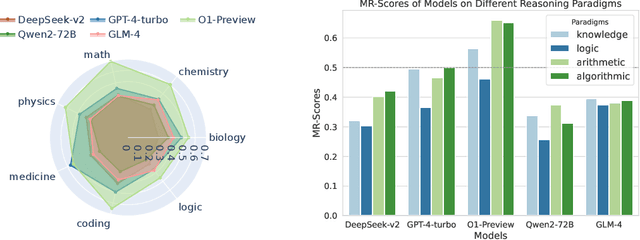
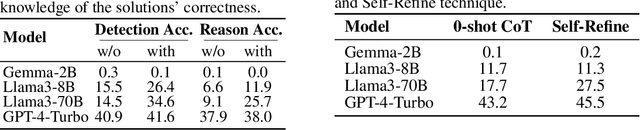
Large language models (LLMs) have shown increasing capability in problem-solving and decision-making, largely based on the step-by-step chain-of-thought reasoning processes. However, it has been increasingly challenging to evaluate the reasoning capability of LLMs. Concretely, existing outcome-based benchmarks begin to saturate and become less sufficient to monitor the progress. To this end, we present a process-based benchmark MR-BEN that demands a meta reasoning skill, where LMs are asked to locate and analyse potential errors in automatically generated reasoning steps. MR-BEN is a comprehensive benchmark comprising 5,975 questions collected from human experts, covering various subjects such as physics, chemistry, logic, coding, and more. Through our designed metrics for assessing meta-reasoning on this benchmark, we identify interesting limitations and weaknesses of current LLMs (open-source and closed-source models). For example, open-source models are seemingly comparable to GPT-4 on outcome-based benchmarks, but they lag far behind on our benchmark, revealing the underlying reasoning capability gap between them. Our dataset and codes are available on https://randolph-zeng.github.io/Mr-Ben.github.io/.
Parallelizing Linear Transformers with the Delta Rule over Sequence Length
Jun 10, 2024



Transformers with linear attention (i.e., linear transformers) and state-space models have recently been suggested as a viable linear-time alternative to transformers with softmax attention. However, these models still underperform transformers especially on tasks that require in-context retrieval. While more expressive variants of linear transformers which replace the additive outer-product update in linear transformers with the delta rule have been found to be more effective at associative recall, existing algorithms for training such models do not parallelize over sequence length and are thus inefficient to train on modern hardware. This work describes a hardware-efficient algorithm for training linear transformers with the delta rule, which exploits a memory-efficient representation for computing products of Householder matrices. This algorithm allows us to scale up DeltaNet to standard language modeling settings. We train a 1.3B model for 100B tokens and find that it outperforms recent linear-time baselines such as Mamba and GLA in terms of perplexity and zero-shot performance on downstream tasks (including on tasks that focus on recall). We also experiment with two hybrid models which combine DeltaNet layers with (1) sliding-window attention layers every other layer or (2) two global attention layers, and find that these hybrid models outperform strong transformer baselines.
Language Model Evolution: An Iterated Learning Perspective
Apr 04, 2024

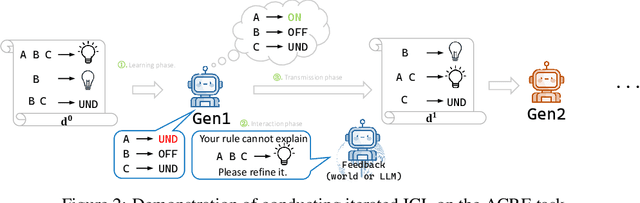

With the widespread adoption of Large Language Models (LLMs), the prevalence of iterative interactions among these models is anticipated to increase. Notably, recent advancements in multi-round self-improving methods allow LLMs to generate new examples for training subsequent models. At the same time, multi-agent LLM systems, involving automated interactions among agents, are also increasing in prominence. Thus, in both short and long terms, LLMs may actively engage in an evolutionary process. We draw parallels between the behavior of LLMs and the evolution of human culture, as the latter has been extensively studied by cognitive scientists for decades. Our approach involves leveraging Iterated Learning (IL), a Bayesian framework that elucidates how subtle biases are magnified during human cultural evolution, to explain some behaviors of LLMs. This paper outlines key characteristics of agents' behavior in the Bayesian-IL framework, including predictions that are supported by experimental verification with various LLMs. This theoretical framework could help to more effectively predict and guide the evolution of LLMs in desired directions.
Learning to Decode Collaboratively with Multiple Language Models
Mar 06, 2024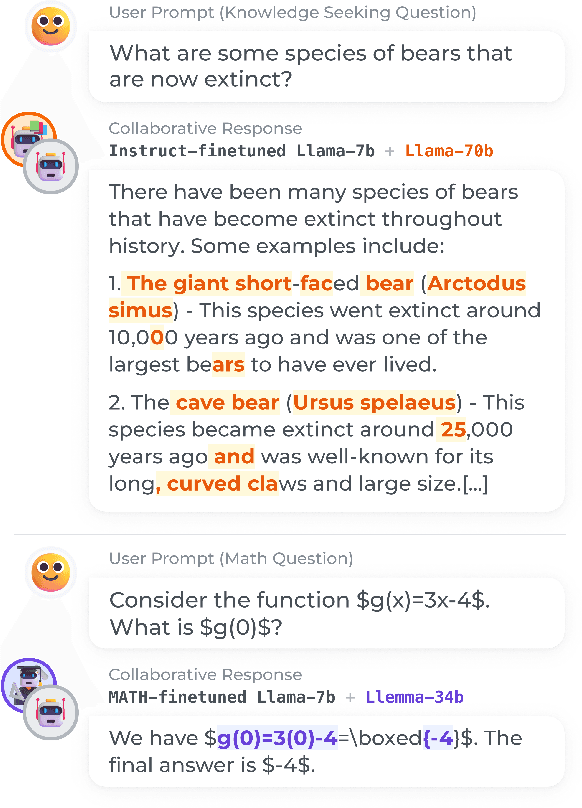
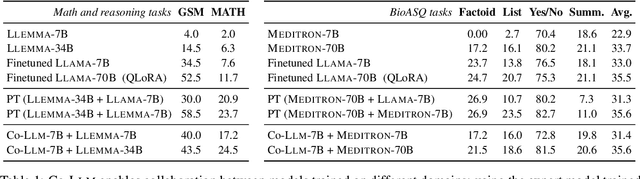


We propose a method to teach multiple large language models (LLM) to collaborate by interleaving their generations at the token level. We model the decision of which LLM generates the next token as a latent variable. By optimizing the marginal likelihood of a training set under our latent variable model, the base LLM automatically learns when to generate itself and when to call on one of the ``assistant'' language models to generate, all without direct supervision. Token-level collaboration during decoding allows for a fusion of each model's expertise in a manner tailored to the specific task at hand. Our collaborative decoding is especially useful in cross-domain settings where a generalist base LLM learns to invoke domain expert models. On instruction-following, domain-specific QA, and reasoning tasks, we show that the performance of the joint system exceeds that of the individual models. Through qualitative analysis of the learned latent decisions, we show models trained with our method exhibit several interesting collaboration patterns, e.g., template-filling. Our code is available at https://github.com/clinicalml/co-llm.
In-Context Language Learning: Architectures and Algorithms
Jan 30, 2024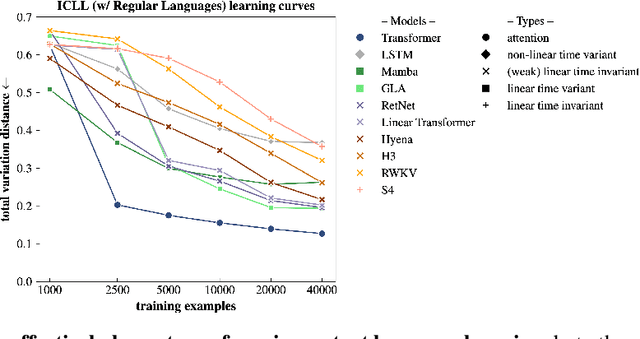



Large-scale neural language models exhibit a remarkable capacity for in-context learning (ICL): they can infer novel functions from datasets provided as input. Most of our current understanding of when and how ICL arises comes from LMs trained on extremely simple learning problems like linear regression and associative recall. There remains a significant gap between these model problems and the "real" ICL exhibited by LMs trained on large text corpora, which involves not just retrieval and function approximation but free-form generation of language and other structured outputs. In this paper, we study ICL through the lens of a new family of model problems we term in context language learning (ICLL). In ICLL, LMs are presented with a set of strings from a formal language, and must generate additional strings from the same language. We focus on in-context learning of regular languages generated by random finite automata. We evaluate a diverse set of neural sequence models (including several RNNs, Transformers, and state-space model variants) on regular ICLL tasks, aiming to answer three questions: (1) Which model classes are empirically capable of ICLL? (2) What algorithmic solutions do successful models implement to perform ICLL? (3) What architectural changes can improve ICLL in less performant models? We first show that Transformers significantly outperform neural sequence models with recurrent or convolutional representations on ICLL tasks. Next, we provide evidence that their ability to do so relies on specialized "n-gram heads" (higher-order variants of induction heads) that compute input-conditional next-token distributions. Finally, we show that hard-wiring these heads into neural models improves performance not just on ICLL, but natural language modeling -- improving the perplexity of 340M-parameter models by up to 1.14 points (6.7%) on the SlimPajama dataset.
Structured Code Representations Enable Data-Efficient Adaptation of Code Language Models
Jan 19, 2024


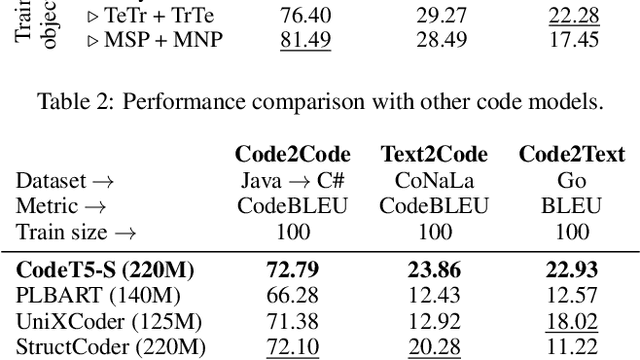
Current language models tailored for code tasks often adopt the pre-training-then-fine-tuning paradigm from natural language processing, modeling source code as plain text. This approach, however, overlooks the unambiguous structures inherent in programming languages. In this work, we explore data-efficient adaptation of pre-trained code models by further pre-training and fine-tuning them with program structures. Specifically, we represent programs as parse trees -- also known as concrete syntax trees (CSTs) -- and adapt pre-trained models on serialized CSTs. Although the models that we adapt have been pre-trained only on the surface form of programs, we find that a small amount of continual pre-training and fine-tuning on CSTs without changing the model architecture yields improvements over the baseline approach across various code tasks. The improvements are found to be particularly significant when there are limited training examples, demonstrating the effectiveness of integrating program structures with plain-text representation even when working with backbone models that have not been pre-trained with structures.
Gated Linear Attention Transformers with Hardware-Efficient Training
Dec 24, 2023



Transformers with linear attention allow for efficient parallel training but can simultaneously be formulated as an RNN with 2D (matrix-valued) hidden states, thus enjoying linear (with respect to output length) inference complexity. Recent works such as RetNet (Sun et al., 2023) and TransNormerLLM (Qin et al., 2023a) observe that adding a global decay term to the additive RNN update rule greatly improves performance, sometimes outperforming standard Transformers with softmax attention when trained at scale. In this work we show that adding a data-dependent gating mechanism further improves performance. We derive a parallel form of this gated linear attention layer that enables efficient training. However, a straightforward, numerically stable implementation of this parallel form requires generalized matrix multiplications in log-space for numerical stability, and thus cannot take advantage of tensor cores on modern GPUs which are optimized for standard matrix multiplications. We develop a hardware-efficient version of the parallel form that can still make use of tensor cores through block-parallel computations over sequence chunks. Experiments on moderate-scale language modeling (340M-parameter models trained on 15B tokens, 1.3B-parameter models trained on 100B tokens) show that gated linear attention (GLA) Transformers perform competitively against a strong LLaMA-architecture Transformer baseline (Touvron et al., 2023) as well as Mamba (Gu & Dao, 2023), a recently introduced state-space model with a data-dependent state transition mechanism. For training speed, our Triton-based implementation performs comparably to CUDA-optimized FlashAttention-2 (Dao, 2023) under the regular 2048 training length setting, while outperforming FlashAttention-2 when training on longer sequences beyond 4096.