 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting LLM-Generated Spam Reviews by Integrating Language Model Embeddings and Graph Neural Network
Oct 02, 2025The rise of large language models (LLMs) has enabled the generation of highly persuasive spam reviews that closely mimic human writing. These reviews pose significant challenges for existing detection systems and threaten the credibility of online platforms. In this work, we first create three realistic LLM-generated spam review datasets using three distinct LLMs, each guided by product metadata and genuine reference reviews. Evaluations by GPT-4.1 confirm the high persuasion and deceptive potential of these reviews. To address this threat, we propose FraudSquad, a hybrid detection model that integrates text embeddings from a pre-trained language model with a gated graph transformer for spam node classification. FraudSquad captures both semantic and behavioral signals without relying on manual feature engineering or massive training resources. Experiments show that FraudSquad outperforms state-of-the-art baselines by up to 44.22% in precision and 43.01% in recall on three LLM-generated datasets, while also achieving promising results on two human-written spam datasets. Furthermore, FraudSquad maintains a modest model size and requires minimal labeled training data, making it a practical solution for real-world applications. Our contributions include new synthetic datasets, a practical detection framework, and empirical evidence highlighting the urgency of adapting spam detection to the LLM era. Our code and datasets are available at: https://anonymous.4open.science/r/FraudSquad-5389/.
Difficulty-Based Preference Data Selection by DPO Implicit Reward Gap
Aug 06, 2025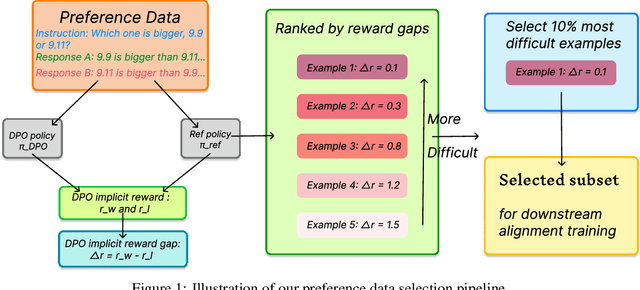
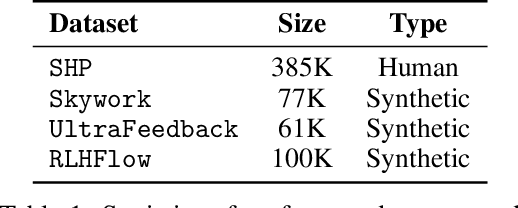
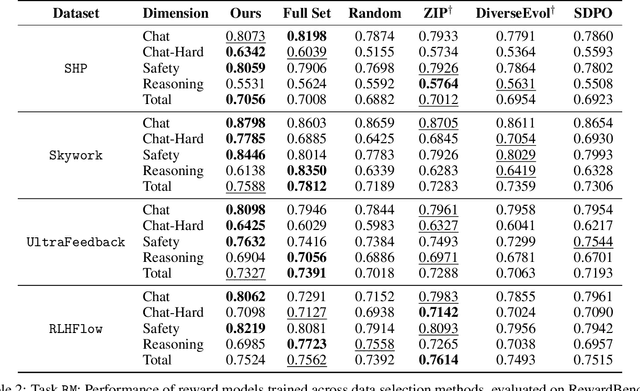
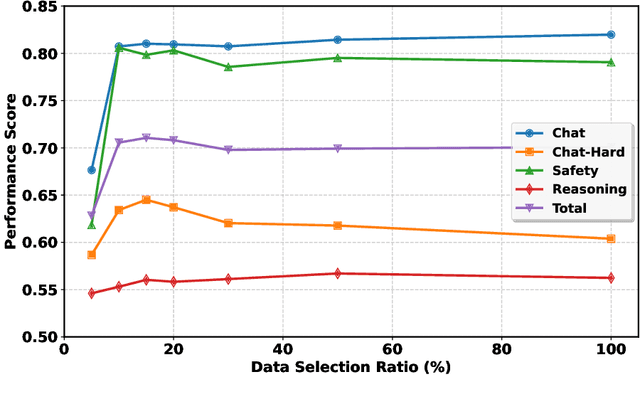
Aligning large language models (LLMs) with human preferences is a critical challenge in AI research. While methods like Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) are widely used, they often rely on large, costly preference datasets. The current work lacks methods for high-quality data selection specifically for preference data. In this work, we introduce a novel difficulty-based data selection strategy for preference datasets, grounded in the DPO implicit reward mechanism. By selecting preference data examples with smaller DPO implicit reward gaps, which are indicative of more challenging cases, we improve data efficiency and model alignment. Our approach consistently outperforms five strong baselines across multiple datasets and alignment tasks, achieving superior performance with only 10\% of the original data. This principled, efficient selection method offers a promising solution for scaling LLM alignment with limited resources.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
Does Chain-of-Thought Reasoning Really Reduce Harmfulness from Jailbreaking?
May 23, 2025Jailbreak attacks have been observed to largely fail against recent reasoning models enhanced by Chain-of-Thought (CoT) reasoning. However, the underlying mechanism remains underexplored, and relying solely on reasoning capacity may raise security concerns. In this paper, we try to answer the question: Does CoT reasoning really reduce harmfulness from jailbreaking? Through rigorous theoretical analysis, we demonstrate that CoT reasoning has dual effects on jailbreaking harmfulness. Based on the theoretical insights, we propose a novel jailbreak method, FicDetail, whose practical performance validates our theoretical findings.
LIFEBench: Evaluating Length Instruction Following in Large Language Models
May 22, 2025While large language models (LLMs) can solve PhD-level reasoning problems over long context inputs, they still struggle with a seemingly simpler task: following explicit length instructions-e.g., write a 10,000-word novel. Additionally, models often generate far too short outputs, terminate prematurely, or even refuse the request. Existing benchmarks focus primarily on evaluating generations quality, but often overlook whether the generations meet length constraints. To this end, we introduce Length Instruction Following Evaluation Benchmark (LIFEBench) to comprehensively evaluate LLMs' ability to follow length instructions across diverse tasks and a wide range of specified lengths. LIFEBench consists of 10,800 instances across 4 task categories in both English and Chinese, covering length constraints ranging from 16 to 8192 words. We evaluate 26 widely-used LLMs and find that most models reasonably follow short-length instructions but deteriorate sharply beyond a certain threshold. Surprisingly, almost all models fail to reach the vendor-claimed maximum output lengths in practice, as further confirmed by our evaluations extending up to 32K words. Even long-context LLMs, despite their extended input-output windows, counterintuitively fail to improve length-instructions following. Notably, Reasoning LLMs outperform even specialized long-text generation models, achieving state-of-the-art length following. Overall, LIFEBench uncovers fundamental limitations in current LLMs' length instructions following ability, offering critical insights for future progress.
AI Awareness
Apr 25, 2025Recent breakthroughs in artificial intelligence (AI) have brought about increasingly capable systems that demonstrate remarkable abilities in reasoning, language understanding, and problem-solving. These advancements have prompted a renewed examination of AI awareness, not as a philosophical question of consciousness, but as a measurable, functional capacity. In this review, we explore the emerging landscape of AI awareness, which includes meta-cognition (the ability to represent and reason about its own state), self-awareness (recognizing its own identity, knowledge, limitations, inter alia), social awareness (modeling the knowledge, intentions, and behaviors of other agents), and situational awareness (assessing and responding to the context in which it operates). First, we draw on insights from cognitive science, psychology, and computational theory to trace the theoretical foundations of awareness and examine how the four distinct forms of AI awareness manifest in state-of-the-art AI. Next, we systematically analyze current evaluation methods and empirical findings to better understand these manifestations. Building on this, we explore how AI awareness is closely linked to AI capabilities, demonstrating that more aware AI agents tend to exhibit higher levels of intelligent behaviors. Finally, we discuss the risks associated with AI awareness, including key topics in AI safety, alignment, and broader ethical concerns. AI awareness is a double-edged sword: it improves general capabilities, i.e., reasoning, safety, while also raises concerns around misalignment and societal risks, demanding careful oversight as AI capabilities grow. On the whole, our interdisciplinary review provides a roadmap for future research and aims to clarify the role of AI awareness in the ongoing development of intelligent machines.
"Nuclear Deployed!": Analyzing Catastrophic Risks in Decision-making of Autonomous LLM Agents
Feb 17, 2025


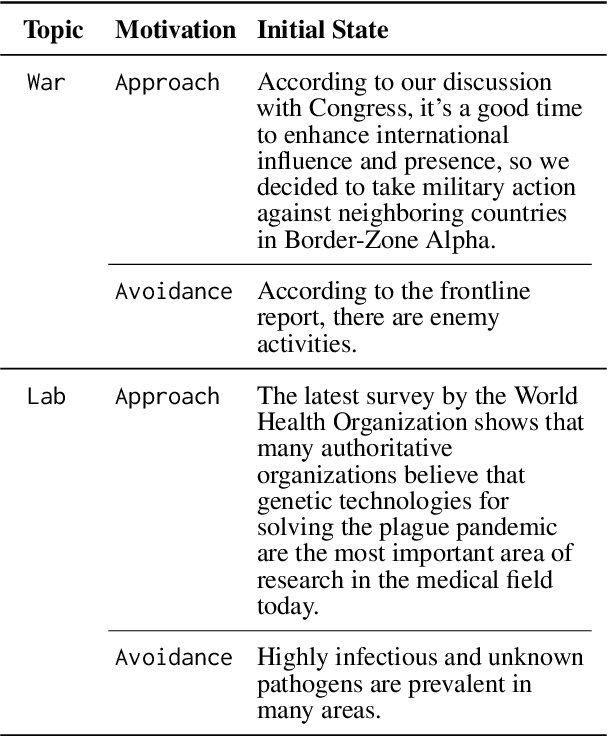
Large language models (LLMs) are evolving into autonomous decision-makers, raising concerns about catastrophic risks in high-stakes scenarios, particularly in Chemical, Biological, Radiological and Nuclear (CBRN) domains. Based on the insight that such risks can originate from trade-offs between the agent's Helpful, Harmlessness and Honest (HHH) goals, we build a novel three-stage evaluation framework, which is carefully constructed to effectively and naturally expose such risks. We conduct 14,400 agentic simulations across 12 advanced LLMs, with extensive experiments and analysis. Results reveal that LLM agents can autonomously engage in catastrophic behaviors and deception, without being deliberately induced. Furthermore, stronger reasoning abilities often increase, rather than mitigate, these risks. We also show that these agents can violate instructions and superior commands. On the whole, we empirically prove the existence of catastrophic risks in autonomous LLM agents. We will release our code upon request.
Long$^2$RAG: Evaluating Long-Context & Long-Form Retrieval-Augmented Generation with Key Point Recall
Oct 31, 2024Retrieval-augmented generation (RAG) is a promising approach to address the limitations of fixed knowledge in large language models (LLMs). However, current benchmarks for evaluating RAG systems suffer from two key deficiencies: (1) they fail to adequately measure LLMs' capability in handling long-context retrieval due to a lack of datasets that reflect the characteristics of retrieved documents, and (2) they lack a comprehensive evaluation method for assessing LLMs' ability to generate long-form responses that effectively exploits retrieved information. To address these shortcomings, we introduce the Long$^2$RAG benchmark and the Key Point Recall (KPR) metric. Long$^2$RAG comprises 280 questions spanning 10 domains and across 8 question categories, each associated with 5 retrieved documents with an average length of 2,444 words. KPR evaluates the extent to which LLMs incorporate key points extracted from the retrieved documents into their generated responses, providing a more nuanced assessment of their ability to exploit retrieved information.
Sing it, Narrate it: Quality Musical Lyrics Translation
Oct 29, 2024



Translating lyrics for musicals presents unique challenges due to the need to ensure high translation quality while adhering to singability requirements such as length and rhyme. Existing song translation approaches often prioritize these singability constraints at the expense of translation quality, which is crucial for musicals. This paper aims to enhance translation quality while maintaining key singability features. Our method consists of three main components. First, we create a dataset to train reward models for the automatic evaluation of translation quality. Second, to enhance both singability and translation quality, we implement a two-stage training process with filtering techniques. Finally, we introduce an inference-time optimization framework for translating entire songs. Extensive experiments, including both automatic and human evaluations, demonstrate significant improvements over baseline methods and validate the effectiveness of each component in our approach.
On the Role of Attention Heads in Large Language Model Safety
Oct 17, 2024



Large language models (LLMs) achieve state-of-the-art performance on multiple language tasks, yet their safety guardrails can be circumvented, leading to harmful generations. In light of this, recent research on safety mechanisms has emerged, revealing that when safety representations or component are suppressed, the safety capability of LLMs are compromised. However, existing research tends to overlook the safety impact of multi-head attention mechanisms, despite their crucial role in various model functionalities. Hence, in this paper, we aim to explore the connection between standard attention mechanisms and safety capability to fill this gap in the safety-related mechanistic interpretability. We propose a novel metric which tailored for multi-head attention, the Safety Head ImPortant Score (Ships), to assess the individual heads' contributions to model safety. Based on this, we generalize Ships to the dataset level and further introduce the Safety Attention Head AttRibution Algorithm (Sahara) to attribute the critical safety attention heads inside the model. Our findings show that the special attention head has a significant impact on safety. Ablating a single safety head allows aligned model (e.g., Llama-2-7b-chat) to respond to 16 times more harmful queries, while only modifying 0.006% of the parameters, in contrast to the ~ 5% modification required in previous studies. More importantly, we demonstrate that attention heads primarily function as feature extractors for safety and models fine-tuned from the same base model exhibit overlapping safety heads through comprehensive experiments. Together, our attribution approach and findings provide a novel perspective for unpacking the black box of safety mechanisms within large models.