 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlying in Clutter on Monocular RGB by Learning in 3D Radiance Fields with Domain Adaptation
Dec 19, 2025Modern autonomous navigation systems predominantly rely on lidar and depth cameras. However, a fundamental question remains: Can flying robots navigate in clutter using solely monocular RGB images? Given the prohibitive costs of real-world data collection, learning policies in simulation offers a promising path. Yet, deploying such policies directly in the physical world is hindered by the significant sim-to-real perception gap. Thus, we propose a framework that couples the photorealism of 3D Gaussian Splatting (3DGS) environments with Adversarial Domain Adaptation. By training in high-fidelity simulation while explicitly minimizing feature discrepancy, our method ensures the policy relies on domain-invariant cues. Experimental results demonstrate that our policy achieves robust zero-shot transfer to the physical world, enabling safe and agile flight in unstructured environments with varying illumination.
EfficientIML: Efficient High-Resolution Image Manipulation Localization
Sep 10, 2025With imaging devices delivering ever-higher resolutions and the emerging diffusion-based forgery methods, current detectors trained only on traditional datasets (with splicing, copy-moving and object removal forgeries) lack exposure to this new manipulation type. To address this, we propose a novel high-resolution SIF dataset of 1200+ diffusion-generated manipulations with semantically extracted masks. However, this also imposes a challenge on existing methods, as they face significant computational resource constraints due to their prohibitive computational complexities. Therefore, we propose a novel EfficientIML model with a lightweight, three-stage EfficientRWKV backbone. EfficientRWKV's hybrid state-space and attention network captures global context and local details in parallel, while a multi-scale supervision strategy enforces consistency across hierarchical predictions. Extensive evaluations on our dataset and standard benchmarks demonstrate that our approach outperforms ViT-based and other SOTA lightweight baselines in localization performance, FLOPs and inference speed, underscoring its suitability for real-time forensic applications.
Sing it, Narrate it: Quality Musical Lyrics Translation
Oct 29, 2024



Translating lyrics for musicals presents unique challenges due to the need to ensure high translation quality while adhering to singability requirements such as length and rhyme. Existing song translation approaches often prioritize these singability constraints at the expense of translation quality, which is crucial for musicals. This paper aims to enhance translation quality while maintaining key singability features. Our method consists of three main components. First, we create a dataset to train reward models for the automatic evaluation of translation quality. Second, to enhance both singability and translation quality, we implement a two-stage training process with filtering techniques. Finally, we introduce an inference-time optimization framework for translating entire songs. Extensive experiments, including both automatic and human evaluations, demonstrate significant improvements over baseline methods and validate the effectiveness of each component in our approach.
Harmon: Whole-Body Motion Generation of Humanoid Robots from Language Descriptions
Oct 16, 2024Humanoid robots, with their human-like embodiment, have the potential to integrate seamlessly into human environments. Critical to their coexistence and cooperation with humans is the ability to understand natural language communications and exhibit human-like behaviors. This work focuses on generating diverse whole-body motions for humanoid robots from language descriptions. We leverage human motion priors from extensive human motion datasets to initialize humanoid motions and employ the commonsense reasoning capabilities of Vision Language Models (VLMs) to edit and refine these motions. Our approach demonstrates the capability to produce natural, expressive, and text-aligned humanoid motions, validated through both simulated and real-world experiments. More videos can be found at https://ut-austin-rpl.github.io/Harmon/.
OKAMI: Teaching Humanoid Robots Manipulation Skills through Single Video Imitation
Oct 15, 2024



We study the problem of teaching humanoid robots manipulation skills by imitating from single video demonstrations. We introduce OKAMI, a method that generates a manipulation plan from a single RGB-D video and derives a policy for execution. At the heart of our approach is object-aware retargeting, which enables the humanoid robot to mimic the human motions in an RGB-D video while adjusting to different object locations during deployment. OKAMI uses open-world vision models to identify task-relevant objects and retarget the body motions and hand poses separately. Our experiments show that OKAMI achieves strong generalizations across varying visual and spatial conditions, outperforming the state-of-the-art baseline on open-world imitation from observation. Furthermore, OKAMI rollout trajectories are leveraged to train closed-loop visuomotor policies, which achieve an average success rate of 79.2% without the need for labor-intensive teleoperation. More videos can be found on our website https://ut-austin-rpl.github.io/OKAMI/.
Artificial Leviathan: Exploring Social Evolution of LLM Agents Through the Lens of Hobbesian Social Contract Theory
Jun 20, 2024



The emergence of Large Language Models (LLMs) and advancements in Artificial Intelligence (AI) offer an opportunity for computational social science research at scale. Building upon prior explorations of LLM agent design, our work introduces a simulated agent society where complex social relationships dynamically form and evolve over time. Agents are imbued with psychological drives and placed in a sandbox survival environment. We conduct an evaluation of the agent society through the lens of Thomas Hobbes's seminal Social Contract Theory (SCT). We analyze whether, as the theory postulates, agents seek to escape a brutish "state of nature" by surrendering rights to an absolute sovereign in exchange for order and security. Our experiments unveil an alignment: Initially, agents engage in unrestrained conflict, mirroring Hobbes's depiction of the state of nature. However, as the simulation progresses, social contracts emerge, leading to the authorization of an absolute sovereign and the establishment of a peaceful commonwealth founded on mutual cooperation. This congruence between our LLM agent society's evolutionary trajectory and Hobbes's theoretical account indicates LLMs' capability to model intricate social dynamics and potentially replicate forces that shape human societies. By enabling such insights into group behavior and emergent societal phenomena, LLM-driven multi-agent simulations, while unable to simulate all the nuances of human behavior, may hold potential for advancing our understanding of social structures, group dynamics, and complex human systems.
Long-horizon Locomotion and Manipulation on a Quadrupedal Robot with Large Language Models
Apr 08, 2024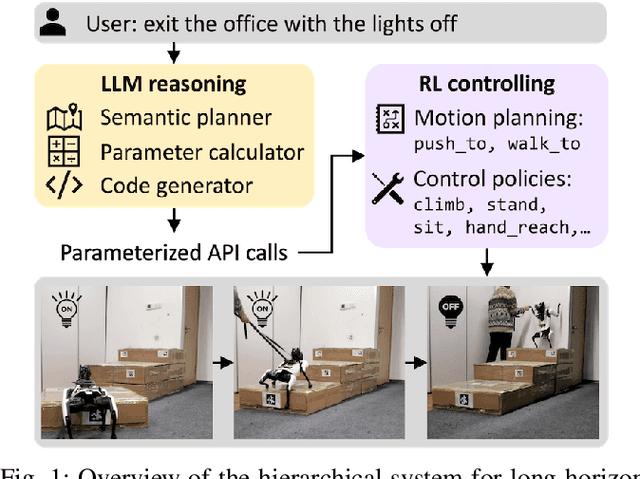



We present a large language model (LLM) based system to empower quadrupedal robots with problem-solving abilities for long-horizon tasks beyond short-term motions. Long-horizon tasks for quadrupeds are challenging since they require both a high-level understanding of the semantics of the problem for task planning and a broad range of locomotion and manipulation skills to interact with the environment. Our system builds a high-level reasoning layer with large language models, which generates hybrid discrete-continuous plans as robot code from task descriptions. It comprises multiple LLM agents: a semantic planner for sketching a plan, a parameter calculator for predicting arguments in the plan, and a code generator to convert the plan into executable robot code. At the low level, we adopt reinforcement learning to train a set of motion planning and control skills to unleash the flexibility of quadrupeds for rich environment interactions. Our system is tested on long-horizon tasks that are infeasible to complete with one single skill. Simulation and real-world experiments show that it successfully figures out multi-step strategies and demonstrates non-trivial behaviors, including building tools or notifying a human for help.
Learning Agile Bipedal Motions on a Quadrupedal Robot
Nov 10, 2023
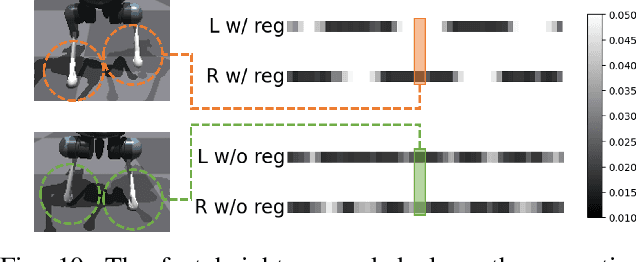
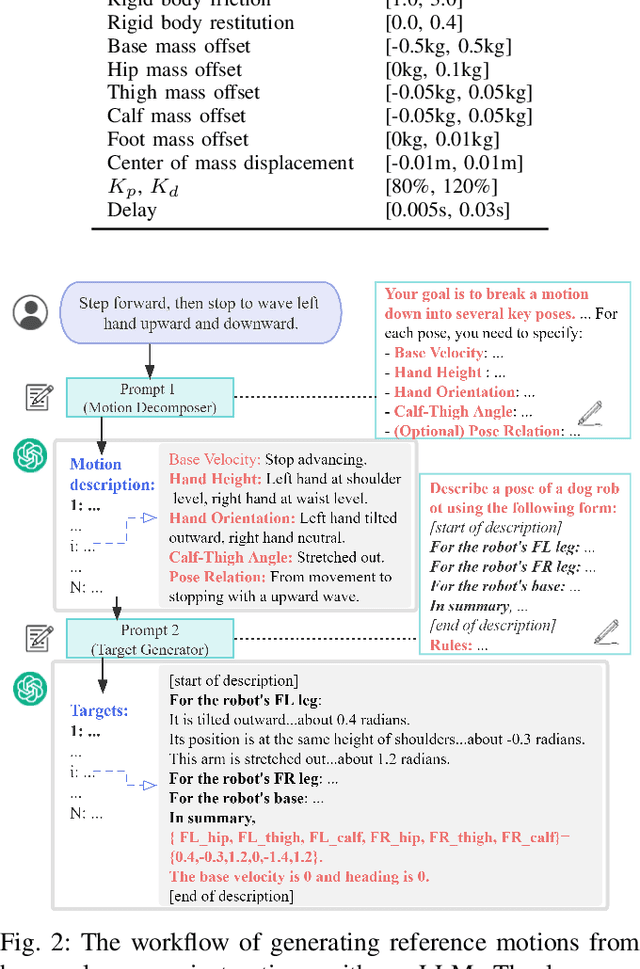

Can a quadrupedal robot perform bipedal motions like humans? Although developing human-like behaviors is more often studied on costly bipedal robot platforms, we present a solution over a lightweight quadrupedal robot that unlocks the agility of the quadruped in an upright standing pose and is capable of a variety of human-like motions. Our framework is with a bi-level structure. At the low level is a motion-conditioned control policy that allows the quadrupedal robot to track desired base and front limb movements while balancing on two hind feet. The policy is commanded by a high-level motion generator that gives trajectories of parameterized human-like motions to the robot from multiple modalities of human input. We for the first time demonstrate various bipedal motions on a quadrupedal robot, and showcase interesting human-robot interaction modes including mimicking human videos, following natural language instructions, and physical interaction.