 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightCity: An Urban Dataset for Outdoor Inverse Rendering and Reconstruction under Multi-illumination Conditions
Feb 01, 2026Inverse rendering in urban scenes is pivotal for applications like autonomous driving and digital twins. Yet, it faces significant challenges due to complex illumination conditions, including multi-illumination and indirect light and shadow effects. However, the effects of these challenges on intrinsic decomposition and 3D reconstruction have not been explored due to the lack of appropriate datasets. In this paper, we present LightCity, a novel high-quality synthetic urban dataset featuring diverse illumination conditions with realistic indirect light and shadow effects. LightCity encompasses over 300 sky maps with highly controllable illumination, varying scales with street-level and aerial perspectives over 50K images, and rich properties such as depth, normal, material components, light and indirect light, etc. Besides, we leverage LightCity to benchmark three fundamental tasks in the urban environments and conduct a comprehensive analysis of these benchmarks, laying a robust foundation for advancing related research.
NitroGen: An Open Foundation Model for Generalist Gaming Agents
Jan 04, 2026We introduce NitroGen, a vision-action foundation model for generalist gaming agents that is trained on 40,000 hours of gameplay videos across more than 1,000 games. We incorporate three key ingredients: 1) an internet-scale video-action dataset constructed by automatically extracting player actions from publicly available gameplay videos, 2) a multi-game benchmark environment that can measure cross-game generalization, and 3) a unified vision-action model trained with large-scale behavior cloning. NitroGen exhibits strong competence across diverse domains, including combat encounters in 3D action games, high-precision control in 2D platformers, and exploration in procedurally generated worlds. It transfers effectively to unseen games, achieving up to 52% relative improvement in task success rates over models trained from scratch. We release the dataset, evaluation suite, and model weights to advance research on generalist embodied agents.
CHIP: Adaptive Compliance for Humanoid Control through Hindsight Perturbation
Dec 16, 2025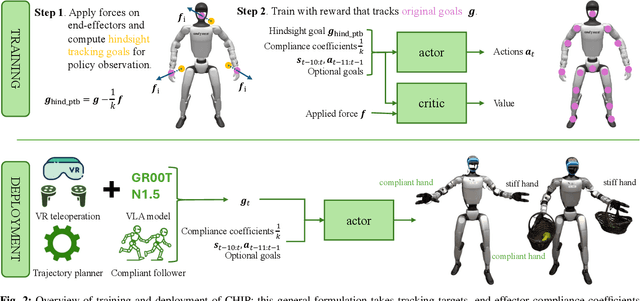
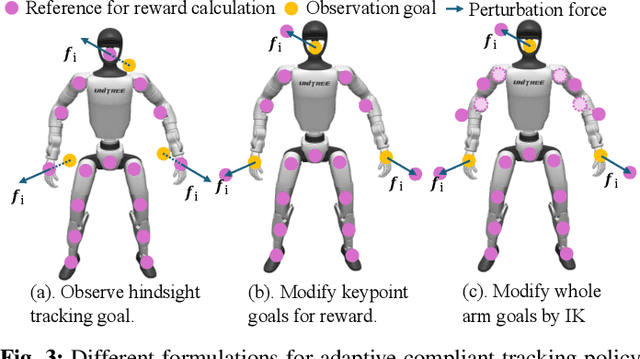
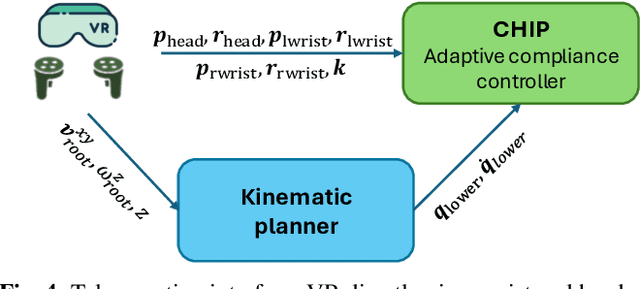

Recent progress in humanoid robots has unlocked agile locomotion skills, including backflipping, running, and crawling. Yet it remains challenging for a humanoid robot to perform forceful manipulation tasks such as moving objects, wiping, and pushing a cart. We propose adaptive Compliance Humanoid control through hIsight Perturbation (CHIP), a plug-and-play module that enables controllable end-effector stiffness while preserving agile tracking of dynamic reference motions. CHIP is easy to implement and requires neither data augmentation nor additional reward tuning. We show that a generalist motion-tracking controller trained with CHIP can perform a diverse set of forceful manipulation tasks that require different end-effector compliance, such as multi-robot collaboration, wiping, box delivery, and door opening.
VIRAL: Visual Sim-to-Real at Scale for Humanoid Loco-Manipulation
Nov 19, 2025
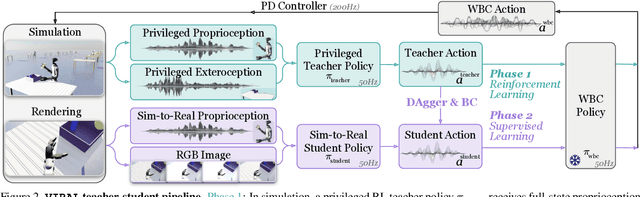
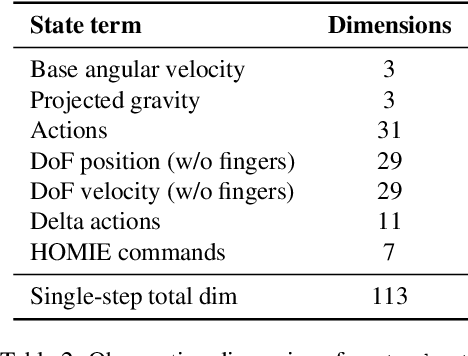

A key barrier to the real-world deployment of humanoid robots is the lack of autonomous loco-manipulation skills. We introduce VIRAL, a visual sim-to-real framework that learns humanoid loco-manipulation entirely in simulation and deploys it zero-shot to real hardware. VIRAL follows a teacher-student design: a privileged RL teacher, operating on full state, learns long-horizon loco-manipulation using a delta action space and reference state initialization. A vision-based student policy is then distilled from the teacher via large-scale simulation with tiled rendering, trained with a mixture of online DAgger and behavior cloning. We find that compute scale is critical: scaling simulation to tens of GPUs (up to 64) makes both teacher and student training reliable, while low-compute regimes often fail. To bridge the sim-to-real gap, VIRAL combines large-scale visual domain randomization over lighting, materials, camera parameters, image quality, and sensor delays--with real-to-sim alignment of the dexterous hands and cameras. Deployed on a Unitree G1 humanoid, the resulting RGB-based policy performs continuous loco-manipulation for up to 54 cycles, generalizing to diverse spatial and appearance variations without any real-world fine-tuning, and approaching expert-level teleoperation performance. Extensive ablations dissect the key design choices required to make RGB-based humanoid loco-manipulation work in practice.
LLM-GROP: Visually Grounded Robot Task and Motion Planning with Large Language Models
Nov 11, 2025Task planning and motion planning are two of the most important problems in robotics, where task planning methods help robots achieve high-level goals and motion planning methods maintain low-level feasibility. Task and motion planning (TAMP) methods interleave the two processes of task planning and motion planning to ensure goal achievement and motion feasibility. Within the TAMP context, we are concerned with the mobile manipulation (MoMa) of multiple objects, where it is necessary to interleave actions for navigation and manipulation. In particular, we aim to compute where and how each object should be placed given underspecified goals, such as ``set up dinner table with a fork, knife and plate.'' We leverage the rich common sense knowledge from large language models (LLMs), e.g., about how tableware is organized, to facilitate both task-level and motion-level planning. In addition, we use computer vision methods to learn a strategy for selecting base positions to facilitate MoMa behaviors, where the base position corresponds to the robot's ``footprint'' and orientation in its operating space. Altogether, this article provides a principled TAMP framework for MoMa tasks that accounts for common sense about object rearrangement and is adaptive to novel situations that include many objects that need to be moved. We performed quantitative experiments in both real-world settings and simulated environments. We evaluated the success rate and efficiency in completing long-horizon object rearrangement tasks. While the robot completed 84.4\% real-world object rearrangement trials, subjective human evaluations indicated that the robot's performance is still lower than experienced human waiters.
SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control
Nov 11, 2025Despite the rise of billion-parameter foundation models trained across thousands of GPUs, similar scaling gains have not been shown for humanoid control. Current neural controllers for humanoids remain modest in size, target a limited behavior set, and are trained on a handful of GPUs over several days. We show that scaling up model capacity, data, and compute yields a generalist humanoid controller capable of creating natural and robust whole-body movements. Specifically, we posit motion tracking as a natural and scalable task for humanoid control, leverageing dense supervision from diverse motion-capture data to acquire human motion priors without manual reward engineering. We build a foundation model for motion tracking by scaling along three axes: network size (from 1.2M to 42M parameters), dataset volume (over 100M frames, 700 hours of high-quality motion data), and compute (9k GPU hours). Beyond demonstrating the benefits of scale, we show the practical utility of our model through two mechanisms: (1) a real-time universal kinematic planner that bridges motion tracking to downstream task execution, enabling natural and interactive control, and (2) a unified token space that supports various motion input interfaces, such as VR teleoperation devices, human videos, and vision-language-action (VLA) models, all using the same policy. Scaling motion tracking exhibits favorable properties: performance improves steadily with increased compute and data diversity, and learned representations generalize to unseen motions, establishing motion tracking at scale as a practical foundation for humanoid control.
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
DEAS: DEtached value learning with Action Sequence for Scalable Offline RL
Oct 09, 2025



Offline reinforcement learning (RL) presents an attractive paradigm for training intelligent agents without expensive online interactions. However, current approaches still struggle with complex, long-horizon sequential decision making. In this work, we introduce DEtached value learning with Action Sequence (DEAS), a simple yet effective offline RL framework that leverages action sequences for value learning. These temporally extended actions provide richer information than single-step actions and can be interpreted through the options framework via semi-Markov decision process Q-learning, enabling reduction of the effective planning horizon by considering longer sequences at once. However, directly adopting such sequences in actor-critic algorithms introduces excessive value overestimation, which we address through detached value learning that steers value estimates toward in-distribution actions that achieve high return in the offline dataset. We demonstrate that DEAS consistently outperforms baselines on complex, long-horizon tasks from OGBench and can be applied to enhance the performance of large-scale Vision-Language-Action models that predict action sequences, significantly boosting performance in both RoboCasa Kitchen simulation tasks and real-world manipulation tasks.
Vision-Language-Action Models for Robotics: A Review Towards Real-World Applications
Oct 08, 2025Amid growing efforts to leverage advances in large language models (LLMs) and vision-language models (VLMs) for robotics, Vision-Language-Action (VLA) models have recently gained significant attention. By unifying vision, language, and action data at scale, which have traditionally been studied separately, VLA models aim to learn policies that generalise across diverse tasks, objects, embodiments, and environments. This generalisation capability is expected to enable robots to solve novel downstream tasks with minimal or no additional task-specific data, facilitating more flexible and scalable real-world deployment. Unlike previous surveys that focus narrowly on action representations or high-level model architectures, this work offers a comprehensive, full-stack review, integrating both software and hardware components of VLA systems. In particular, this paper provides a systematic review of VLAs, covering their strategy and architectural transition, architectures and building blocks, modality-specific processing techniques, and learning paradigms. In addition, to support the deployment of VLAs in real-world robotic applications, we also review commonly used robot platforms, data collection strategies, publicly available datasets, data augmentation methods, and evaluation benchmarks. Throughout this comprehensive survey, this paper aims to offer practical guidance for the robotics community in applying VLAs to real-world robotic systems. All references categorized by training approach, evaluation method, modality, and dataset are available in the table on our project website: https://vla-survey.github.io .
Constraint-Preserving Data Generation for Visuomotor Policy Learning
Aug 05, 2025



Large-scale demonstration data has powered key breakthroughs in robot manipulation, but collecting that data remains costly and time-consuming. We present Constraint-Preserving Data Generation (CP-Gen), a method that uses a single expert trajectory to generate robot demonstrations containing novel object geometries and poses. These generated demonstrations are used to train closed-loop visuomotor policies that transfer zero-shot to the real world and generalize across variations in object geometries and poses. Similar to prior work using pose variations for data generation, CP-Gen first decomposes expert demonstrations into free-space motions and robot skills. But unlike those works, we achieve geometry-aware data generation by formulating robot skills as keypoint-trajectory constraints: keypoints on the robot or grasped object must track a reference trajectory defined relative to a task-relevant object. To generate a new demonstration, CP-Gen samples pose and geometry transforms for each task-relevant object, then applies these transforms to the object and its associated keypoints or keypoint trajectories. We optimize robot joint configurations so that the keypoints on the robot or grasped object track the transformed keypoint trajectory, and then motion plan a collision-free path to the first optimized joint configuration. Experiments on 16 simulation tasks and four real-world tasks, featuring multi-stage, non-prehensile and tight-tolerance manipulation, show that policies trained using CP-Gen achieve an average success rate of 77%, outperforming the best baseline that achieves an average of 50%.