 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFire on Motion: Optimizing Video Pass-bands for Efficient Spiking Action Recognition
Jan 30, 2026Spiking neural networks (SNNs) have gained traction in vision due to their energy efficiency, bio-plausibility, and inherent temporal processing. Yet, despite this temporal capacity, most progress concentrates on static image benchmarks, and SNNs still underperform on dynamic video tasks compared to artificial neural networks (ANNs). In this work, we diagnose a fundamental pass-band mismatch: Standard spiking dynamics behave as a temporal low pass that emphasizes static content while attenuating motion bearing bands, where task relevant information concentrates in dynamic tasks. This phenomenon explains why SNNs can approach ANNs on static tasks yet fall behind on tasks that demand richer temporal understanding.To remedy this, we propose the Pass-Bands Optimizer (PBO), a plug-and-play module that optimizes the temporal pass-band toward task-relevant motion bands. PBO introduces only two learnable parameters, and a lightweight consistency constraint that preserves semantics and boundaries, incurring negligible computational overhead and requires no architectural changes. PBO deliberately suppresses static components that contribute little to discrimination, effectively high passing the stream so that spiking activity concentrates on motion bearing content. On UCF101, PBO yields over ten percentage points improvement. On more complex multi-modal action recognition and weakly supervised video anomaly detection, PBO delivers consistent and significant gains, offering a new perspective for SNN based video processing and understanding.
Breaking the Modality Wall: Time-step Mixup for Efficient Spiking Knowledge Transfer from Static to Event Domain
Nov 15, 2025The integration of event cameras and spiking neural networks (SNNs) promises energy-efficient visual intelligence, yet scarce event data and the sparsity of DVS outputs hinder effective training. Prior knowledge transfers from RGB to DVS often underperform because the distribution gap between modalities is substantial. In this work, we present Time-step Mixup Knowledge Transfer (TMKT), a cross-modal training framework with a probabilistic Time-step Mixup (TSM) strategy. TSM exploits the asynchronous nature of SNNs by interpolating RGB and DVS inputs at various time steps to produce a smooth curriculum within each sequence, which reduces gradient variance and stabilizes optimization with theoretical analysis. To employ auxiliary supervision from TSM, TMKT introduces two lightweight modality-aware objectives, Modality Aware Guidance (MAG) for per-frame source supervision and Mixup Ratio Perception (MRP) for sequence-level mix ratio estimation, which explicitly align temporal features with the mixing schedule. TMKT enables smoother knowledge transfer, helps mitigate modality mismatch during training, and achieves superior performance in spiking image classification tasks. Extensive experiments across diverse benchmarks and multiple SNN backbones, together with ablations, demonstrate the effectiveness of our method.
Time-step Mixup for Efficient Spiking Knowledge Transfer from Appearance to Event Domain
Sep 16, 2025The integration of event cameras and spiking neural networks holds great promise for energy-efficient visual processing. However, the limited availability of event data and the sparse nature of DVS outputs pose challenges for effective training. Although some prior work has attempted to transfer semantic knowledge from RGB datasets to DVS, they often overlook the significant distribution gap between the two modalities. In this paper, we propose Time-step Mixup knowledge transfer (TMKT), a novel fine-grained mixing strategy that exploits the asynchronous nature of SNNs by interpolating RGB and DVS inputs at various time-steps. To enable label mixing in cross-modal scenarios, we further introduce modality-aware auxiliary learning objectives. These objectives support the time-step mixup process and enhance the model's ability to discriminate effectively across different modalities. Our approach enables smoother knowledge transfer, alleviates modality shift during training, and achieves superior performance in spiking image classification tasks. Extensive experiments demonstrate the effectiveness of our method across multiple datasets. The code will be released after the double-blind review process.
SCIZOR: A Self-Supervised Approach to Data Curation for Large-Scale Imitation Learning
May 28, 2025Imitation learning advances robot capabilities by enabling the acquisition of diverse behaviors from human demonstrations. However, large-scale datasets used for policy training often introduce substantial variability in quality, which can negatively impact performance. As a result, automatically curating datasets by filtering low-quality samples to improve quality becomes essential. Existing robotic curation approaches rely on costly manual annotations and perform curation at a coarse granularity, such as the dataset or trajectory level, failing to account for the quality of individual state-action pairs. To address this, we introduce SCIZOR, a self-supervised data curation framework that filters out low-quality state-action pairs to improve the performance of imitation learning policies. SCIZOR targets two complementary sources of low-quality data: suboptimal data, which hinders learning with undesirable actions, and redundant data, which dilutes training with repetitive patterns. SCIZOR leverages a self-supervised task progress predictor for suboptimal data to remove samples lacking task progression, and a deduplication module operating on joint state-action representation for samples with redundant patterns. Empirically, we show that SCIZOR enables imitation learning policies to achieve higher performance with less data, yielding an average improvement of 15.4% across multiple benchmarks. More information is available at: https://ut-austin-rpl.github.io/SCIZOR/
Human-Level Competitive Pokémon via Scalable Offline Reinforcement Learning with Transformers
Apr 06, 2025Competitive Pok\'emon Singles (CPS) is a popular strategy game where players learn to exploit their opponent based on imperfect information in battles that can last more than one hundred stochastic turns. AI research in CPS has been led by heuristic tree search and online self-play, but the game may also create a platform to study adaptive policies trained offline on large datasets. We develop a pipeline to reconstruct the first-person perspective of an agent from logs saved from the third-person perspective of a spectator, thereby unlocking a dataset of real human battles spanning more than a decade that grows larger every day. This dataset enables a black-box approach where we train large sequence models to adapt to their opponent based solely on their input trajectory while selecting moves without explicit search of any kind. We study a progression from imitation learning to offline RL and offline fine-tuning on self-play data in the hardcore competitive setting of Pok\'emon's four oldest (and most partially observed) game generations. The resulting agents outperform a recent LLM Agent approach and a strong heuristic search engine. While playing anonymously in online battles against humans, our best agents climb to rankings inside the top 10% of active players.
Sim-and-Real Co-Training: A Simple Recipe for Vision-Based Robotic Manipulation
Mar 31, 2025Large real-world robot datasets hold great potential to train generalist robot models, but scaling real-world human data collection is time-consuming and resource-intensive. Simulation has great potential in supplementing large-scale data, especially with recent advances in generative AI and automated data generation tools that enable scalable creation of robot behavior datasets. However, training a policy solely in simulation and transferring it to the real world often demands substantial human effort to bridge the reality gap. A compelling alternative is to co-train the policy on a mixture of simulation and real-world datasets. Preliminary studies have recently shown this strategy to substantially improve the performance of a policy over one trained on a limited amount of real-world data. Nonetheless, the community lacks a systematic understanding of sim-and-real co-training and what it takes to reap the benefits of simulation data for real-robot learning. This work presents a simple yet effective recipe for utilizing simulation data to solve vision-based robotic manipulation tasks. We derive this recipe from comprehensive experiments that validate the co-training strategy on various simulation and real-world datasets. Using two domains--a robot arm and a humanoid--across diverse tasks, we demonstrate that simulation data can enhance real-world task performance by an average of 38%, even with notable differences between the simulation and real-world data. Videos and additional results can be found at https://co-training.github.io/
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Mar 18, 2025General-purpose robots need a versatile body and an intelligent mind. Recent advancements in humanoid robots have shown great promise as a hardware platform for building generalist autonomy in the human world. A robot foundation model, trained on massive and diverse data sources, is essential for enabling the robots to reason about novel situations, robustly handle real-world variability, and rapidly learn new tasks. To this end, we introduce GR00T N1, an open foundation model for humanoid robots. GR00T N1 is a Vision-Language-Action (VLA) model with a dual-system architecture. The vision-language module (System 2) interprets the environment through vision and language instructions. The subsequent diffusion transformer module (System 1) generates fluid motor actions in real time. Both modules are tightly coupled and jointly trained end-to-end. We train GR00T N1 with a heterogeneous mixture of real-robot trajectories, human videos, and synthetically generated datasets. We show that our generalist robot model GR00T N1 outperforms the state-of-the-art imitation learning baselines on standard simulation benchmarks across multiple robot embodiments. Furthermore, we deploy our model on the Fourier GR-1 humanoid robot for language-conditioned bimanual manipulation tasks, achieving strong performance with high data efficiency.
DexMimicGen: Automated Data Generation for Bimanual Dexterous Manipulation via Imitation Learning
Oct 31, 2024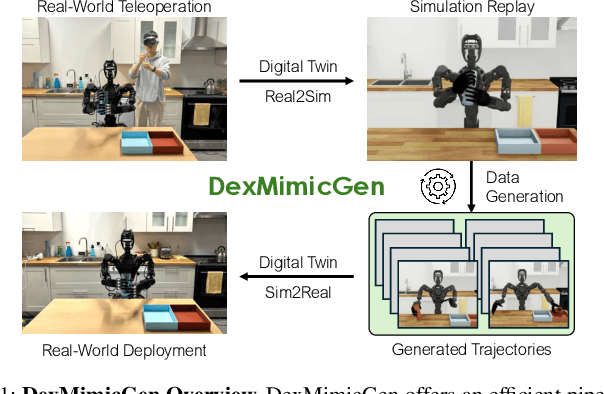

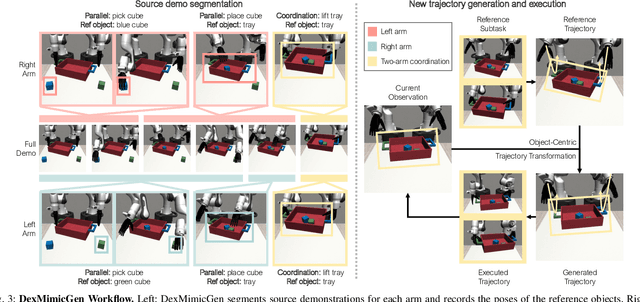

Imitation learning from human demonstrations is an effective means to teach robots manipulation skills. But data acquisition is a major bottleneck in applying this paradigm more broadly, due to the amount of cost and human effort involved. There has been significant interest in imitation learning for bimanual dexterous robots, like humanoids. Unfortunately, data collection is even more challenging here due to the challenges of simultaneously controlling multiple arms and multi-fingered hands. Automated data generation in simulation is a compelling, scalable alternative to fuel this need for data. To this end, we introduce DexMimicGen, a large-scale automated data generation system that synthesizes trajectories from a handful of human demonstrations for humanoid robots with dexterous hands. We present a collection of simulation environments in the setting of bimanual dexterous manipulation, spanning a range of manipulation behaviors and different requirements for coordination among the two arms. We generate 21K demos across these tasks from just 60 source human demos and study the effect of several data generation and policy learning decisions on agent performance. Finally, we present a real-to-sim-to-real pipeline and deploy it on a real-world humanoid can sorting task. Videos and more are at https://dexmimicgen.github.io/
Harmon: Whole-Body Motion Generation of Humanoid Robots from Language Descriptions
Oct 16, 2024Humanoid robots, with their human-like embodiment, have the potential to integrate seamlessly into human environments. Critical to their coexistence and cooperation with humans is the ability to understand natural language communications and exhibit human-like behaviors. This work focuses on generating diverse whole-body motions for humanoid robots from language descriptions. We leverage human motion priors from extensive human motion datasets to initialize humanoid motions and employ the commonsense reasoning capabilities of Vision Language Models (VLMs) to edit and refine these motions. Our approach demonstrates the capability to produce natural, expressive, and text-aligned humanoid motions, validated through both simulated and real-world experiments. More videos can be found at https://ut-austin-rpl.github.io/Harmon/.
OKAMI: Teaching Humanoid Robots Manipulation Skills through Single Video Imitation
Oct 15, 2024



We study the problem of teaching humanoid robots manipulation skills by imitating from single video demonstrations. We introduce OKAMI, a method that generates a manipulation plan from a single RGB-D video and derives a policy for execution. At the heart of our approach is object-aware retargeting, which enables the humanoid robot to mimic the human motions in an RGB-D video while adjusting to different object locations during deployment. OKAMI uses open-world vision models to identify task-relevant objects and retarget the body motions and hand poses separately. Our experiments show that OKAMI achieves strong generalizations across varying visual and spatial conditions, outperforming the state-of-the-art baseline on open-world imitation from observation. Furthermore, OKAMI rollout trajectories are leveraged to train closed-loop visuomotor policies, which achieve an average success rate of 79.2% without the need for labor-intensive teleoperation. More videos can be found on our website https://ut-austin-rpl.github.io/OKAMI/.