 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRayZer: A Self-supervised Large View Synthesis Model
May 01, 2025



We present RayZer, a self-supervised multi-view 3D Vision model trained without any 3D supervision, i.e., camera poses and scene geometry, while exhibiting emerging 3D awareness. Concretely, RayZer takes unposed and uncalibrated images as input, recovers camera parameters, reconstructs a scene representation, and synthesizes novel views. During training, RayZer relies solely on its self-predicted camera poses to render target views, eliminating the need for any ground-truth camera annotations and allowing RayZer to be trained with 2D image supervision. The emerging 3D awareness of RayZer is attributed to two key factors. First, we design a self-supervised framework, which achieves 3D-aware auto-encoding of input images by disentangling camera and scene representations. Second, we design a transformer-based model in which the only 3D prior is the ray structure, connecting camera, pixel, and scene simultaneously. RayZer demonstrates comparable or even superior novel view synthesis performance than ``oracle'' methods that rely on pose annotations in both training and testing. Project: https://hwjiang1510.github.io/RayZer/
Reconstructing Humans with a Biomechanically Accurate Skeleton
Mar 27, 2025



In this paper, we introduce a method for reconstructing 3D humans from a single image using a biomechanically accurate skeleton model. To achieve this, we train a transformer that takes an image as input and estimates the parameters of the model. Due to the lack of training data for this task, we build a pipeline to produce pseudo ground truth model parameters for single images and implement a training procedure that iteratively refines these pseudo labels. Compared to state-of-the-art methods for 3D human mesh recovery, our model achieves competitive performance on standard benchmarks, while it significantly outperforms them in settings with extreme 3D poses and viewpoints. Additionally, we show that previous reconstruction methods frequently violate joint angle limits, leading to unnatural rotations. In contrast, our approach leverages the biomechanically plausible degrees of freedom making more realistic joint rotation estimates. We validate our approach across multiple human pose estimation benchmarks. We make the code, models and data available at: https://isshikihugh.github.io/HSMR/
MegaSynth: Scaling Up 3D Scene Reconstruction with Synthesized Data
Dec 18, 2024



We propose scaling up 3D scene reconstruction by training with synthesized data. At the core of our work is MegaSynth, a procedurally generated 3D dataset comprising 700K scenes - over 50 times larger than the prior real dataset DL3DV - dramatically scaling the training data. To enable scalable data generation, our key idea is eliminating semantic information, removing the need to model complex semantic priors such as object affordances and scene composition. Instead, we model scenes with basic spatial structures and geometry primitives, offering scalability. Besides, we control data complexity to facilitate training while loosely aligning it with real-world data distribution to benefit real-world generalization. We explore training LRMs with both MegaSynth and available real data. Experiment results show that joint training or pre-training with MegaSynth improves reconstruction quality by 1.2 to 1.8 dB PSNR across diverse image domains. Moreover, models trained solely on MegaSynth perform comparably to those trained on real data, underscoring the low-level nature of 3D reconstruction. Additionally, we provide an in-depth analysis of MegaSynth's properties for enhancing model capability, training stability, and generalization.
FIction: 4D Future Interaction Prediction from Video
Dec 01, 2024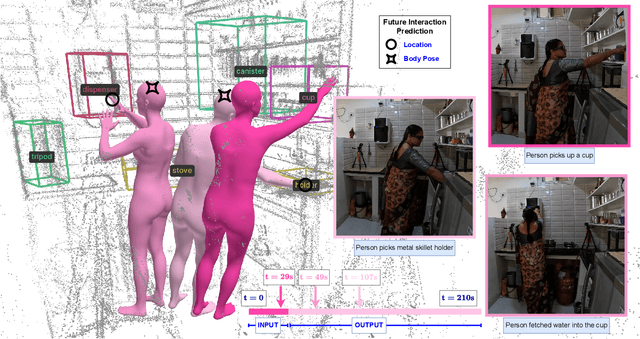
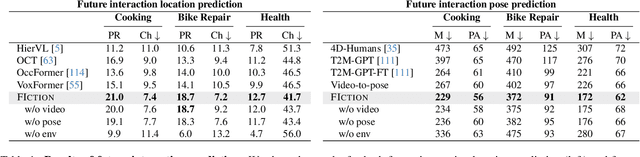
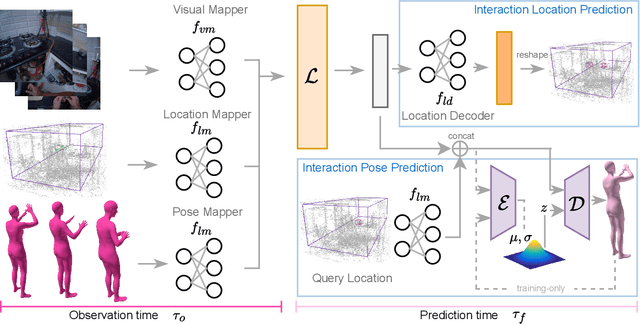
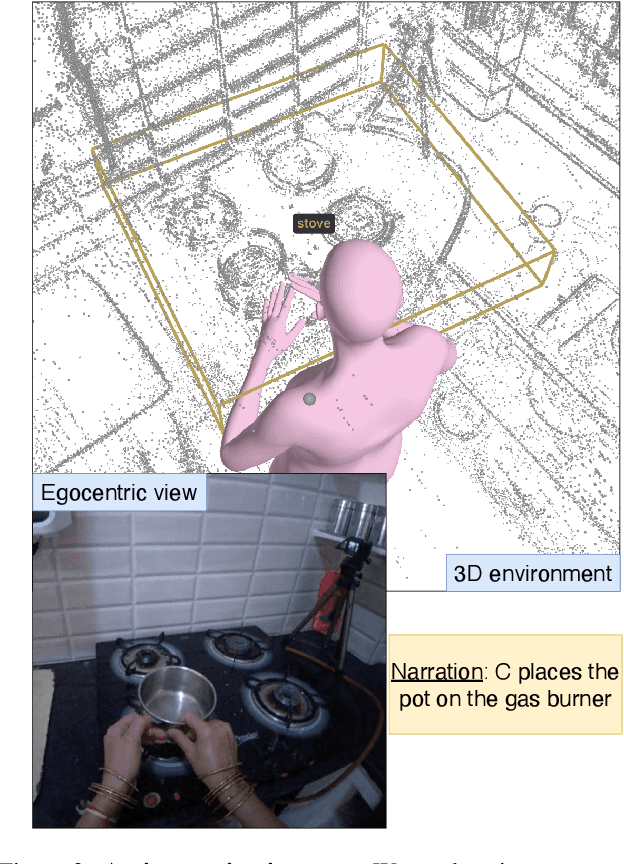
Anticipating how a person will interact with objects in an environment is essential for activity understanding, but existing methods are limited to the 2D space of video frames-capturing physically ungrounded predictions of 'what' and ignoring the 'where' and 'how'. We introduce 4D future interaction prediction from videos. Given an input video of a human activity, the goal is to predict what objects at what 3D locations the person will interact with in the next time period (e.g., cabinet, fridge), and how they will execute that interaction (e.g., poses for bending, reaching, pulling). We propose a novel model FIction that fuses the past video observation of the person's actions and their environment to predict both the 'where' and 'how' of future interactions. Through comprehensive experiments on a variety of activities and real-world environments in Ego-Exo4D, we show that our proposed approach outperforms prior autoregressive and (lifted) 2D video models substantially, with more than 30% relative gains.
OKAMI: Teaching Humanoid Robots Manipulation Skills through Single Video Imitation
Oct 15, 2024



We study the problem of teaching humanoid robots manipulation skills by imitating from single video demonstrations. We introduce OKAMI, a method that generates a manipulation plan from a single RGB-D video and derives a policy for execution. At the heart of our approach is object-aware retargeting, which enables the humanoid robot to mimic the human motions in an RGB-D video while adjusting to different object locations during deployment. OKAMI uses open-world vision models to identify task-relevant objects and retarget the body motions and hand poses separately. Our experiments show that OKAMI achieves strong generalizations across varying visual and spatial conditions, outperforming the state-of-the-art baseline on open-world imitation from observation. Furthermore, OKAMI rollout trajectories are leveraged to train closed-loop visuomotor policies, which achieve an average success rate of 79.2% without the need for labor-intensive teleoperation. More videos can be found on our website https://ut-austin-rpl.github.io/OKAMI/.
Estimating Body and Hand Motion in an Ego-sensed World
Oct 04, 2024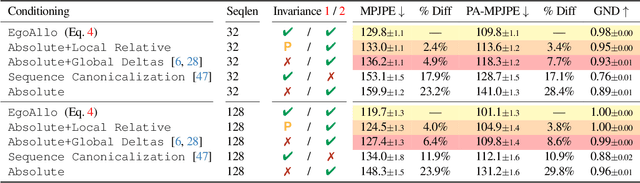
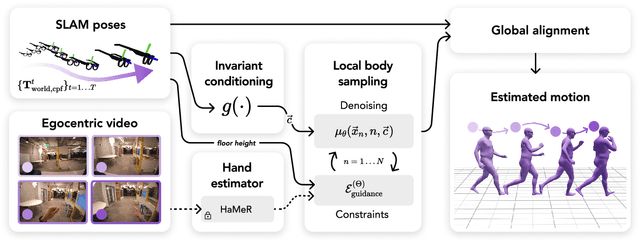
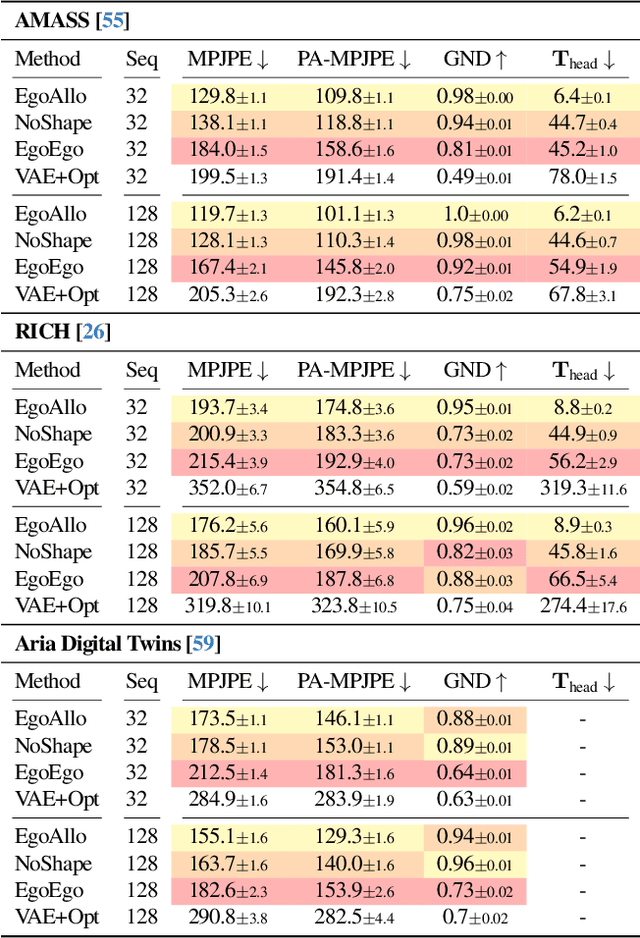
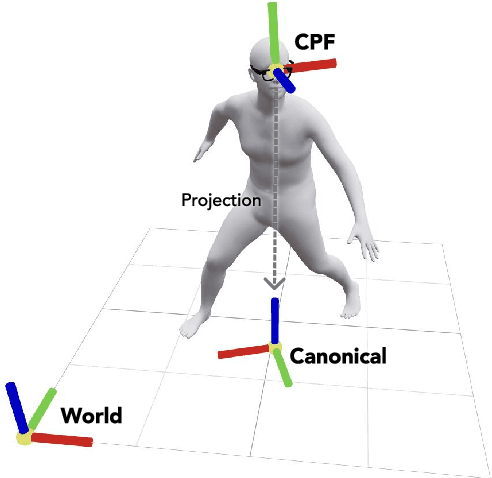
We present EgoAllo, a system for human motion estimation from a head-mounted device. Using only egocentric SLAM poses and images, EgoAllo guides sampling from a conditional diffusion model to estimate 3D body pose, height, and hand parameters that capture the wearer's actions in the allocentric coordinate frame of the scene. To achieve this, our key insight is in representation: we propose spatial and temporal invariance criteria for improving model performance, from which we derive a head motion conditioning parameterization that improves estimation by up to 18%. We also show how the bodies estimated by our system can improve the hands: the resulting kinematic and temporal constraints result in over 40% lower hand estimation errors compared to noisy monocular estimates. Project page: https://egoallo.github.io/
Synergy and Synchrony in Couple Dances
Sep 06, 2024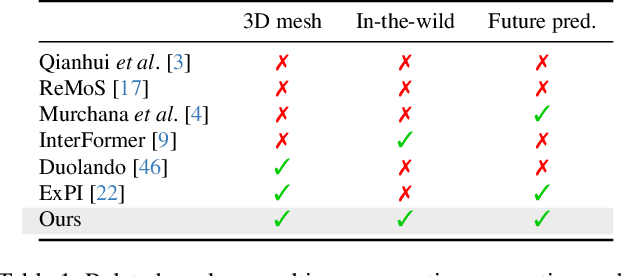
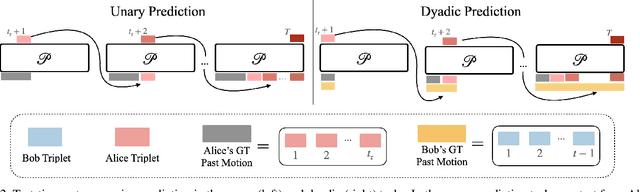
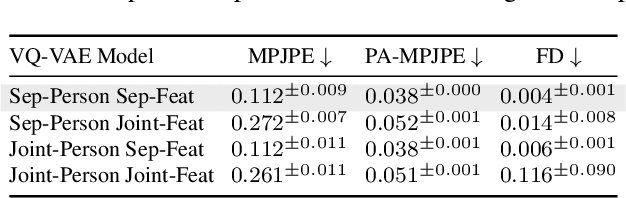
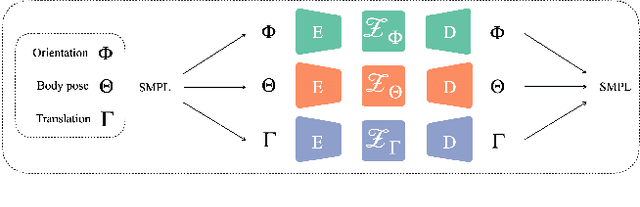
This paper asks to what extent social interaction influences one's behavior. We study this in the setting of two dancers dancing as a couple. We first consider a baseline in which we predict a dancer's future moves conditioned only on their past motion without regard to their partner. We then investigate the advantage of taking social information into account by conditioning also on the motion of their dancing partner. We focus our analysis on Swing, a dance genre with tight physical coupling for which we present an in-the-wild video dataset. We demonstrate that single-person future motion prediction in this context is challenging. Instead, we observe that prediction greatly benefits from considering the interaction partners' behavior, resulting in surprisingly compelling couple dance synthesis results (see supp. video). Our contributions are a demonstration of the advantages of socially conditioned future motion prediction and an in-the-wild, couple dance video dataset to enable future research in this direction. Video results are available on the project website: https://von31.github.io/synNsync
Atlas Gaussians Diffusion for 3D Generation with Infinite Number of Points
Aug 23, 2024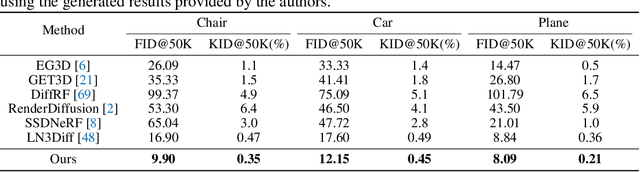
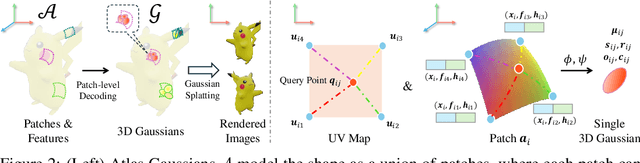
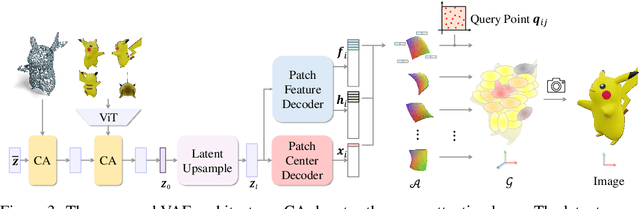
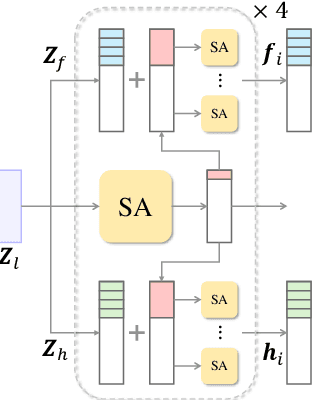
Using the latent diffusion model has proven effective in developing novel 3D generation techniques. To harness the latent diffusion model, a key challenge is designing a high-fidelity and efficient representation that links the latent space and the 3D space. In this paper, we introduce Atlas Gaussians, a novel representation for feed-forward native 3D generation. Atlas Gaussians represent a shape as the union of local patches, and each patch can decode 3D Gaussians. We parameterize a patch as a sequence of feature vectors and design a learnable function to decode 3D Gaussians from the feature vectors. In this process, we incorporate UV-based sampling, enabling the generation of a sufficiently large, and theoretically infinite, number of 3D Gaussian points. The large amount of 3D Gaussians enables high-quality details of generation results. Moreover, due to local awareness of the representation, the transformer-based decoding procedure operates on a patch level, ensuring efficiency. We train a variational autoencoder to learn the Atlas Gaussians representation, and then apply a latent diffusion model on its latent space for learning 3D Generation. Experiments show that our approach outperforms the prior arts of feed-forward native 3D generation.
ExpertAF: Expert Actionable Feedback from Video
Aug 01, 2024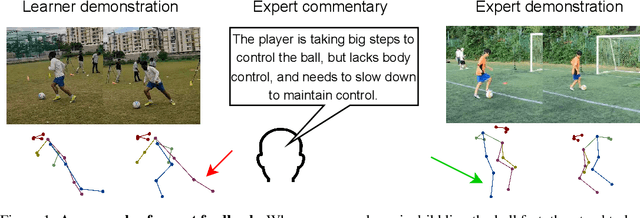
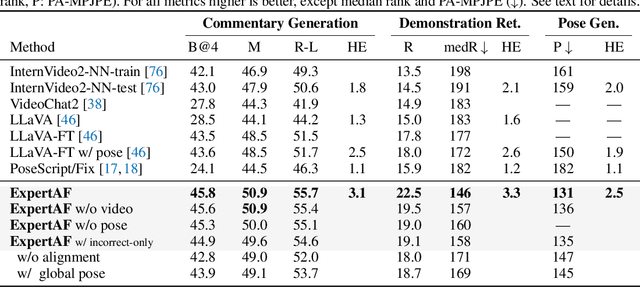
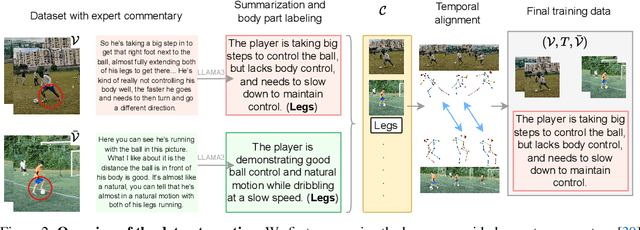
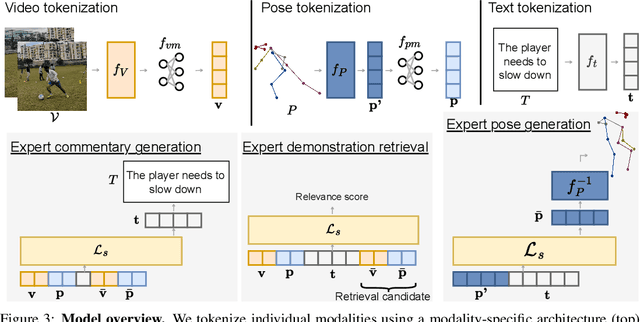
Feedback is essential for learning a new skill or improving one's current skill-level. However, current methods for skill-assessment from video only provide scores or compare demonstrations, leaving the burden of knowing what to do differently on the user. We introduce a novel method to generate actionable feedback from video of a person doing a physical activity, such as basketball or soccer. Our method takes a video demonstration and its accompanying 3D body pose and generates (1) free-form expert commentary describing what the person is doing well and what they could improve, and (2) a visual expert demonstration that incorporates the required corrections. We show how to leverage Ego-Exo4D's videos of skilled activity and expert commentary together with a strong language model to create a weakly-supervised training dataset for this task, and we devise a multimodal video-language model to infer coaching feedback. Our method is able to reason across multi-modal input combinations to output full-spectrum, actionable coaching -- expert commentary, expert video retrieval, and the first-of-its-kind expert pose generation -- outperforming strong vision-language models on both established metrics and human preference studies.
Expressive Gaussian Human Avatars from Monocular RGB Video
Jul 03, 2024



Nuanced expressiveness, particularly through fine-grained hand and facial expressions, is pivotal for enhancing the realism and vitality of digital human representations. In this work, we focus on investigating the expressiveness of human avatars when learned from monocular RGB video; a setting that introduces new challenges in capturing and animating fine-grained details. To this end, we introduce EVA, a drivable human model that meticulously sculpts fine details based on 3D Gaussians and SMPL-X, an expressive parametric human model. Focused on enhancing expressiveness, our work makes three key contributions. First, we highlight the critical importance of aligning the SMPL-X model with RGB frames for effective avatar learning. Recognizing the limitations of current SMPL-X prediction methods for in-the-wild videos, we introduce a plug-and-play module that significantly ameliorates misalignment issues. Second, we propose a context-aware adaptive density control strategy, which is adaptively adjusting the gradient thresholds to accommodate the varied granularity across body parts. Last but not least, we develop a feedback mechanism that predicts per-pixel confidence to better guide the learning of 3D Gaussians. Extensive experiments on two benchmarks demonstrate the superiority of our framework both quantitatively and qualitatively, especially on the fine-grained hand and facial details. See the project website at \url{https://evahuman.github.io}