 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion 3-to-4: 3D Motion Reconstruction for 4D Synthesis
Jan 20, 2026We present Motion 3-to-4, a feed-forward framework for synthesising high-quality 4D dynamic objects from a single monocular video and an optional 3D reference mesh. While recent advances have significantly improved 2D, video, and 3D content generation, 4D synthesis remains difficult due to limited training data and the inherent ambiguity of recovering geometry and motion from a monocular viewpoint. Motion 3-to-4 addresses these challenges by decomposing 4D synthesis into static 3D shape generation and motion reconstruction. Using a canonical reference mesh, our model learns a compact motion latent representation and predicts per-frame vertex trajectories to recover complete, temporally coherent geometry. A scalable frame-wise transformer further enables robustness to varying sequence lengths. Evaluations on both standard benchmarks and a new dataset with accurate ground-truth geometry show that Motion 3-to-4 delivers superior fidelity and spatial consistency compared to prior work. Project page is available at https://motion3-to-4.github.io/.
Long-LRM++: Preserving Fine Details in Feed-Forward Wide-Coverage Reconstruction
Dec 11, 2025



Recent advances in generalizable Gaussian splatting (GS) have enabled feed-forward reconstruction of scenes from tens of input views. Long-LRM notably scales this paradigm to 32 input images at $950\times540$ resolution, achieving 360° scene-level reconstruction in a single forward pass. However, directly predicting millions of Gaussian parameters at once remains highly error-sensitive: small inaccuracies in positions or other attributes lead to noticeable blurring, particularly in fine structures such as text. In parallel, implicit representation methods such as LVSM and LaCT have demonstrated significantly higher rendering fidelity by compressing scene information into model weights rather than explicit Gaussians, and decoding RGB frames using the full transformer or TTT backbone. However, this computationally intensive decompression process for every rendered frame makes real-time rendering infeasible. These observations raise key questions: Is the deep, sequential "decompression" process necessary? Can we retain the benefits of implicit representations while enabling real-time performance? We address these questions with Long-LRM++, a model that adopts a semi-explicit scene representation combined with a lightweight decoder. Long-LRM++ matches the rendering quality of LaCT on DL3DV while achieving real-time 14 FPS rendering on an A100 GPU, overcoming the speed limitations of prior implicit methods. Our design also scales to 64 input views at the $950\times540$ resolution, demonstrating strong generalization to increased input lengths. Additionally, Long-LRM++ delivers superior novel-view depth prediction on ScanNetv2 compared to direct depth rendering from Gaussians. Extensive ablation studies validate the effectiveness of each component in the proposed framework.
4D-LRM: Large Space-Time Reconstruction Model From and To Any View at Any Time
Jun 23, 2025Can we scale 4D pretraining to learn general space-time representations that reconstruct an object from a few views at some times to any view at any time? We provide an affirmative answer with 4D-LRM, the first large-scale 4D reconstruction model that takes input from unconstrained views and timestamps and renders arbitrary novel view-time combinations. Unlike prior 4D approaches, e.g., optimization-based, geometry-based, or generative, that struggle with efficiency, generalization, or faithfulness, 4D-LRM learns a unified space-time representation and directly predicts per-pixel 4D Gaussian primitives from posed image tokens across time, enabling fast, high-quality rendering at, in principle, infinite frame rate. Our results demonstrate that scaling spatiotemporal pretraining enables accurate and efficient 4D reconstruction. We show that 4D-LRM generalizes to novel objects, interpolates across time, and handles diverse camera setups. It reconstructs 24-frame sequences in one forward pass with less than 1.5 seconds on a single A100 GPU.
Neural BRDF Importance Sampling by Reparameterization
May 13, 2025Neural bidirectional reflectance distribution functions (BRDFs) have emerged as popular material representations for enhancing realism in physically-based rendering. Yet their importance sampling remains a significant challenge. In this paper, we introduce a reparameterization-based formulation of neural BRDF importance sampling that seamlessly integrates into the standard rendering pipeline with precise generation of BRDF samples. The reparameterization-based formulation transfers the distribution learning task to a problem of identifying BRDF integral substitutions. In contrast to previous methods that rely on invertible networks and multi-step inference to reconstruct BRDF distributions, our model removes these constraints, which offers greater flexibility and efficiency. Our variance and performance analysis demonstrates that our reparameterization method achieves the best variance reduction in neural BRDF renderings while maintaining high inference speeds compared to existing baselines.
Gaussian Mixture Flow Matching Models
Apr 07, 2025
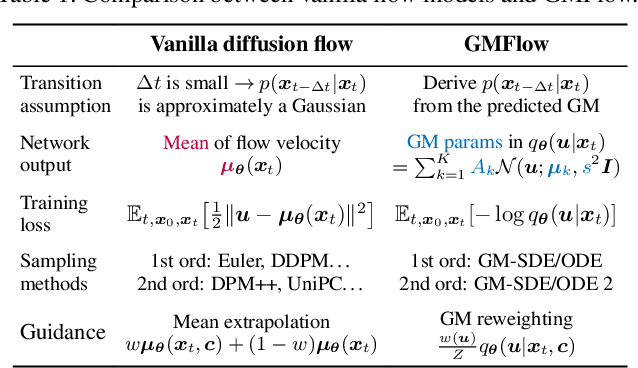

Diffusion models approximate the denoising distribution as a Gaussian and predict its mean, whereas flow matching models reparameterize the Gaussian mean as flow velocity. However, they underperform in few-step sampling due to discretization error and tend to produce over-saturated colors under classifier-free guidance (CFG). To address these limitations, we propose a novel Gaussian mixture flow matching (GMFlow) model: instead of predicting the mean, GMFlow predicts dynamic Gaussian mixture (GM) parameters to capture a multi-modal flow velocity distribution, which can be learned with a KL divergence loss. We demonstrate that GMFlow generalizes previous diffusion and flow matching models where a single Gaussian is learned with an $L_2$ denoising loss. For inference, we derive GM-SDE/ODE solvers that leverage analytic denoising distributions and velocity fields for precise few-step sampling. Furthermore, we introduce a novel probabilistic guidance scheme that mitigates the over-saturation issues of CFG and improves image generation quality. Extensive experiments demonstrate that GMFlow consistently outperforms flow matching baselines in generation quality, achieving a Precision of 0.942 with only 6 sampling steps on ImageNet 256$\times$256.
RigAnything: Template-Free Autoregressive Rigging for Diverse 3D Assets
Feb 13, 2025


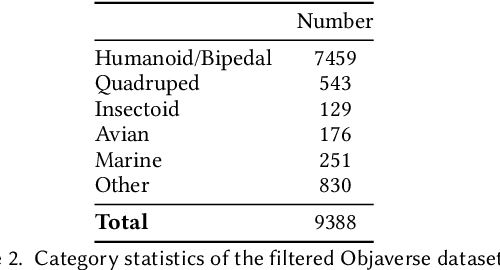
We present RigAnything, a novel autoregressive transformer-based model, which makes 3D assets rig-ready by probabilistically generating joints, skeleton topologies, and assigning skinning weights in a template-free manner. Unlike most existing auto-rigging methods, which rely on predefined skeleton template and are limited to specific categories like humanoid, RigAnything approaches the rigging problem in an autoregressive manner, iteratively predicting the next joint based on the global input shape and the previous prediction. While autoregressive models are typically used to generate sequential data, RigAnything extends their application to effectively learn and represent skeletons, which are inherently tree structures. To achieve this, we organize the joints in a breadth-first search (BFS) order, enabling the skeleton to be defined as a sequence of 3D locations and the parent index. Furthermore, our model improves the accuracy of position prediction by leveraging diffusion modeling, ensuring precise and consistent placement of joints within the hierarchy. This formulation allows the autoregressive model to efficiently capture both spatial and hierarchical relationships within the skeleton. Trained end-to-end on both RigNet and Objaverse datasets, RigAnything demonstrates state-of-the-art performance across diverse object types, including humanoids, quadrupeds, marine creatures, insects, and many more, surpassing prior methods in quality, robustness, generalizability, and efficiency. Please check our website for more details: https://www.liuisabella.com/RigAnything.
DMesh++: An Efficient Differentiable Mesh for Complex Shapes
Dec 21, 2024



Recent probabilistic methods for 3D triangular meshes capture diverse shapes by differentiable mesh connectivity, but face high computational costs with increased shape details. We introduce a new differentiable mesh processing method in 2D and 3D that addresses this challenge and efficiently handles meshes with intricate structures. Additionally, we present an algorithm that adapts the mesh resolution to local geometry in 2D for efficient representation. We demonstrate the effectiveness of our approach on 2D point cloud and 3D multi-view reconstruction tasks. Visit our project page (https://sonsang.github.io/dmesh2-project) for source code and supplementary material.
MegaSynth: Scaling Up 3D Scene Reconstruction with Synthesized Data
Dec 18, 2024



We propose scaling up 3D scene reconstruction by training with synthesized data. At the core of our work is MegaSynth, a procedurally generated 3D dataset comprising 700K scenes - over 50 times larger than the prior real dataset DL3DV - dramatically scaling the training data. To enable scalable data generation, our key idea is eliminating semantic information, removing the need to model complex semantic priors such as object affordances and scene composition. Instead, we model scenes with basic spatial structures and geometry primitives, offering scalability. Besides, we control data complexity to facilitate training while loosely aligning it with real-world data distribution to benefit real-world generalization. We explore training LRMs with both MegaSynth and available real data. Experiment results show that joint training or pre-training with MegaSynth improves reconstruction quality by 1.2 to 1.8 dB PSNR across diverse image domains. Moreover, models trained solely on MegaSynth perform comparably to those trained on real data, underscoring the low-level nature of 3D reconstruction. Additionally, we provide an in-depth analysis of MegaSynth's properties for enhancing model capability, training stability, and generalization.
Turbo3D: Ultra-fast Text-to-3D Generation
Dec 05, 2024



We present Turbo3D, an ultra-fast text-to-3D system capable of generating high-quality Gaussian splatting assets in under one second. Turbo3D employs a rapid 4-step, 4-view diffusion generator and an efficient feed-forward Gaussian reconstructor, both operating in latent space. The 4-step, 4-view generator is a student model distilled through a novel Dual-Teacher approach, which encourages the student to learn view consistency from a multi-view teacher and photo-realism from a single-view teacher. By shifting the Gaussian reconstructor's inputs from pixel space to latent space, we eliminate the extra image decoding time and halve the transformer sequence length for maximum efficiency. Our method demonstrates superior 3D generation results compared to previous baselines, while operating in a fraction of their runtime.
Buffer Anytime: Zero-Shot Video Depth and Normal from Image Priors
Nov 26, 2024We present Buffer Anytime, a framework for estimation of depth and normal maps (which we call geometric buffers) from video that eliminates the need for paired video--depth and video--normal training data. Instead of relying on large-scale annotated video datasets, we demonstrate high-quality video buffer estimation by leveraging single-image priors with temporal consistency constraints. Our zero-shot training strategy combines state-of-the-art image estimation models based on optical flow smoothness through a hybrid loss function, implemented via a lightweight temporal attention architecture. Applied to leading image models like Depth Anything V2 and Marigold-E2E-FT, our approach significantly improves temporal consistency while maintaining accuracy. Experiments show that our method not only outperforms image-based approaches but also achieves results comparable to state-of-the-art video models trained on large-scale paired video datasets, despite using no such paired video data.