 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipMap: Linear-Time Stateful 3D Reconstruction with Test-Time Training
Mar 04, 2026Feed-forward transformer models have driven rapid progress in 3D vision, but state-of-the-art methods such as VGGT and $π^3$ have a computational cost that scales quadratically with the number of input images, making them inefficient when applied to large image collections. Sequential-reconstruction approaches reduce this cost but sacrifice reconstruction quality. We introduce ZipMap, a stateful feed-forward model that achieves linear-time, bidirectional 3D reconstruction while matching or surpassing the accuracy of quadratic-time methods. ZipMap employs test-time training layers to zip an entire image collection into a compact hidden scene state in a single forward pass, enabling reconstruction of over 700 frames in under 10 seconds on a single H100 GPU, more than $20\times$ faster than state-of-the-art methods such as VGGT. Moreover, we demonstrate the benefits of having a stateful representation in real-time scene-state querying and its extension to sequential streaming reconstruction.
Large Video Planner Enables Generalizable Robot Control
Dec 17, 2025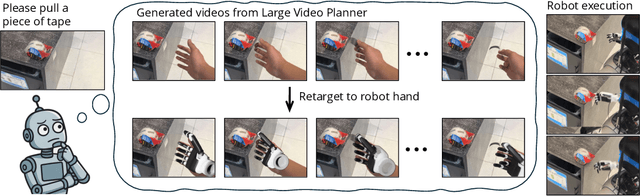
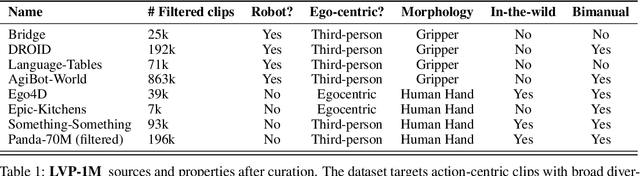

General-purpose robots require decision-making models that generalize across diverse tasks and environments. Recent works build robot foundation models by extending multimodal large language models (MLLMs) with action outputs, creating vision-language-action (VLA) systems. These efforts are motivated by the intuition that MLLMs' large-scale language and image pretraining can be effectively transferred to the action output modality. In this work, we explore an alternative paradigm of using large-scale video pretraining as a primary modality for building robot foundation models. Unlike static images and language, videos capture spatio-temporal sequences of states and actions in the physical world that are naturally aligned with robotic behavior. We curate an internet-scale video dataset of human activities and task demonstrations, and train, for the first time at a foundation-model scale, an open video model for generative robotics planning. The model produces zero-shot video plans for novel scenes and tasks, which we post-process to extract executable robot actions. We evaluate task-level generalization through third-party selected tasks in the wild and real-robot experiments, demonstrating successful physical execution. Together, these results show robust instruction following, strong generalization, and real-world feasibility. We release both the model and dataset to support open, reproducible video-based robot learning. Our website is available at https://www.boyuan.space/large-video-planner/.
Adversarial Generation and Collaborative Evolution of Safety-Critical Scenarios for Autonomous Vehicles
Aug 20, 2025The generation of safety-critical scenarios in simulation has become increasingly crucial for safety evaluation in autonomous vehicles prior to road deployment in society. However, current approaches largely rely on predefined threat patterns or rule-based strategies, which limit their ability to expose diverse and unforeseen failure modes. To overcome these, we propose ScenGE, a framework that can generate plentiful safety-critical scenarios by reasoning novel adversarial cases and then amplifying them with complex traffic flows. Given a simple prompt of a benign scene, it first performs Meta-Scenario Generation, where a large language model, grounded in structured driving knowledge, infers an adversarial agent whose behavior poses a threat that is both plausible and deliberately challenging. This meta-scenario is then specified in executable code for precise in-simulator control. Subsequently, Complex Scenario Evolution uses background vehicles to amplify the core threat introduced by Meta-Scenario. It builds an adversarial collaborator graph to identify key agent trajectories for optimization. These perturbations are designed to simultaneously reduce the ego vehicle's maneuvering space and create critical occlusions. Extensive experiments conducted on multiple reinforcement learning based AV models show that ScenGE uncovers more severe collision cases (+31.96%) on average than SoTA baselines. Additionally, our ScenGE can be applied to large model based AV systems and deployed on different simulators; we further observe that adversarial training on our scenarios improves the model robustness. Finally, we validate our framework through real-world vehicle tests and human evaluation, confirming that the generated scenarios are both plausible and critical. We hope our paper can build up a critical step towards building public trust and ensuring their safe deployment.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
Test-Time Training Done Right
May 29, 2025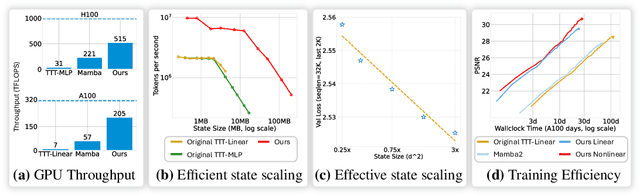

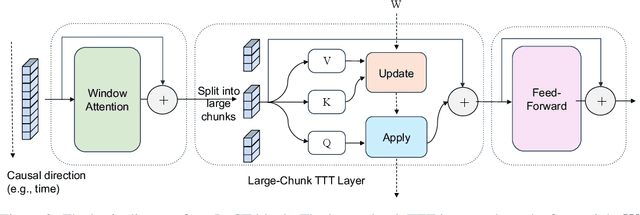
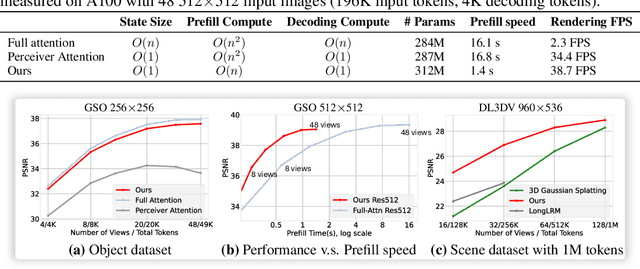
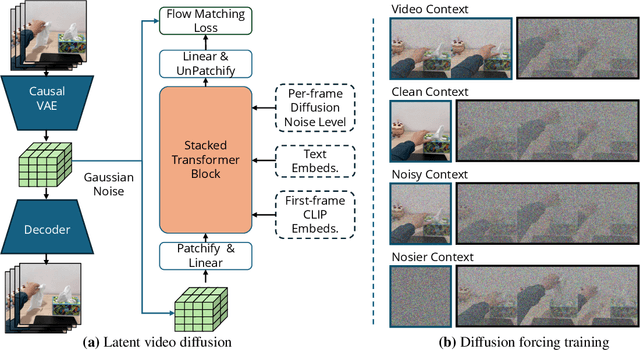
Test-Time Training (TTT) models context dependencies by adapting part of the model's weights (referred to as fast weights) during inference. This fast weight, akin to recurrent states in RNNs, stores temporary memories of past tokens in the current sequence. Existing TTT methods struggled to show effectiveness in handling long-context data, due to their inefficiency on modern GPUs. The TTT layers in many of these approaches operate with extremely low FLOPs utilization (often <5%) because they deliberately apply small online minibatch sizes (e.g., updating fast weights every 16 or 64 tokens). Moreover, a small minibatch implies fine-grained block-wise causal dependencies in the data, unsuitable for data beyond 1D ordered sequences, like sets or N-dimensional grids such as images or videos. In contrast, we pursue the opposite direction by using an extremely large chunk update, ranging from 2K to 1M tokens across tasks of varying modalities, which we refer to as Large Chunk Test-Time Training (LaCT). It improves hardware utilization by orders of magnitude, and more importantly, facilitates scaling of nonlinear state size (up to 40% of model parameters), hence substantially improving state capacity, all without requiring cumbersome and error-prone kernel implementations. It also allows easy integration of sophisticated optimizers, e.g. Muon for online updates. We validate our approach across diverse modalities and tasks, including novel view synthesis with image set, language models, and auto-regressive video diffusion. Our approach can scale up to 14B-parameter AR video diffusion model on sequences up to 56K tokens. In our longest sequence experiment, we perform novel view synthesis with 1 million context length. We hope this work will inspire and accelerate new research in the field of long-context modeling and test-time training. Website: https://tianyuanzhang.com/projects/ttt-done-right
Manipulating Multimodal Agents via Cross-Modal Prompt Injection
Apr 22, 2025The emergence of multimodal large language models has redefined the agent paradigm by integrating language and vision modalities with external data sources, enabling agents to better interpret human instructions and execute increasingly complex tasks. However, in this work, we identify a critical yet previously overlooked security vulnerability in multimodal agents: cross-modal prompt injection attacks. To exploit this vulnerability, we propose CrossInject, a novel attack framework in which attackers embed adversarial perturbations across multiple modalities to align with target malicious content, allowing external instructions to hijack the agent's decision-making process and execute unauthorized tasks. Our approach consists of two key components. First, we introduce Visual Latent Alignment, where we optimize adversarial features to the malicious instructions in the visual embedding space based on a text-to-image generative model, ensuring that adversarial images subtly encode cues for malicious task execution. Subsequently, we present Textual Guidance Enhancement, where a large language model is leveraged to infer the black-box defensive system prompt through adversarial meta prompting and generate an malicious textual command that steers the agent's output toward better compliance with attackers' requests. Extensive experiments demonstrate that our method outperforms existing injection attacks, achieving at least a +26.4% increase in attack success rates across diverse tasks. Furthermore, we validate our attack's effectiveness in real-world multimodal autonomous agents, highlighting its potential implications for safety-critical applications.
REG: Rectified Gradient Guidance for Conditional Diffusion Models
Jan 31, 2025Guidance techniques are simple yet effective for improving conditional generation in diffusion models. Albeit their empirical success, the practical implementation of guidance diverges significantly from its theoretical motivation. In this paper, we reconcile this discrepancy by replacing the scaled marginal distribution target, which we prove theoretically invalid, with a valid scaled joint distribution objective. Additionally, we show that the established guidance implementations are approximations to the intractable optimal solution under no future foresight constraint. Building on these theoretical insights, we propose rectified gradient guidance (REG), a versatile enhancement designed to boost the performance of existing guidance methods. Experiments on 1D and 2D demonstrate that REG provides a better approximation to the optimal solution than prior guidance techniques, validating the proposed theoretical framework. Extensive experiments on class-conditional ImageNet and text-to-image generation tasks show that incorporating REG consistently improves FID and Inception/CLIP scores across various settings compared to its absence.
RandAR: Decoder-only Autoregressive Visual Generation in Random Orders
Dec 02, 2024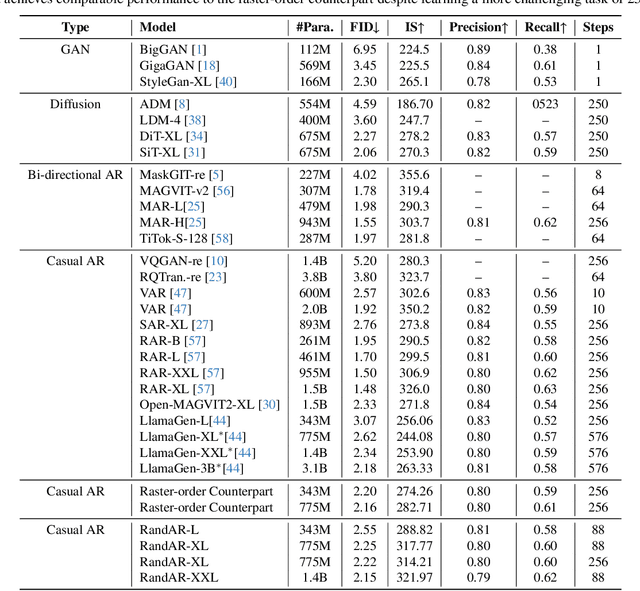
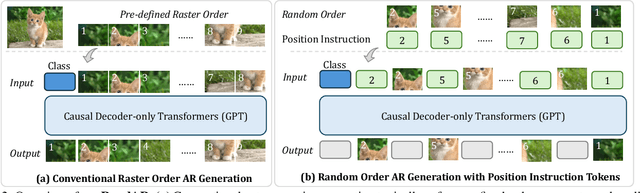
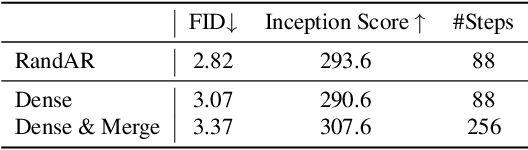
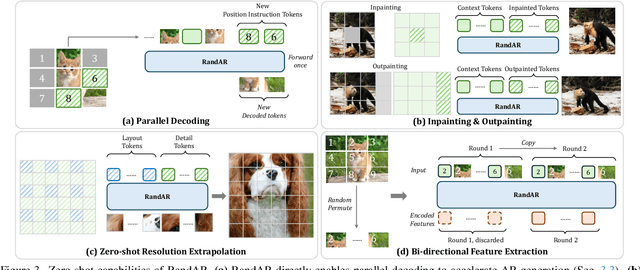
We introduce RandAR, a decoder-only visual autoregressive (AR) model capable of generating images in arbitrary token orders. Unlike previous decoder-only AR models that rely on a predefined generation order, RandAR removes this inductive bias, unlocking new capabilities in decoder-only generation. Our essential design enables random order by inserting a "position instruction token" before each image token to be predicted, representing the spatial location of the next image token. Trained on randomly permuted token sequences -- a more challenging task than fixed-order generation, RandAR achieves comparable performance to its conventional raster-order counterpart. More importantly, decoder-only transformers trained from random orders acquire new capabilities. For the efficiency bottleneck of AR models, RandAR adopts parallel decoding with KV-Cache at inference time, enjoying 2.5x acceleration without sacrificing generation quality. Additionally, RandAR supports inpainting, outpainting and resolution extrapolation in a zero-shot manner. We hope RandAR inspires new directions for decoder-only visual generation models and broadens their applications across diverse scenarios. Our project page is at https://rand-ar.github.io/.
Visual Adversarial Attack on Vision-Language Models for Autonomous Driving
Nov 27, 2024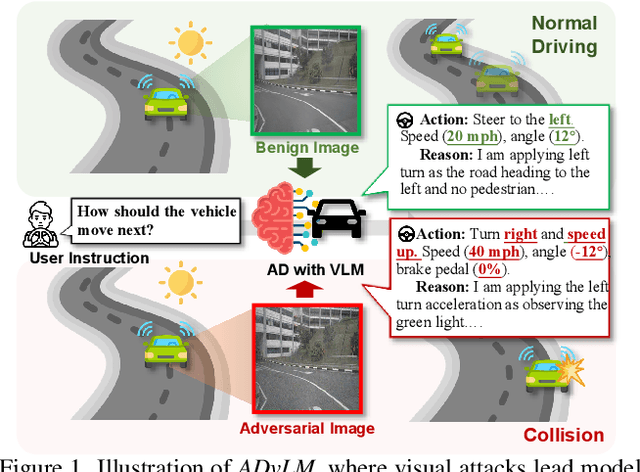

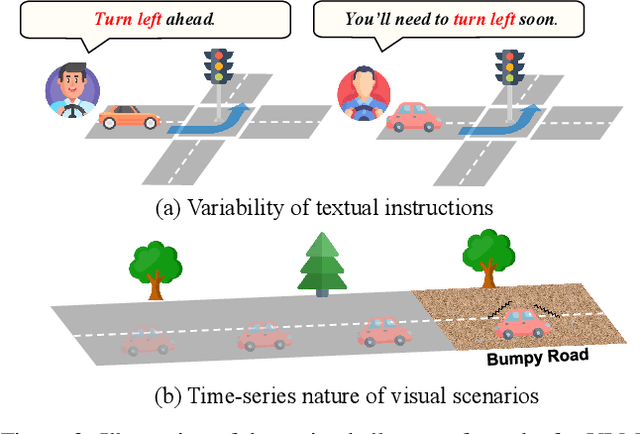

Vision-language models (VLMs) have significantly advanced autonomous driving (AD) by enhancing reasoning capabilities. However, these models remain highly vulnerable to adversarial attacks. While existing research has primarily focused on general VLM attacks, the development of attacks tailored to the safety-critical AD context has been largely overlooked. In this paper, we take the first step toward designing adversarial attacks specifically targeting VLMs in AD, exposing the substantial risks these attacks pose within this critical domain. We identify two unique challenges for effective adversarial attacks on AD VLMs: the variability of textual instructions and the time-series nature of visual scenarios. To this end, we propose ADvLM, the first visual adversarial attack framework specifically designed for VLMs in AD. Our framework introduces Semantic-Invariant Induction, which uses a large language model to create a diverse prompt library of textual instructions with consistent semantic content, guided by semantic entropy. Building on this, we introduce Scenario-Associated Enhancement, an approach where attention mechanisms select key frames and perspectives within driving scenarios to optimize adversarial perturbations that generalize across the entire scenario. Extensive experiments on several AD VLMs over multiple benchmarks show that ADvLM achieves state-of-the-art attack effectiveness. Moreover, real-world attack studies further validate its applicability and potential in practice.
Buffer Anytime: Zero-Shot Video Depth and Normal from Image Priors
Nov 26, 2024We present Buffer Anytime, a framework for estimation of depth and normal maps (which we call geometric buffers) from video that eliminates the need for paired video--depth and video--normal training data. Instead of relying on large-scale annotated video datasets, we demonstrate high-quality video buffer estimation by leveraging single-image priors with temporal consistency constraints. Our zero-shot training strategy combines state-of-the-art image estimation models based on optical flow smoothness through a hybrid loss function, implemented via a lightweight temporal attention architecture. Applied to leading image models like Depth Anything V2 and Marigold-E2E-FT, our approach significantly improves temporal consistency while maintaining accuracy. Experiments show that our method not only outperforms image-based approaches but also achieves results comparable to state-of-the-art video models trained on large-scale paired video datasets, despite using no such paired video data.