 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Adversarial Attack on Vision-Language Models for Autonomous Driving
Nov 27, 2024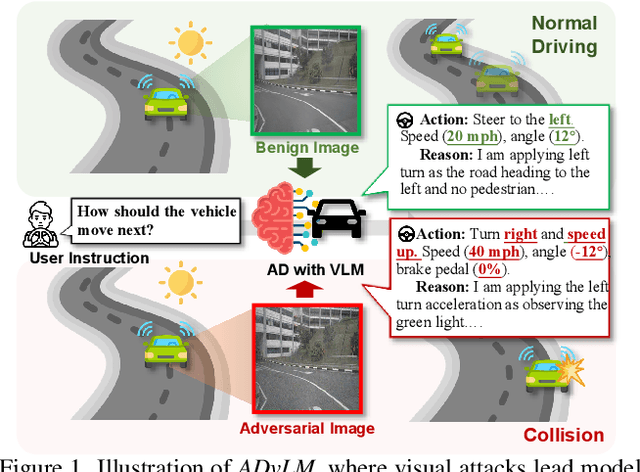

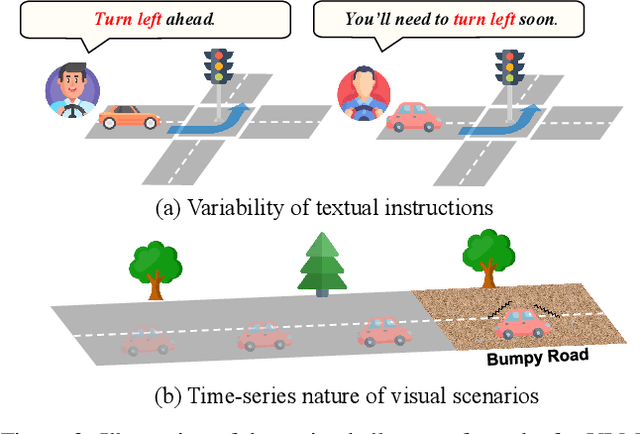

Vision-language models (VLMs) have significantly advanced autonomous driving (AD) by enhancing reasoning capabilities. However, these models remain highly vulnerable to adversarial attacks. While existing research has primarily focused on general VLM attacks, the development of attacks tailored to the safety-critical AD context has been largely overlooked. In this paper, we take the first step toward designing adversarial attacks specifically targeting VLMs in AD, exposing the substantial risks these attacks pose within this critical domain. We identify two unique challenges for effective adversarial attacks on AD VLMs: the variability of textual instructions and the time-series nature of visual scenarios. To this end, we propose ADvLM, the first visual adversarial attack framework specifically designed for VLMs in AD. Our framework introduces Semantic-Invariant Induction, which uses a large language model to create a diverse prompt library of textual instructions with consistent semantic content, guided by semantic entropy. Building on this, we introduce Scenario-Associated Enhancement, an approach where attention mechanisms select key frames and perspectives within driving scenarios to optimize adversarial perturbations that generalize across the entire scenario. Extensive experiments on several AD VLMs over multiple benchmarks show that ADvLM achieves state-of-the-art attack effectiveness. Moreover, real-world attack studies further validate its applicability and potential in practice.