 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDDM: Identity-Decoupled Personalized Diffusion Models with a Tunable Privacy-Utility Trade-off
Apr 01, 2026Personalized text-to-image diffusion models (e.g., DreamBooth, LoRA) enable users to synthesize high-fidelity avatars from a few reference photos for social expression. However, once these generations are shared on social media platforms (e.g., Instagram, Facebook), they can be linked to the real user via face recognition systems, enabling identity tracking and profiling. Existing defenses mainly follow an anti-personalization strategy that protects publicly released reference photos by disrupting model fine-tuning. While effective against unauthorized personalization, they do not address another practical setting in which personalization is authorized, but the resulting public outputs still leak identity information. To address this problem, we introduce a new defense setting, termed model-side output immunization, whose goal is to produce a personalized model that supports authorized personalization while reducing the identity linkability of public generations, with tunable control over the privacy-utility trade-off to accommodate diverse privacy needs. To this end, we propose Identity-Decoupled personalized Diffusion Models (IDDM), a model-side defense that integrates identity decoupling into the personalization pipeline. Concretely, IDDM follows an alternating procedure that interleaves short personalization updates with identity-decoupled data optimization, using a two-stage schedule to balance identity linkability suppression and generation utility. Extensive experiments across multiple datasets, diverse prompts, and state-of-the-art face recognition systems show that IDDM consistently reduces identity linkability while preserving high-quality personalized generation.
Understanding and Enhancing Encoder-based Adversarial Transferability against Large Vision-Language Models
Feb 10, 2026Large vision-language models (LVLMs) have achieved impressive success across multimodal tasks, but their reliance on visual inputs exposes them to significant adversarial threats. Existing encoder-based attacks perturb the input image by optimizing solely on the vision encoder, rather than the entire LVLM, offering a computationally efficient alternative to end-to-end optimization. However, their transferability across different LVLM architectures in realistic black-box scenarios remains poorly understood. To address this gap, we present the first systematic study towards encoder-based adversarial transferability in LVLMs. Our contributions are threefold. First, through large-scale benchmarking over eight diverse LVLMs, we reveal that existing attacks exhibit severely limited transferability. Second, we perform in-depth analysis, disclosing two root causes that hinder the transferability: (1) inconsistent visual grounding across models, where different models focus their attention on distinct regions; (2) redundant semantic alignment within models, where a single object is dispersed across multiple overlapping token representations. Third, we propose Semantic-Guided Multimodal Attack (SGMA), a novel framework to enhance the transferability. Inspired by the discovered causes in our analysis, SGMA directs perturbations toward semantically critical regions and disrupts cross-modal grounding at both global and local levels. Extensive experiments across different victim models and tasks show that SGMA achieves higher transferability than existing attacks. These results expose critical security risks in LVLM deployment and underscore the urgent need for robust multimodal defenses.
On the Adversarial Robustness of Large Vision-Language Models under Visual Token Compression
Jan 29, 2026Visual token compression is widely used to accelerate large vision-language models (LVLMs) by pruning or merging visual tokens, yet its adversarial robustness remains unexplored. We show that existing encoder-based attacks can substantially overestimate the robustness of compressed LVLMs, due to an optimization-inference mismatch: perturbations are optimized on the full-token representation, while inference is performed through a token-compression bottleneck. To address this gap, we propose the Compression-AliGnEd attack (CAGE), which aligns perturbation optimization with compression inference without assuming access to the deployed compression mechanism or its token budget. CAGE combines (i) expected feature disruption, which concentrates distortion on tokens likely to survive across plausible budgets, and (ii) rank distortion alignment, which actively aligns token distortions with rank scores to promote the retention of highly distorted evidence. Across diverse representative plug-and-play compression mechanisms and datasets, our results show that CAGE consistently achieves lower robust accuracy than the baseline. This work highlights that robustness assessments ignoring compression can be overly optimistic, calling for compression-aware security evaluation and defenses for efficient LVLMs.
Memory-Efficient Differentially Private Training with Gradient Random Projection
Jun 18, 2025Differential privacy (DP) protects sensitive data during neural network training, but standard methods like DP-Adam suffer from high memory overhead due to per-sample gradient clipping, limiting scalability. We introduce DP-GRAPE (Gradient RAndom ProjEction), a DP training method that significantly reduces memory usage while maintaining utility on par with first-order DP approaches. Rather than directly applying DP to GaLore, DP-GRAPE introduces three key modifications: (1) gradients are privatized after projection, (2) random Gaussian matrices replace SVD-based subspaces, and (3) projection is applied during backpropagation. These contributions eliminate the need for costly SVD computations, enable substantial memory savings, and lead to improved utility. Despite operating in lower-dimensional subspaces, our theoretical analysis shows that DP-GRAPE achieves a privacy-utility trade-off comparable to DP-SGD. Our extensive empirical experiments show that DP-GRAPE can reduce the memory footprint of DP training without sacrificing accuracy or training time. In particular, DP-GRAPE reduces memory usage by over 63% when pre-training Vision Transformers and over 70% when fine-tuning RoBERTa-Large as compared to DP-Adam, while achieving similar performance. We further demonstrate that DP-GRAPE scales to fine-tuning large models such as OPT with up to 6.7 billion parameters.
Visual Adversarial Attack on Vision-Language Models for Autonomous Driving
Nov 27, 2024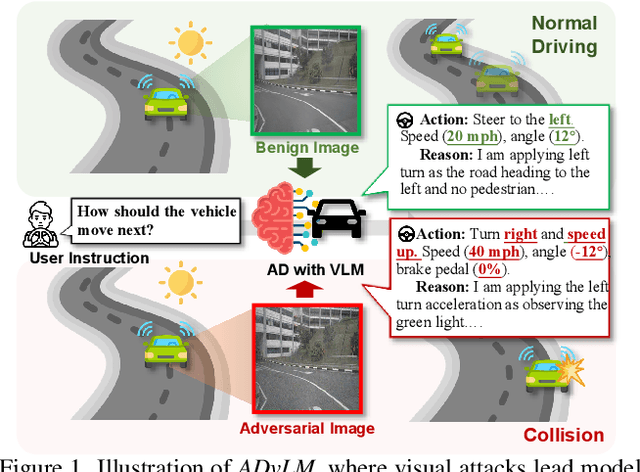

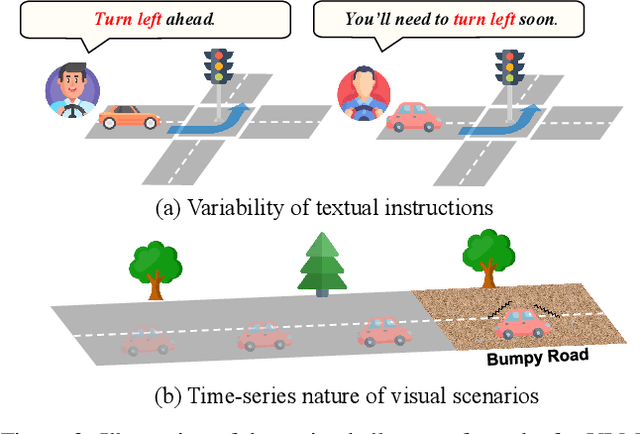

Vision-language models (VLMs) have significantly advanced autonomous driving (AD) by enhancing reasoning capabilities. However, these models remain highly vulnerable to adversarial attacks. While existing research has primarily focused on general VLM attacks, the development of attacks tailored to the safety-critical AD context has been largely overlooked. In this paper, we take the first step toward designing adversarial attacks specifically targeting VLMs in AD, exposing the substantial risks these attacks pose within this critical domain. We identify two unique challenges for effective adversarial attacks on AD VLMs: the variability of textual instructions and the time-series nature of visual scenarios. To this end, we propose ADvLM, the first visual adversarial attack framework specifically designed for VLMs in AD. Our framework introduces Semantic-Invariant Induction, which uses a large language model to create a diverse prompt library of textual instructions with consistent semantic content, guided by semantic entropy. Building on this, we introduce Scenario-Associated Enhancement, an approach where attention mechanisms select key frames and perspectives within driving scenarios to optimize adversarial perturbations that generalize across the entire scenario. Extensive experiments on several AD VLMs over multiple benchmarks show that ADvLM achieves state-of-the-art attack effectiveness. Moreover, real-world attack studies further validate its applicability and potential in practice.
Addax: Utilizing Zeroth-Order Gradients to Improve Memory Efficiency and Performance of SGD for Fine-Tuning Language Models
Oct 09, 2024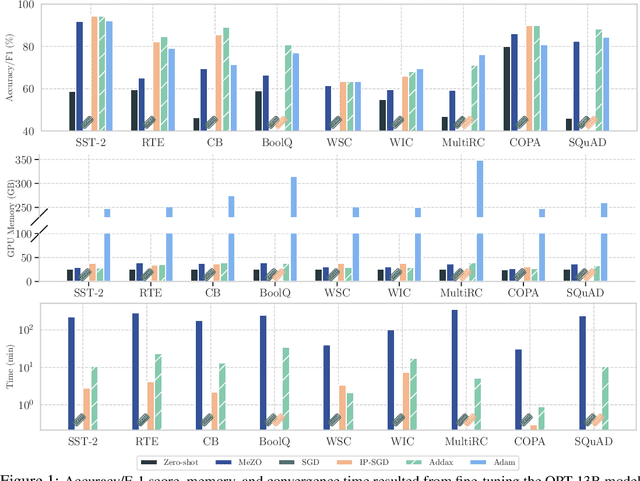

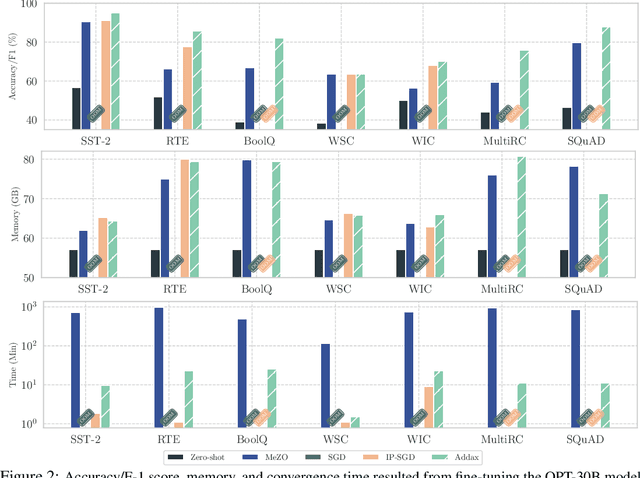

Fine-tuning language models (LMs) with the Adam optimizer often demands excessive memory, limiting accessibility. The "in-place" version of Stochastic Gradient Descent (IP-SGD) and Memory-Efficient Zeroth-order Optimizer (MeZO) have been proposed to address this. However, IP-SGD still requires substantial memory, and MeZO suffers from slow convergence and degraded final performance due to its zeroth-order nature. This paper introduces Addax, a novel method that improves both memory efficiency and performance of IP-SGD by integrating it with MeZO. Specifically, Addax computes zeroth- or first-order gradients of data points in the minibatch based on their memory consumption, combining these gradient estimates to update directions. By computing zeroth-order gradients for data points that require more memory and first-order gradients for others, Addax overcomes the slow convergence of MeZO and the excessive memory requirement of IP-SGD. Additionally, the zeroth-order gradient acts as a regularizer for the first-order gradient, further enhancing the model's final performance. Theoretically, we establish the convergence of Addax under mild assumptions, demonstrating faster convergence and less restrictive hyper-parameter choices than MeZO. Our experiments with diverse LMs and tasks show that Addax consistently outperforms MeZO regarding accuracy and convergence speed while having a comparable memory footprint. When fine-tuning OPT-13B with one A100 GPU, on average, Addax outperforms MeZO in accuracy/F1 score by 14% and runs 15x faster while using memory similar to MeZO. In our experiments on the larger OPT-30B model, on average, Addax outperforms MeZO in terms of accuracy/F1 score by >16 and runs 30x faster on a single H100 GPU. Moreover, Addax surpasses the performance of standard fine-tuning approaches, such as IP-SGD and Adam, in most tasks with significantly less memory requirement.
DiSK: Differentially Private Optimizer with Simplified Kalman Filter for Noise Reduction
Oct 04, 2024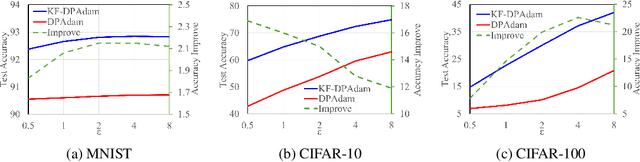
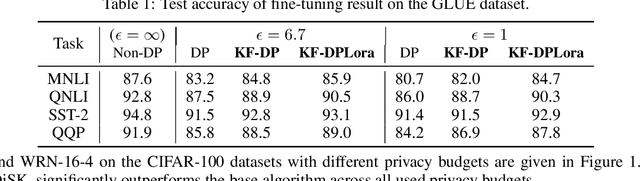
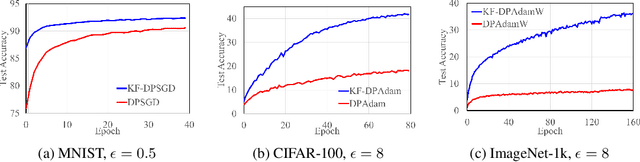
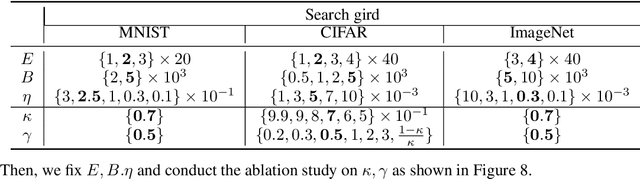
Differential privacy (DP) offers a robust framework for safeguarding individual data privacy. To utilize DP in training modern machine learning models, differentially private optimizers have been widely used in recent years. A popular approach to privatize an optimizer is to clip the individual gradients and add sufficiently large noise to the clipped gradient. This approach led to the development of DP optimizers that have comparable performance with their non-private counterparts in fine-tuning tasks or in tasks with a small number of training parameters. However, a significant performance drop is observed when these optimizers are applied to large-scale training. This degradation stems from the substantial noise injection required to maintain DP, which disrupts the optimizer's dynamics. This paper introduces DiSK, a novel framework designed to significantly enhance the performance of DP optimizers. DiSK employs Kalman filtering, a technique drawn from control and signal processing, to effectively denoise privatized gradients and generate progressively refined gradient estimations. To ensure practicality for large-scale training, we simplify the Kalman filtering process, minimizing its memory and computational demands. We establish theoretical privacy-utility trade-off guarantees for DiSK, and demonstrate provable improvements over standard DP optimizers like DPSGD in terms of iteration complexity upper-bound. Extensive experiments across diverse tasks, including vision tasks such as CIFAR-100 and ImageNet-1k and language fine-tuning tasks such as GLUE, E2E, and DART, validate the effectiveness of DiSK. The results showcase its ability to significantly improve the performance of DP optimizers, surpassing state-of-the-art results under the same privacy constraints on several benchmarks.
Module-wise Adaptive Adversarial Training for End-to-end Autonomous Driving
Sep 11, 2024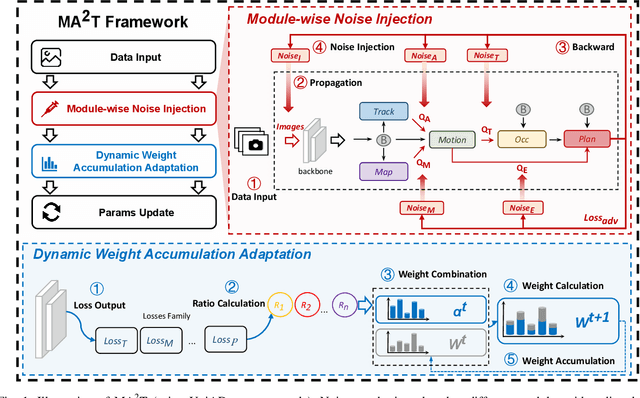
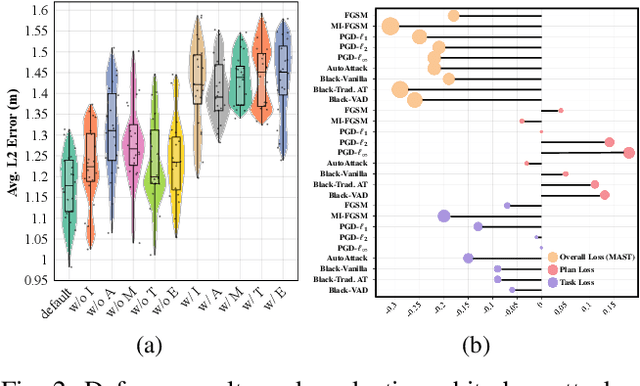
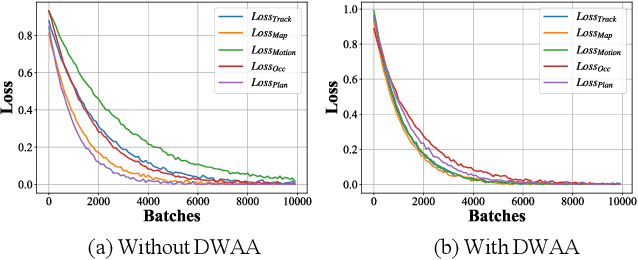
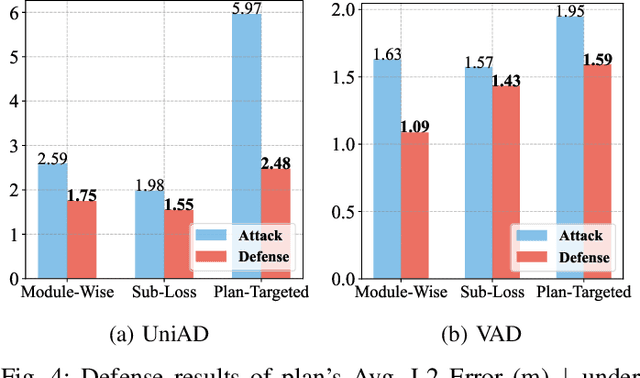
Recent advances in deep learning have markedly improved autonomous driving (AD) models, particularly end-to-end systems that integrate perception, prediction, and planning stages, achieving state-of-the-art performance. However, these models remain vulnerable to adversarial attacks, where human-imperceptible perturbations can disrupt decision-making processes. While adversarial training is an effective method for enhancing model robustness against such attacks, no prior studies have focused on its application to end-to-end AD models. In this paper, we take the first step in adversarial training for end-to-end AD models and present a novel Module-wise Adaptive Adversarial Training (MA2T). However, extending conventional adversarial training to this context is highly non-trivial, as different stages within the model have distinct objectives and are strongly interconnected. To address these challenges, MA2T first introduces Module-wise Noise Injection, which injects noise before the input of different modules, targeting training models with the guidance of overall objectives rather than each independent module loss. Additionally, we introduce Dynamic Weight Accumulation Adaptation, which incorporates accumulated weight changes to adaptively learn and adjust the loss weights of each module based on their contributions (accumulated reduction rates) for better balance and robust training. To demonstrate the efficacy of our defense, we conduct extensive experiments on the widely-used nuScenes dataset across several end-to-end AD models under both white-box and black-box attacks, where our method outperforms other baselines by large margins (+5-10%). Moreover, we validate the robustness of our defense through closed-loop evaluation in the CARLA simulation environment, showing improved resilience even against natural corruption.
DOPPLER: Differentially Private Optimizers with Low-pass Filter for Privacy Noise Reduction
Aug 24, 2024



Privacy is a growing concern in modern deep-learning systems and applications. Differentially private (DP) training prevents the leakage of sensitive information in the collected training data from the trained machine learning models. DP optimizers, including DP stochastic gradient descent (DPSGD) and its variants, privatize the training procedure by gradient clipping and DP noise injection. However, in practice, DP models trained using DPSGD and its variants often suffer from significant model performance degradation. Such degradation prevents the application of DP optimization in many key tasks, such as foundation model pretraining. In this paper, we provide a novel signal processing perspective to the design and analysis of DP optimizers. We show that a ``frequency domain'' operation called low-pass filtering can be used to effectively reduce the impact of DP noise. More specifically, by defining the ``frequency domain'' for both the gradient and differential privacy (DP) noise, we have developed a new component, called DOPPLER. This component is designed for DP algorithms and works by effectively amplifying the gradient while suppressing DP noise within this frequency domain. As a result, it maintains privacy guarantees and enhances the quality of the DP-protected model. Our experiments show that the proposed DP optimizers with a low-pass filter outperform their counterparts without the filter by 3%-10% in test accuracy on various models and datasets. Both theoretical and practical evidence suggest that the DOPPLER is effective in closing the gap between DP and non-DP training.
UniT: Unified Tactile Representation for Robot Learning
Aug 12, 2024



UniT is a novel approach to tactile representation learning, using VQVAE to learn a compact latent space and serve as the tactile representation. It uses tactile images obtained from a single simple object to train the representation with transferability and generalizability. This tactile representation can be zero-shot transferred to various downstream tasks, including perception tasks and manipulation policy learning. Our benchmarking on an in-hand 3D pose estimation task shows that UniT outperforms existing visual and tactile representation learning methods. Additionally, UniT's effectiveness in policy learning is demonstrated across three real-world tasks involving diverse manipulated objects and complex robot-object-environment interactions. Through extensive experimentation, UniT is shown to be a simple-to-train, plug-and-play, yet widely effective method for tactile representation learning. For more details, please refer to our open-source repository https://github.com/ZhengtongXu/UniT and the project website https://zhengtongxu.github.io/unifiedtactile.github.io/.