 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-level Large Language Model Training with Contrastive Preference Optimization
Feb 23, 2025



The next token prediction loss is the dominant self-supervised training objective for large language models and has achieved promising results in a variety of downstream tasks. However, upon closer investigation of this objective, we find that it lacks an understanding of sequence-level signals, leading to a mismatch between training and inference processes. To bridge this gap, we introduce a contrastive preference optimization (CPO) procedure that can inject sequence-level information into the language model at any training stage without expensive human labeled data. Our experiments show that the proposed objective surpasses the next token prediction in terms of win rate in the instruction-following and text generation tasks.
Revisiting SMoE Language Models by Evaluating Inefficiencies with Task Specific Expert Pruning
Sep 02, 2024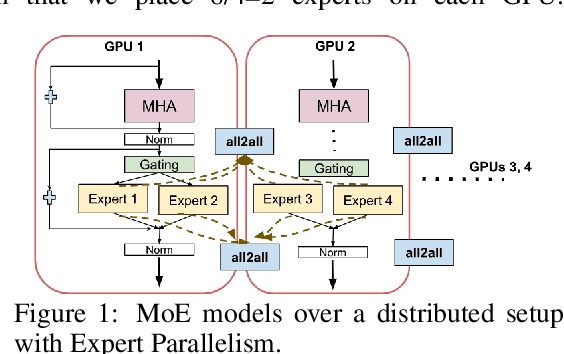

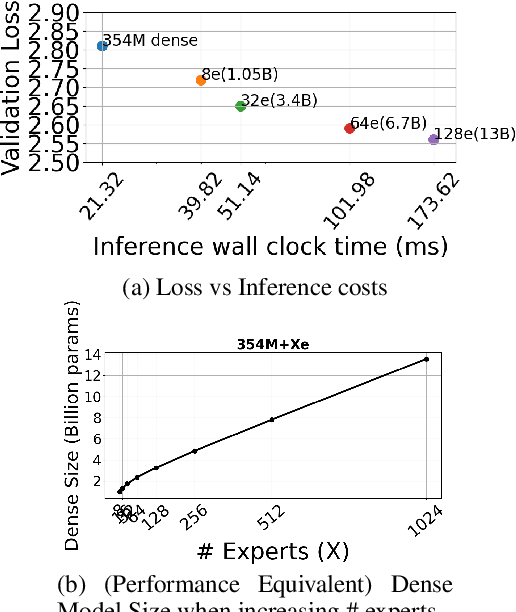
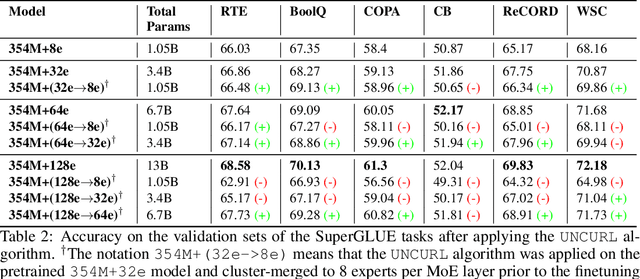
Sparse Mixture of Expert (SMoE) models have emerged as a scalable alternative to dense models in language modeling. These models use conditionally activated feedforward subnetworks in transformer blocks, allowing for a separation between total model parameters and per-example computation. However, large token-routed SMoE models face a significant challenge: during inference, the entire model must be used for a sequence or a batch, resulting in high latencies in a distributed setting that offsets the advantages of per-token sparse activation. Our research explores task-specific model pruning to inform decisions about designing SMoE architectures, mainly modulating the choice of expert counts in pretraining. We investigate whether such pruned models offer advantages over smaller SMoE models trained from scratch, when evaluating and comparing them individually on tasks. To that end, we introduce an adaptive task-aware pruning technique UNCURL to reduce the number of experts per MoE layer in an offline manner post-training. Our findings reveal a threshold pruning factor for the reduction that depends on the number of experts used in pretraining, above which, the reduction starts to degrade model performance. These insights contribute to our understanding of model design choices when pretraining with SMoE architectures, particularly useful when considering task-specific inference optimization for later stages.
DEM: Distribution Edited Model for Training with Mixed Data Distributions
Jun 21, 2024



Training with mixed data distributions is a common and important part of creating multi-task and instruction-following models. The diversity of the data distributions and cost of joint training makes the optimization procedure extremely challenging. Data mixing methods partially address this problem, albeit having a sub-optimal performance across data sources and require multiple expensive training runs. In this paper, we propose a simple and efficient alternative for better optimization of the data sources by combining models individually trained on each data source with the base model using basic element-wise vector operations. The resulting model, namely Distribution Edited Model (DEM), is 11x cheaper than standard data mixing and outperforms strong baselines on a variety of benchmarks, yielding up to 6.2% improvement on MMLU, 11.5% on BBH, 16.1% on DROP, and 9.3% on HELM with models of size 3B to 13B. Notably, DEM does not require full re-training when modifying a single data-source, thus making it very flexible and scalable for training with diverse data sources.
Pre-training Differentially Private Models with Limited Public Data
Feb 28, 2024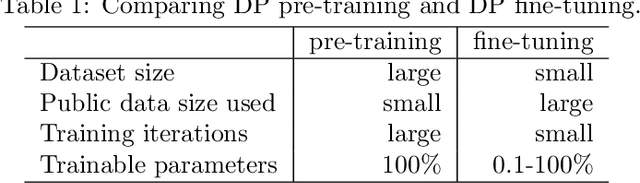
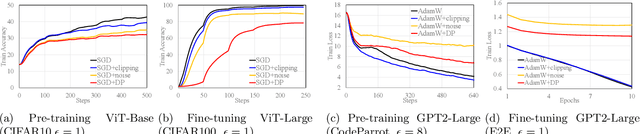
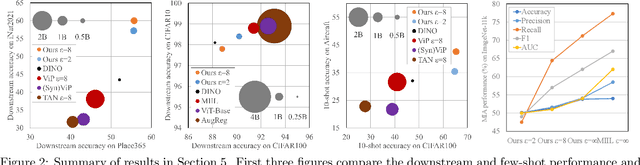
The superior performance of large foundation models relies on the use of massive amounts of high-quality data, which often contain sensitive, private and copyrighted material that requires formal protection. While differential privacy (DP) is a prominent method to gauge the degree of security provided to the models, its application is commonly limited to the model fine-tuning stage, due to the performance degradation when applying DP during the pre-training stage. Consequently, DP is yet not capable of protecting a substantial portion of the data used during the initial pre-training process. In this work, we first provide a theoretical understanding of the efficacy of DP training by analyzing the per-iteration loss improvement. We make a key observation that DP optimizers' performance degradation can be significantly mitigated by the use of limited public data, which leads to a novel DP continual pre-training strategy. Empirically, using only 10\% of public data, our strategy can achieve DP accuracy of 41.5\% on ImageNet-21k (with $\epsilon=8$), as well as non-DP accuracy of 55.7\% and and 60.0\% on downstream tasks Places365 and iNaturalist-2021, respectively, on par with state-of-the-art standard pre-training and substantially outperforming existing DP pre-trained models.
Extreme Miscalibration and the Illusion of Adversarial Robustness
Feb 27, 2024Deep learning-based Natural Language Processing (NLP) models are vulnerable to adversarial attacks, where small perturbations can cause a model to misclassify. Adversarial Training (AT) is often used to increase model robustness. However, we have discovered an intriguing phenomenon: deliberately or accidentally miscalibrating models masks gradients in a way that interferes with adversarial attack search methods, giving rise to an apparent increase in robustness. We show that this observed gain in robustness is an illusion of robustness (IOR), and demonstrate how an adversary can perform various forms of test-time temperature calibration to nullify the aforementioned interference and allow the adversarial attack to find adversarial examples. Hence, we urge the NLP community to incorporate test-time temperature scaling into their robustness evaluations to ensure that any observed gains are genuine. Finally, we show how the temperature can be scaled during \textit{training} to improve genuine robustness.
Zero redundancy distributed learning with differential privacy
Nov 20, 2023
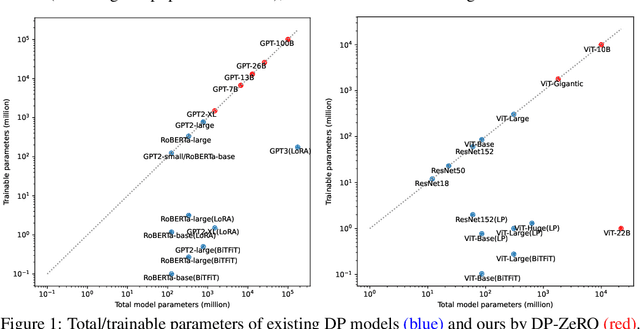

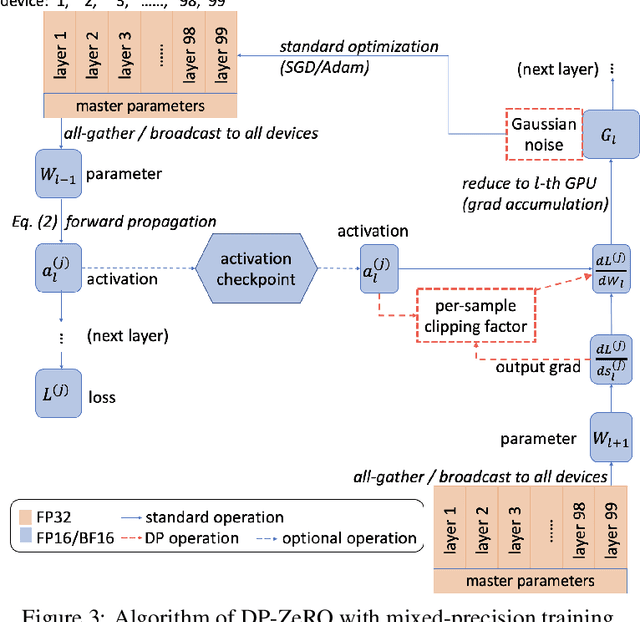
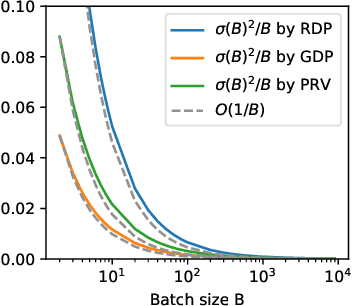
Deep learning using large models have achieved great success in a wide range of domains. However, training these models on billions of parameters is very challenging in terms of the training speed, memory cost, and communication efficiency, especially under the privacy-preserving regime with differential privacy (DP). On the one hand, DP optimization has comparable efficiency to the standard non-private optimization on a single GPU, but on multiple GPUs, existing DP distributed learning (such as pipeline parallel) has suffered from significantly worse efficiency. On the other hand, the Zero Redundancy Optimizer (ZeRO) is a state-of-the-art solution to the standard distributed learning, exhibiting excellent training efficiency on large models, but to work compatibly with DP is technically complicated. In this work, we develop a new systematic solution, DP-ZeRO, (I) to scale up the trainable DP model size, e.g. to GPT-100B, (II) to obtain the same computation and communication efficiency as the standard ZeRO, and (III) to enable mixed-precision DP training. Our DP-ZeRO, like the standard ZeRO, has the potential to train models with arbitrary size and is evaluated on the world's largest DP models in terms of the number of trainable parameters.
On the accuracy and efficiency of group-wise clipping in differentially private optimization
Oct 30, 2023



Recent advances have substantially improved the accuracy, memory cost, and training speed of differentially private (DP) deep learning, especially on large vision and language models with millions to billions of parameters. In this work, we thoroughly study the per-sample gradient clipping style, a key component in DP optimization. We show that different clipping styles have the same time complexity but instantiate an accuracy-memory trade-off: while the all-layer clipping (of coarse granularity) is the most prevalent and usually gives the best accuracy, it incurs heavier memory cost compared to other group-wise clipping, such as the layer-wise clipping (of finer granularity). We formalize this trade-off through our convergence theory and complexity analysis. Importantly, we demonstrate that the accuracy gap between group-wise clipping and all-layer clipping becomes smaller for larger models, while the memory advantage of the group-wise clipping remains. Consequently, the group-wise clipping allows DP optimization of large models to achieve high accuracy and low peak memory simultaneously.
Efficient Long-Range Transformers: You Need to Attend More, but Not Necessarily at Every Layer
Oct 19, 2023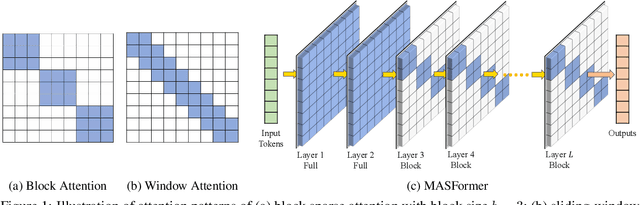
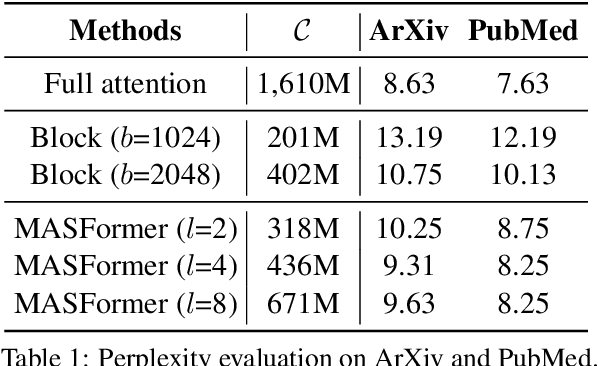
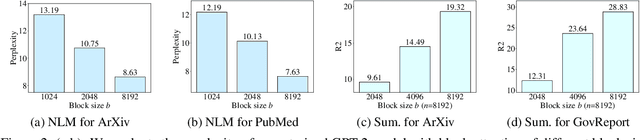
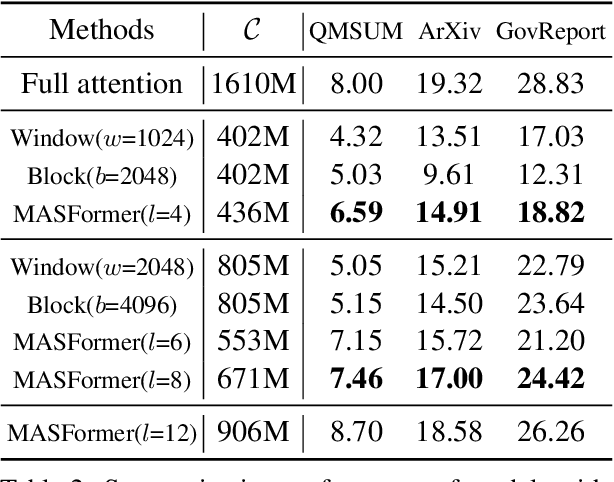
Pretrained transformer models have demonstrated remarkable performance across various natural language processing tasks. These models leverage the attention mechanism to capture long- and short-range dependencies in the sequence. However, the (full) attention mechanism incurs high computational cost - quadratic in the sequence length, which is not affordable in tasks with long sequences, e.g., inputs with 8k tokens. Although sparse attention can be used to improve computational efficiency, as suggested in existing work, it has limited modeling capacity and often fails to capture complicated dependencies in long sequences. To tackle this challenge, we propose MASFormer, an easy-to-implement transformer variant with Mixed Attention Spans. Specifically, MASFormer is equipped with full attention to capture long-range dependencies, but only at a small number of layers. For the remaining layers, MASformer only employs sparse attention to capture short-range dependencies. Our experiments on natural language modeling and generation tasks show that a decoder-only MASFormer model of 1.3B parameters can achieve competitive performance to vanilla transformers with full attention while significantly reducing computational cost (up to 75%). Additionally, we investigate the effectiveness of continual training with long sequence data and how sequence length impacts downstream generation performance, which may be of independent interest.
Coupling public and private gradient provably helps optimization
Oct 02, 2023The success of large neural networks is crucially determined by the availability of data. It has been observed that training only on a small amount of public data, or privately on the abundant private data can lead to undesirable degradation of accuracy. In this work, we leverage both private and public data to improve the optimization, by coupling their gradients via a weighted linear combination. We formulate an optimal solution for the optimal weight in the convex setting to indicate that the weighting coefficient should be hyperparameter-dependent. Then, we prove the acceleration in the convergence of non-convex loss and the effects of hyper-parameters such as privacy budget, number of iterations, batch size, and model size on the choice of the weighting coefficient. We support our analysis with empirical experiments across language and vision benchmarks, and provide a guideline for choosing the optimal weight of the gradient coupling.
HYTREL: Hypergraph-enhanced Tabular Data Representation Learning
Jul 14, 2023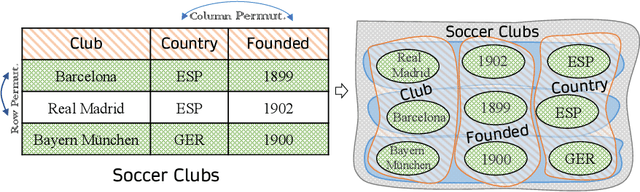
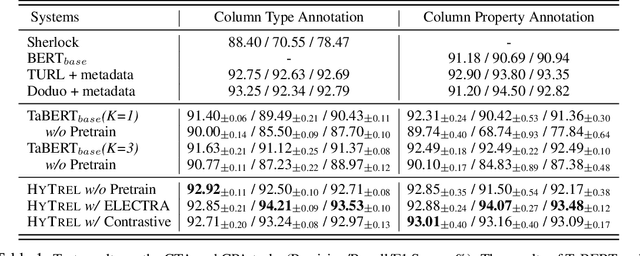
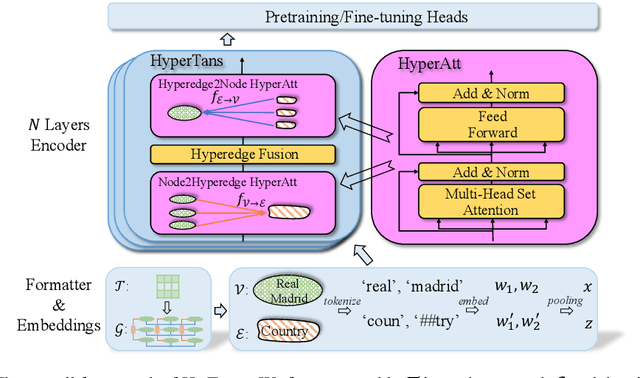
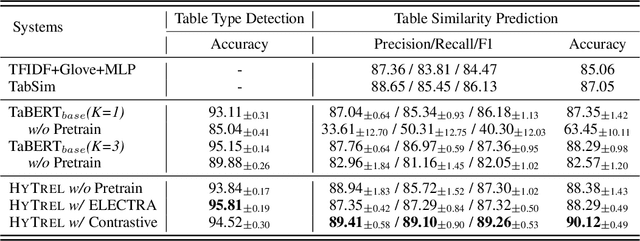
Language models pretrained on large collections of tabular data have demonstrated their effectiveness in several downstream tasks. However, many of these models do not take into account the row/column permutation invariances, hierarchical structure, etc. that exist in tabular data. To alleviate these limitations, we propose HYTREL, a tabular language model, that captures the permutation invariances and three more structural properties of tabular data by using hypergraphs - where the table cells make up the nodes and the cells occurring jointly together in each row, column, and the entire table are used to form three different types of hyperedges. We show that HYTREL is maximally invariant under certain conditions for tabular data, i.e., two tables obtain the same representations via HYTREL iff the two tables are identical up to permutations. Our empirical results demonstrate that HYTREL consistently outperforms other competitive baselines on four downstream tasks with minimal pretraining, illustrating the advantages of incorporating the inductive biases associated with tabular data into the representations. Finally, our qualitative analyses showcase that HYTREL can assimilate the table structures to generate robust representations for the cells, rows, columns, and the entire table.