 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsk a Strong LLM Judge when Your Reward Model is Uncertain
Oct 23, 2025Reward model (RM) plays a pivotal role in reinforcement learning with human feedback (RLHF) for aligning large language models (LLMs). However, classical RMs trained on human preferences are vulnerable to reward hacking and generalize poorly to out-of-distribution (OOD) inputs. By contrast, strong LLM judges equipped with reasoning capabilities demonstrate superior generalization, even without additional training, but incur significantly higher inference costs, limiting their applicability in online RLHF. In this work, we propose an uncertainty-based routing framework that efficiently complements a fast RM with a strong but costly LLM judge. Our approach formulates advantage estimation in policy gradient (PG) methods as pairwise preference classification, enabling principled uncertainty quantification to guide routing. Uncertain pairs are forwarded to the LLM judge, while confident ones are evaluated by the RM. Experiments on RM benchmarks demonstrate that our uncertainty-based routing strategy significantly outperforms random judge calling at the same cost, and downstream alignment results showcase its effectiveness in improving online RLHF.
Win Fast or Lose Slow: Balancing Speed and Accuracy in Latency-Sensitive Decisions of LLMs
May 26, 2025Large language models (LLMs) have shown remarkable performance across diverse reasoning and generation tasks, and are increasingly deployed as agents in dynamic environments such as code generation and recommendation systems. However, many real-world applications, such as high-frequency trading and real-time competitive gaming, require decisions under strict latency constraints, where faster responses directly translate into higher rewards. Despite the importance of this latency quality trade off, it remains underexplored in the context of LLM based agents. In this work, we present the first systematic study of this trade off in real time decision making tasks. To support our investigation, we introduce two new benchmarks: HFTBench, a high frequency trading simulation, and StreetFighter, a competitive gaming platform. Our analysis reveals that optimal latency quality balance varies by task, and that sacrificing quality for lower latency can significantly enhance downstream performance. To address this, we propose FPX, an adaptive framework that dynamically selects model size and quantization level based on real time demands. Our method achieves the best performance on both benchmarks, improving win rate by up to 80% in Street Fighter and boosting daily yield by up to 26.52% in trading, underscoring the need for latency aware evaluation and deployment strategies for LLM based agents. These results demonstrate the critical importance of latency aware evaluation and deployment strategies for real world LLM based agents. Our benchmarks are available at Latency Sensitive Benchmarks.
Think-RM: Enabling Long-Horizon Reasoning in Generative Reward Models
May 22, 2025Reinforcement learning from human feedback (RLHF) has become a powerful post-training paradigm for aligning large language models with human preferences. A core challenge in RLHF is constructing accurate reward signals, where the conventional Bradley-Terry reward models (BT RMs) often suffer from sensitivity to data size and coverage, as well as vulnerability to reward hacking. Generative reward models (GenRMs) offer a more robust alternative by generating chain-of-thought (CoT) rationales followed by a final reward. However, existing GenRMs rely on shallow, vertically scaled reasoning, limiting their capacity to handle nuanced or complex (e.g., reasoning-intensive) tasks. Moreover, their pairwise preference outputs are incompatible with standard RLHF algorithms that require pointwise reward signals. In this work, we introduce Think-RM, a training framework that enables long-horizon reasoning in GenRMs by modeling an internal thinking process. Rather than producing structured, externally provided rationales, Think-RM generates flexible, self-guided reasoning traces that support advanced capabilities such as self-reflection, hypothetical reasoning, and divergent reasoning. To elicit these reasoning abilities, we first warm-up the models by supervised fine-tuning (SFT) over long CoT data. We then further improve the model's long-horizon abilities by rule-based reinforcement learning (RL). In addition, we propose a novel pairwise RLHF pipeline that directly optimizes policies using pairwise preference rewards, eliminating the need for pointwise reward conversion and enabling more effective use of Think-RM outputs. Experiments show that Think-RM achieves state-of-the-art results on RM-Bench, outperforming both BT RM and vertically scaled GenRM by 8%. When combined with our pairwise RLHF pipeline, it demonstrates superior end-policy performance compared to traditional approaches.
Model Tells Itself Where to Attend: Faithfulness Meets Automatic Attention Steering
Sep 16, 2024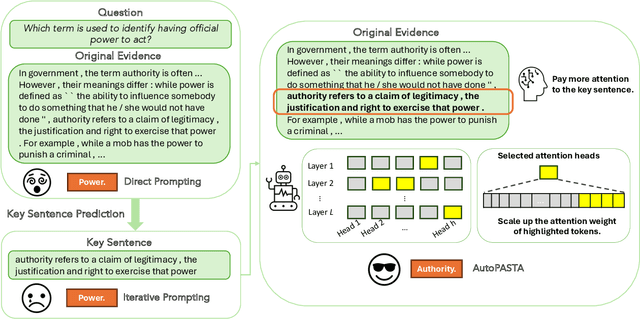

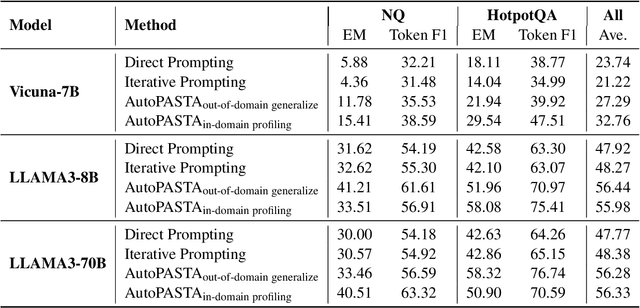
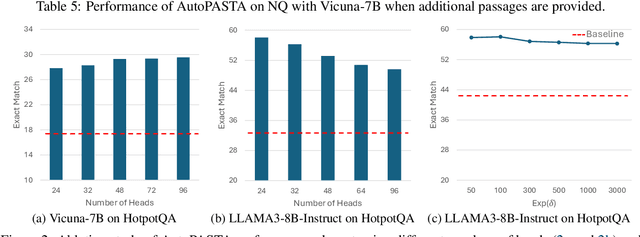
Large language models (LLMs) have demonstrated remarkable performance across various real-world tasks. However, they often struggle to fully comprehend and effectively utilize their input contexts, resulting in responses that are unfaithful or hallucinated. This difficulty increases for contexts that are long or contain distracting information, which can divert LLMs from fully capturing essential evidence. To address this issue, many works use prompting to help LLMs utilize contextual information more faithfully. For instance, iterative prompting highlights key information in two steps that first ask the LLM to identify important pieces of context and then derive answers accordingly. However, prompting methods are constrained to highlighting key information implicitly in token space, which is often insufficient to fully steer the model's attention. To improve model faithfulness more reliably, we propose AutoPASTA, a method that automatically identifies key contextual information and explicitly highlights it by steering an LLM's attention scores. Like prompting, AutoPASTA is applied at inference time and does not require changing any model parameters. Our experiments on open-book QA demonstrate that AutoPASTA effectively enables models to grasp essential contextual information, leading to substantially improved model faithfulness and performance, e.g., an average improvement of 7.95% for LLAMA3-70B-Instruct. Code will be publicly available at https://github.com/QingruZhang/AutoPASTA .
Robust Reinforcement Learning from Corrupted Human Feedback
Jun 21, 2024Reinforcement learning from human feedback (RLHF) provides a principled framework for aligning AI systems with human preference data. For various reasons, e.g., personal bias, context ambiguity, lack of training, etc, human annotators may give incorrect or inconsistent preference labels. To tackle this challenge, we propose a robust RLHF approach -- $R^3M$, which models the potentially corrupted preference label as sparse outliers. Accordingly, we formulate the robust reward learning as an $\ell_1$-regularized maximum likelihood estimation problem. Computationally, we develop an efficient alternating optimization algorithm, which only incurs negligible computational overhead compared with the standard RLHF approach. Theoretically, we prove that under proper regularity conditions, $R^3M$ can consistently learn the underlying reward and identify outliers, provided that the number of outlier labels scales sublinearly with the preference sample size. Furthermore, we remark that $R^3M$ is versatile and can be extended to various preference optimization methods, including direct preference optimization (DPO). Our experiments on robotic control and natural language generation with large language models (LLMs) show that $R^3M$ improves robustness of the reward against several types of perturbations to the preference data.
GEAR: An Efficient KV Cache Compression Recipe for Near-Lossless Generative Inference of LLM
Mar 11, 2024



Key-value (KV) caching has become the de-facto to accelerate generation speed for large language models (LLMs) inference. However, the growing cache demand with increasing sequence length has transformed LLM inference to be a memory bound problem, significantly constraining the system throughput. Existing methods rely on dropping unimportant tokens or quantizing all entries uniformly. Such methods, however, often incur high approximation errors to represent the compressed matrices. The autoregressive decoding process further compounds the error of each step, resulting in critical deviation in model generation and deterioration of performance. To tackle this challenge, we propose GEAR, an efficient KV cache compression framework that achieves near-lossless high-ratio compression. GEAR first applies quantization to majority of entries of similar magnitudes to ultra-low precision. It then employs a low rank matrix to approximate the quantization error, and a sparse matrix to remedy individual errors from outlier entries. By adeptly integrating three techniques, GEAR is able to fully exploit their synergistic potentials. Our experiments demonstrate that compared to alternatives, GEAR achieves near-lossless 4-bit KV cache compression with up to 2.38x throughput improvement, while reducing peak-memory size up to 2.29x. Our code is publicly available at https://github.com/HaoKang-Timmy/GEAR.
Tell Your Model Where to Attend: Post-hoc Attention Steering for LLMs
Nov 03, 2023


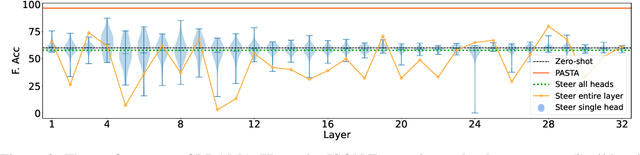
In human-written articles, we often leverage the subtleties of text style, such as bold and italics, to guide the attention of readers. These textual emphases are vital for the readers to grasp the conveyed information. When interacting with large language models (LLMs), we have a similar need - steering the model to pay closer attention to user-specified information, e.g., an instruction. Existing methods, however, are constrained to process plain text and do not support such a mechanism. This motivates us to introduce PASTA - Post-hoc Attention STeering Approach, a method that allows LLMs to read text with user-specified emphasis marks. To this end, PASTA identifies a small subset of attention heads and applies precise attention reweighting on them, directing the model attention to user-specified parts. Like prompting, PASTA is applied at inference time and does not require changing any model parameters. Experiments demonstrate that PASTA can substantially enhance an LLM's ability to follow user instructions or integrate new knowledge from user inputs, leading to a significant performance improvement on a variety of tasks, e.g., an average accuracy improvement of 22% for LLAMA-7B. Our code is publicly available at https://github.com/QingruZhang/PASTA .
Efficient Long-Range Transformers: You Need to Attend More, but Not Necessarily at Every Layer
Oct 19, 2023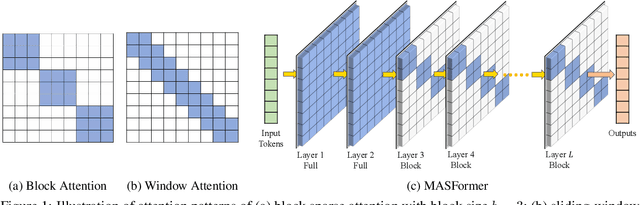
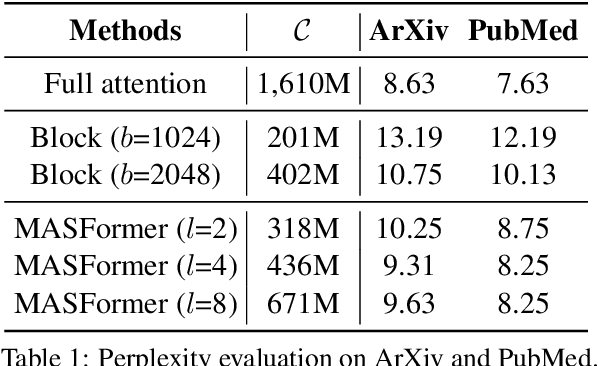
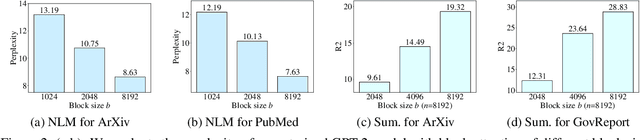
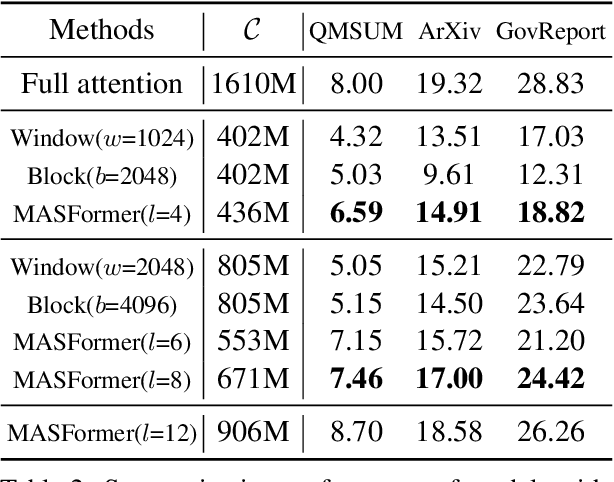
Pretrained transformer models have demonstrated remarkable performance across various natural language processing tasks. These models leverage the attention mechanism to capture long- and short-range dependencies in the sequence. However, the (full) attention mechanism incurs high computational cost - quadratic in the sequence length, which is not affordable in tasks with long sequences, e.g., inputs with 8k tokens. Although sparse attention can be used to improve computational efficiency, as suggested in existing work, it has limited modeling capacity and often fails to capture complicated dependencies in long sequences. To tackle this challenge, we propose MASFormer, an easy-to-implement transformer variant with Mixed Attention Spans. Specifically, MASFormer is equipped with full attention to capture long-range dependencies, but only at a small number of layers. For the remaining layers, MASformer only employs sparse attention to capture short-range dependencies. Our experiments on natural language modeling and generation tasks show that a decoder-only MASFormer model of 1.3B parameters can achieve competitive performance to vanilla transformers with full attention while significantly reducing computational cost (up to 75%). Additionally, we investigate the effectiveness of continual training with long sequence data and how sequence length impacts downstream generation performance, which may be of independent interest.
Robust Multi-Agent Reinforcement Learning via Adversarial Regularization: Theoretical Foundation and Stable Algorithms
Oct 16, 2023Multi-Agent Reinforcement Learning (MARL) has shown promising results across several domains. Despite this promise, MARL policies often lack robustness and are therefore sensitive to small changes in their environment. This presents a serious concern for the real world deployment of MARL algorithms, where the testing environment may slightly differ from the training environment. In this work we show that we can gain robustness by controlling a policy's Lipschitz constant, and under mild conditions, establish the existence of a Lipschitz and close-to-optimal policy. Based on these insights, we propose a new robust MARL framework, ERNIE, that promotes the Lipschitz continuity of the policies with respect to the state observations and actions by adversarial regularization. The ERNIE framework provides robustness against noisy observations, changing transition dynamics, and malicious actions of agents. However, ERNIE's adversarial regularization may introduce some training instability. To reduce this instability, we reformulate adversarial regularization as a Stackelberg game. We demonstrate the effectiveness of the proposed framework with extensive experiments in traffic light control and particle environments. In addition, we extend ERNIE to mean-field MARL with a formulation based on distributionally robust optimization that outperforms its non-robust counterpart and is of independent interest. Our code is available at https://github.com/abukharin3/ERNIE.
LoSparse: Structured Compression of Large Language Models based on Low-Rank and Sparse Approximation
Jun 26, 2023Transformer models have achieved remarkable results in various natural language tasks, but they are often prohibitively large, requiring massive memories and computational resources. To reduce the size and complexity of these models, we propose LoSparse (Low-Rank and Sparse approximation), a novel model compression technique that approximates a weight matrix by the sum of a low-rank matrix and a sparse matrix. Our method combines the advantages of both low-rank approximations and pruning, while avoiding their limitations. Low-rank approximation compresses the coherent and expressive parts in neurons, while pruning removes the incoherent and non-expressive parts in neurons. Pruning enhances the diversity of low-rank approximations, and low-rank approximation prevents pruning from losing too many expressive neurons. We evaluate our method on natural language understanding, question answering, and natural language generation tasks. We show that it significantly outperforms existing compression methods.