 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Oriented In-Domain Data Augmentation
Jun 24, 2024



Large Language Models (LLMs) have shown superior performance in various applications and fields. To achieve better performance on specialized domains such as law and advertisement, LLMs are often continue pre-trained on in-domain data. However, existing approaches suffer from two major issues. First, in-domain data are scarce compared with general domain-agnostic data. Second, data used for continual pre-training are not task-aware, such that they may not be helpful to downstream applications. We propose TRAIT, a task-oriented in-domain data augmentation framework. Our framework is divided into two parts: in-domain data selection and task-oriented synthetic passage generation. The data selection strategy identifies and selects a large amount of in-domain data from general corpora, and thus significantly enriches domain knowledge in the continual pre-training data. The synthetic passages contain guidance on how to use domain knowledge to answer questions about downstream tasks. By training on such passages, the model aligns with the need of downstream applications. We adapt LLMs to two domains: advertisement and math. On average, TRAIT improves LLM performance by 8% in the advertisement domain and 7.5% in the math domain.
Towards Consistent Natural-Language Explanations via Explanation-Consistency Finetuning
Jan 25, 2024



Large language models (LLMs) often generate convincing, fluent explanations. However, different from humans, they often generate inconsistent explanations on different inputs. For example, an LLM may generate the explanation "all birds can fly" when answering the question "Can sparrows fly?" but meanwhile answer "no" to the related question "Can penguins fly?". Explanations should be consistent across related examples so that they allow a human to simulate the LLM's decision process on multiple examples. We propose explanation-consistency finetuning (EC-finetuning), a method that adapts LLMs to generate more consistent natural-language explanations on related examples. EC-finetuning involves finetuning LLMs on synthetic data that is carefully constructed to contain consistent explanations. Across a variety of question-answering datasets in various domains, EC-finetuning yields a 10.0% relative explanation consistency improvement on four finetuning datasets, and generalizes to seven out-of-distribution datasets not seen during finetuning (+4.5% relative). Code is available at https://github.com/yandachen/explanation-consistency-finetuning .
SMURF-THP: Score Matching-based UnceRtainty quantiFication for Transformer Hawkes Process
Oct 25, 2023
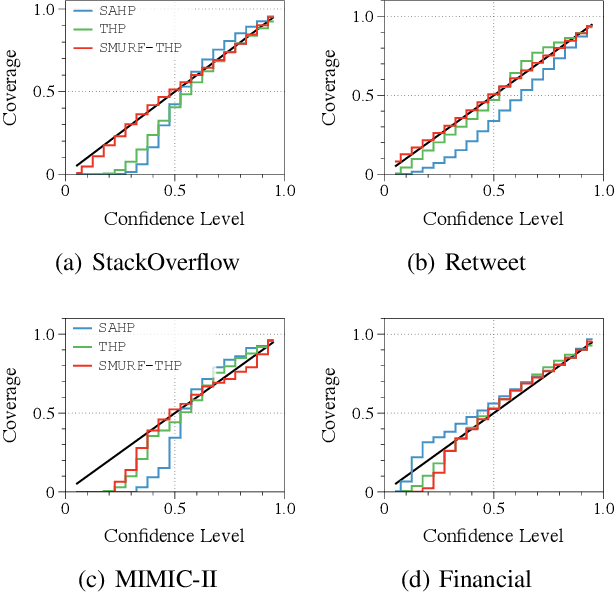
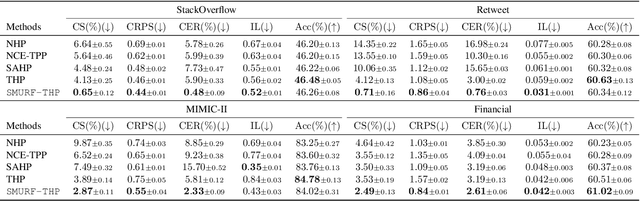
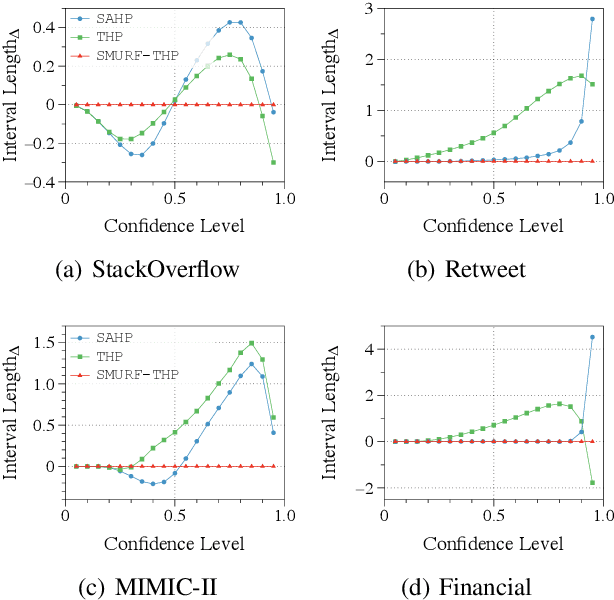
Transformer Hawkes process models have shown to be successful in modeling event sequence data. However, most of the existing training methods rely on maximizing the likelihood of event sequences, which involves calculating some intractable integral. Moreover, the existing methods fail to provide uncertainty quantification for model predictions, e.g., confidence intervals for the predicted event's arrival time. To address these issues, we propose SMURF-THP, a score-based method for learning Transformer Hawkes process and quantifying prediction uncertainty. Specifically, SMURF-THP learns the score function of events' arrival time based on a score-matching objective that avoids the intractable computation. With such a learned score function, we can sample arrival time of events from the predictive distribution. This naturally allows for the quantification of uncertainty by computing confidence intervals over the generated samples. We conduct extensive experiments in both event type prediction and uncertainty quantification of arrival time. In all the experiments, SMURF-THP outperforms existing likelihood-based methods in confidence calibration while exhibiting comparable prediction accuracy.
Evoke: Evoking Critical Thinking Abilities in LLMs via Reviewer-Author Prompt Editing
Oct 20, 2023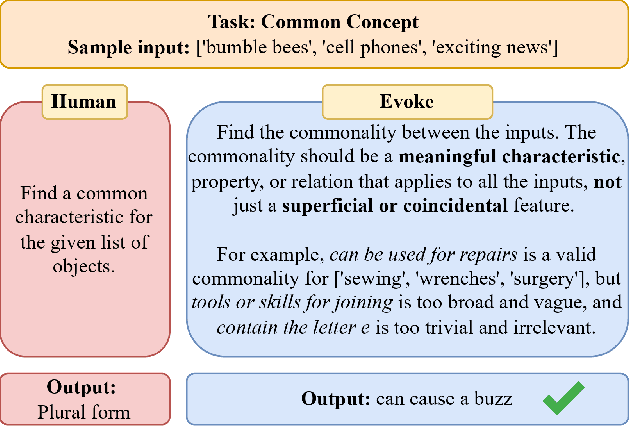
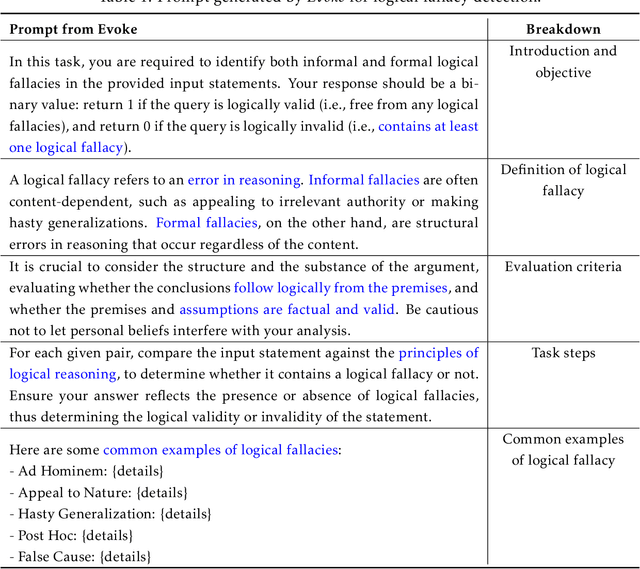
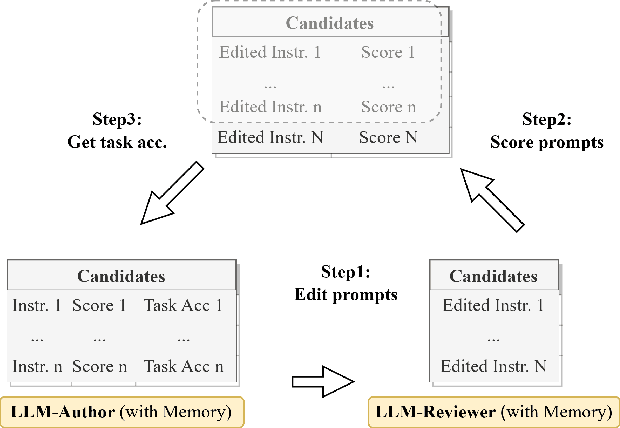
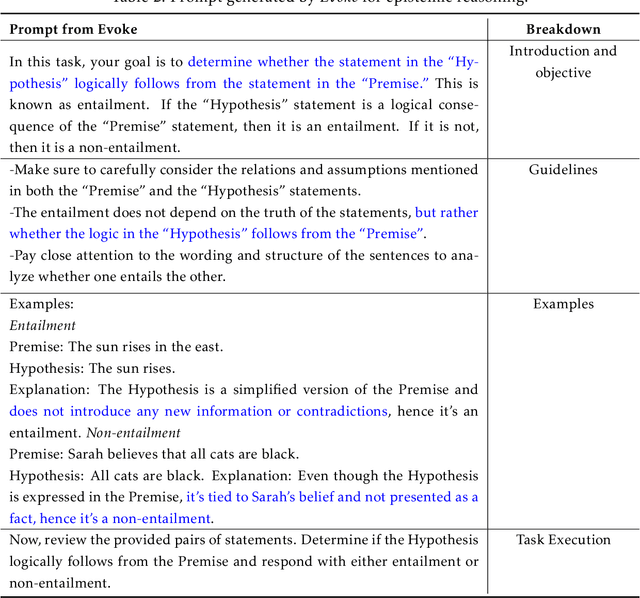
Large language models (LLMs) have made impressive progress in natural language processing. These models rely on proper human instructions (or prompts) to generate suitable responses. However, the potential of LLMs are not fully harnessed by commonly-used prompting methods: many human-in-the-loop algorithms employ ad-hoc procedures for prompt selection; while auto prompt generation approaches are essentially searching all possible prompts randomly and inefficiently. We propose Evoke, an automatic prompt refinement framework. In Evoke, there are two instances of a same LLM: one as a reviewer (LLM-Reviewer), it scores the current prompt; the other as an author (LLM-Author), it edits the prompt by considering the edit history and the reviewer's feedback. Such an author-reviewer feedback loop ensures that the prompt is refined in each iteration. We further aggregate a data selection approach to Evoke, where only the hard samples are exposed to the LLM. The hard samples are more important because the LLM can develop deeper understanding of the tasks out of them, while the model may already know how to solve the easier cases. Experimental results show that Evoke significantly outperforms existing methods. For instance, in the challenging task of logical fallacy detection, Evoke scores above 80, while all other baseline methods struggle to reach 20.
Robust Multi-Agent Reinforcement Learning via Adversarial Regularization: Theoretical Foundation and Stable Algorithms
Oct 16, 2023Multi-Agent Reinforcement Learning (MARL) has shown promising results across several domains. Despite this promise, MARL policies often lack robustness and are therefore sensitive to small changes in their environment. This presents a serious concern for the real world deployment of MARL algorithms, where the testing environment may slightly differ from the training environment. In this work we show that we can gain robustness by controlling a policy's Lipschitz constant, and under mild conditions, establish the existence of a Lipschitz and close-to-optimal policy. Based on these insights, we propose a new robust MARL framework, ERNIE, that promotes the Lipschitz continuity of the policies with respect to the state observations and actions by adversarial regularization. The ERNIE framework provides robustness against noisy observations, changing transition dynamics, and malicious actions of agents. However, ERNIE's adversarial regularization may introduce some training instability. To reduce this instability, we reformulate adversarial regularization as a Stackelberg game. We demonstrate the effectiveness of the proposed framework with extensive experiments in traffic light control and particle environments. In addition, we extend ERNIE to mean-field MARL with a formulation based on distributionally robust optimization that outperforms its non-robust counterpart and is of independent interest. Our code is available at https://github.com/abukharin3/ERNIE.
DeepTagger: Knowledge Enhanced Named Entity Recognition for Web-Based Ads Queries
Jun 30, 2023

Named entity recognition (NER) is a crucial task for online advertisement. State-of-the-art solutions leverage pre-trained language models for this task. However, three major challenges remain unresolved: web queries differ from natural language, on which pre-trained models are trained; web queries are short and lack contextual information; and labeled data for NER is scarce. We propose DeepTagger, a knowledge-enhanced NER model for web-based ads queries. The proposed knowledge enhancement framework leverages both model-free and model-based approaches. For model-free enhancement, we collect unlabeled web queries to augment domain knowledge; and we collect web search results to enrich the information of ads queries. We further leverage effective prompting methods to automatically generate labels using large language models such as ChatGPT. Additionally, we adopt a model-based knowledge enhancement method based on adversarial data augmentation. We employ a three-stage training framework to train DeepTagger models. Empirical results in various NER tasks demonstrate the effectiveness of the proposed framework.
Machine Learning Force Fields with Data Cost Aware Training
Jun 05, 2023



Machine learning force fields (MLFF) have been proposed to accelerate molecular dynamics (MD) simulation, which finds widespread applications in chemistry and biomedical research. Even for the most data-efficient MLFFs, reaching chemical accuracy can require hundreds of frames of force and energy labels generated by expensive quantum mechanical algorithms, which may scale as $O(n^3)$ to $O(n^7)$, with $n$ proportional to the number of basis functions. To address this issue, we propose a multi-stage computational framework -- ASTEROID, which lowers the data cost of MLFFs by leveraging a combination of cheap inaccurate data and expensive accurate data. The motivation behind ASTEROID is that inaccurate data, though incurring large bias, can help capture the sophisticated structures of the underlying force field. Therefore, we first train a MLFF model on a large amount of inaccurate training data, employing a bias-aware loss function to prevent the model from overfitting tahe potential bias of this data. We then fine-tune the obtained model using a small amount of accurate training data, which preserves the knowledge learned from the inaccurate training data while significantly improving the model's accuracy. Moreover, we propose a variant of ASTEROID based on score matching for the setting where the inaccurate training data are unlabeled. Extensive experiments on MD datasets and downstream tasks validate the efficacy of ASTEROID. Our code and data are available at https://github.com/abukharin3/asteroid.
Efficient Long Sequence Modeling via State Space Augmented Transformer
Dec 15, 2022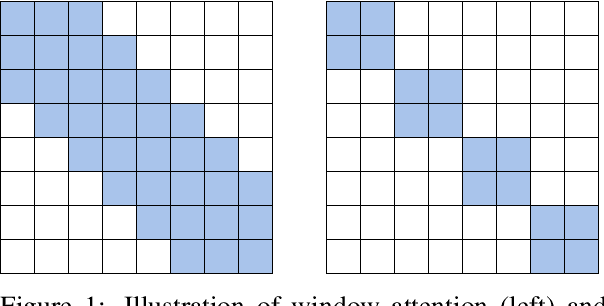
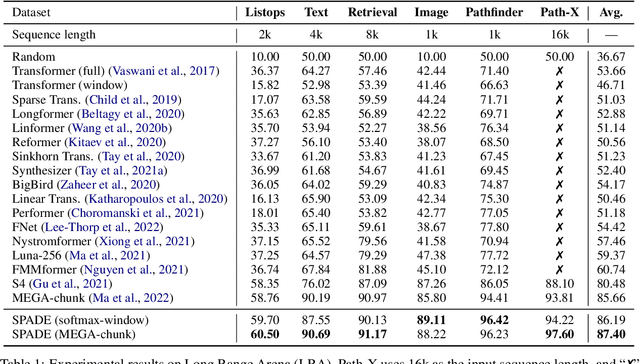
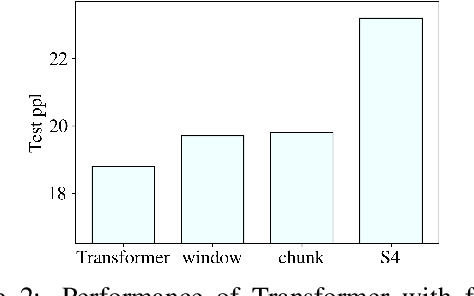
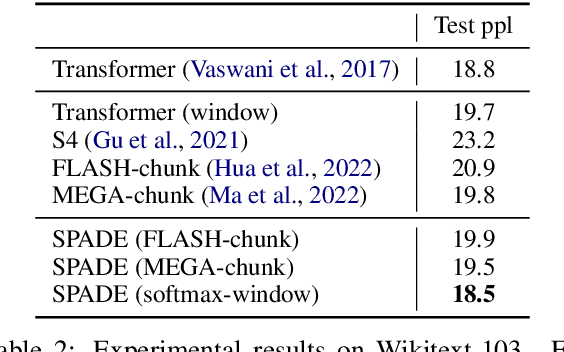
Transformer models have achieved superior performance in various natural language processing tasks. However, the quadratic computational cost of the attention mechanism limits its practicality for long sequences. There are existing attention variants that improve the computational efficiency, but they have limited ability to effectively compute global information. In parallel to Transformer models, state space models (SSMs) are tailored for long sequences, but they are not flexible enough to capture complicated local information. We propose SPADE, short for $\underline{\textbf{S}}$tate s$\underline{\textbf{P}}$ace $\underline{\textbf{A}}$ugmente$\underline{\textbf{D}}$ Transform$\underline{\textbf{E}}$r. Specifically, we augment a SSM into the bottom layer of SPADE, and we employ efficient local attention methods for the other layers. The SSM augments global information, which complements the lack of long-range dependency issue in local attention methods. Experimental results on the Long Range Arena benchmark and language modeling tasks demonstrate the effectiveness of the proposed method. To further demonstrate the scalability of SPADE, we pre-train large encoder-decoder models and present fine-tuning results on natural language understanding and natural language generation tasks.
Less is More: Task-aware Layer-wise Distillation for Language Model Compression
Oct 05, 2022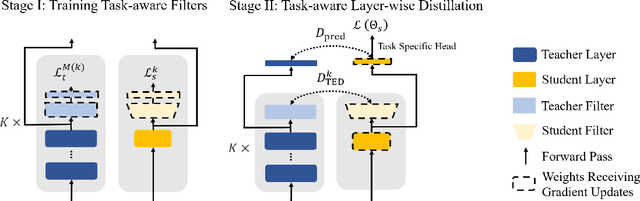
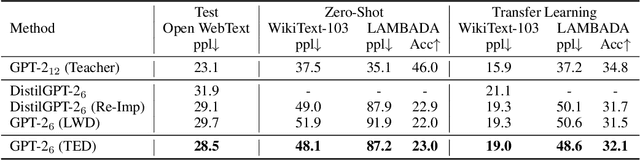
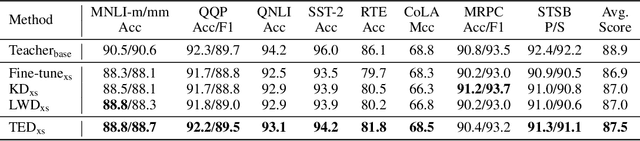
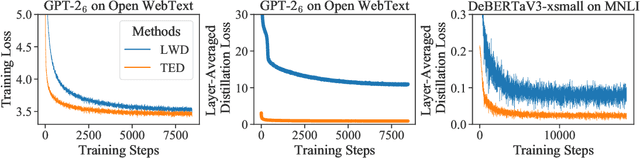
Layer-wise distillation is a powerful tool to compress large models (i.e. teacher models) into small ones (i.e., student models). The student distills knowledge from the teacher by mimicking the hidden representations of the teacher at every intermediate layer. However, layer-wise distillation is difficult. Since the student has a smaller model capacity than the teacher, it is often under-fitted. Furthermore, the hidden representations of the teacher contain redundant information that the student does not necessarily need for the target task's learning. To address these challenges, we propose a novel Task-aware layEr-wise Distillation (TED). TED designs task-aware filters to align the hidden representations of the student and the teacher at each layer. The filters select the knowledge that is useful for the target task from the hidden representations. As such, TED reduces the knowledge gap between the two models and helps the student to fit better on the target task. We evaluate TED in two scenarios: continual pre-training and fine-tuning. TED demonstrates significant and consistent improvements over existing distillation methods in both scenarios.
Context-Aware Query Rewriting for Improving Users' Search Experience on E-commerce Websites
Sep 24, 2022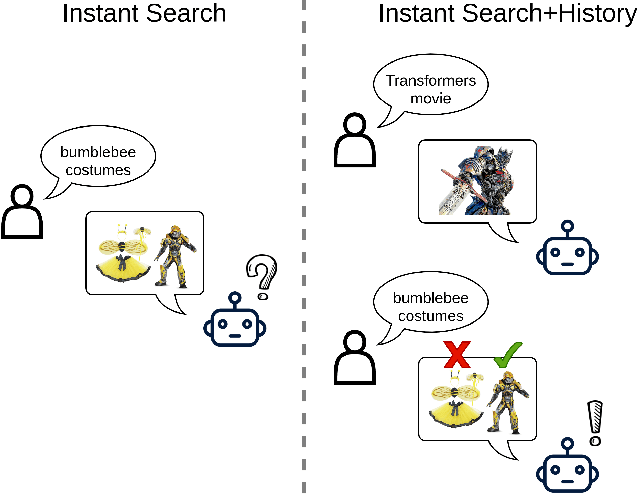
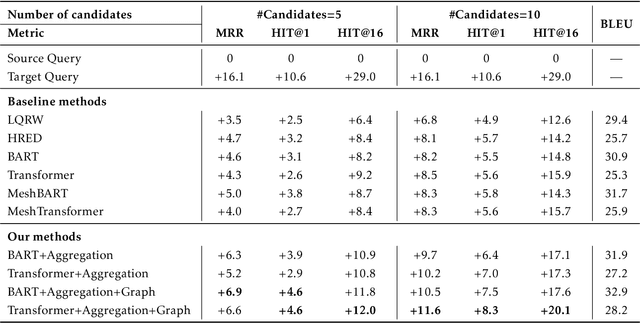
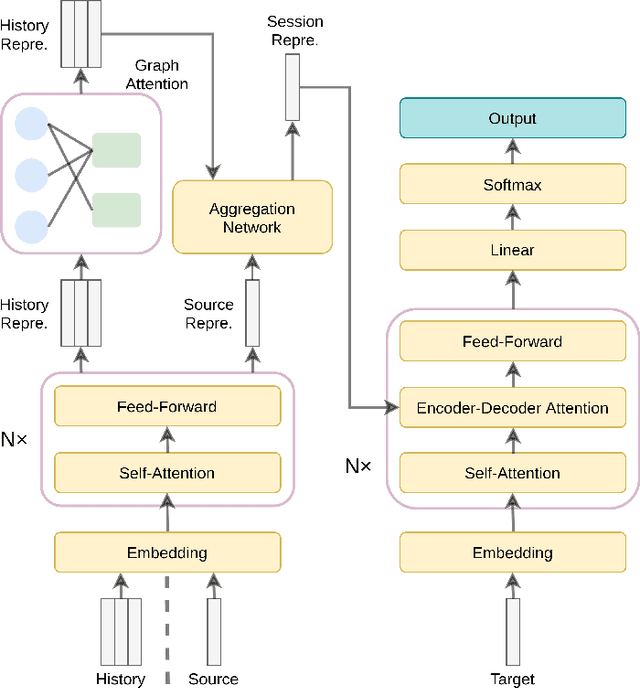
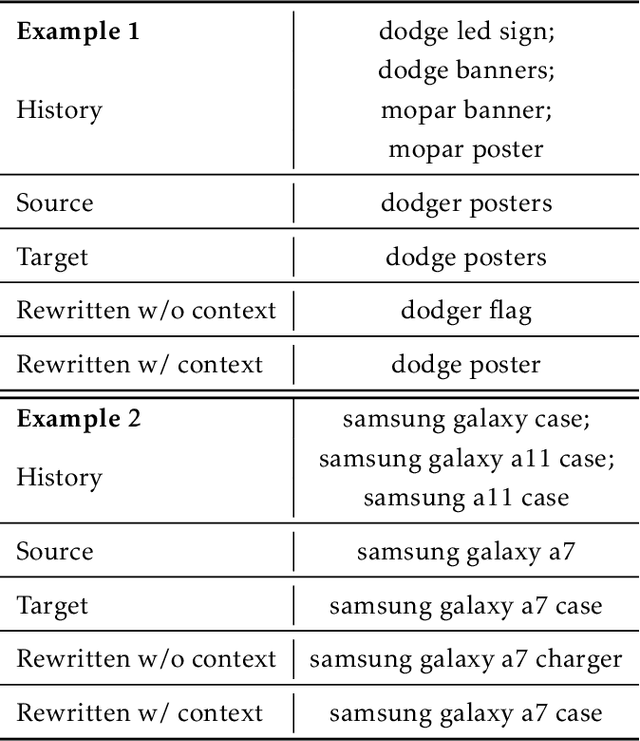
E-commerce queries are often short and ambiguous. Consequently, query understanding often uses query rewriting to disambiguate user-input queries. While using e-commerce search tools, users tend to enter multiple searches, which we call context, before purchasing. These history searches contain contextual insights about users' true shopping intents. Therefore, modeling such contextual information is critical to a better query rewriting model. However, existing query rewriting models ignore users' history behaviors and consider only the instant search query, which is often a short string offering limited information about the true shopping intent. We propose an end-to-end context-aware query rewriting model to bridge this gap, which takes the search context into account. Specifically, our model builds a session graph using the history search queries and their contained words. We then employ a graph attention mechanism that models cross-query relations and computes contextual information of the session. The model subsequently calculates session representations by combining the contextual information with the instant search query using an aggregation network. The session representations are then decoded to generate rewritten queries. Empirically, we demonstrate the superiority of our method to state-of-the-art approaches under various metrics. On in-house data from an online shopping platform, by introducing contextual information, our model achieves 11.6% improvement under the MRR (Mean Reciprocal Rank) metric and 20.1% improvement under the HIT@16 metric (a hit rate metric), in comparison with the best baseline method (Transformer-based model).