 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Long Sequence Modeling via State Space Augmented Transformer
Dec 15, 2022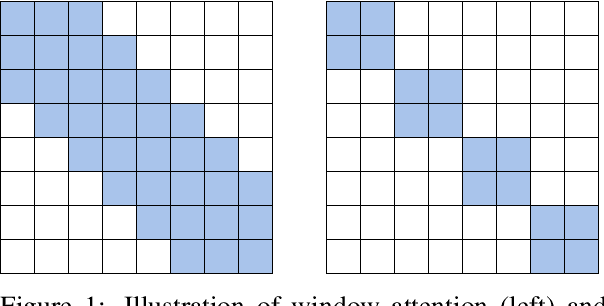
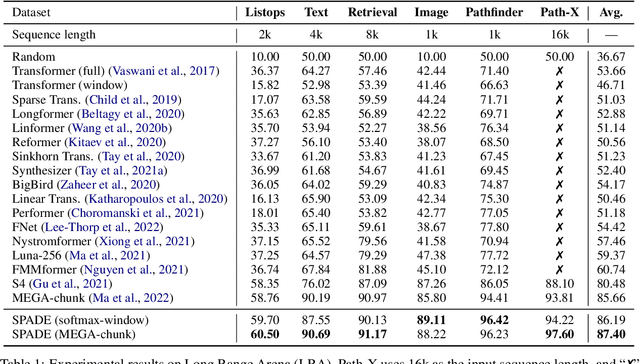
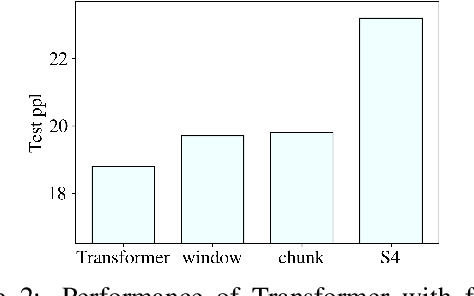
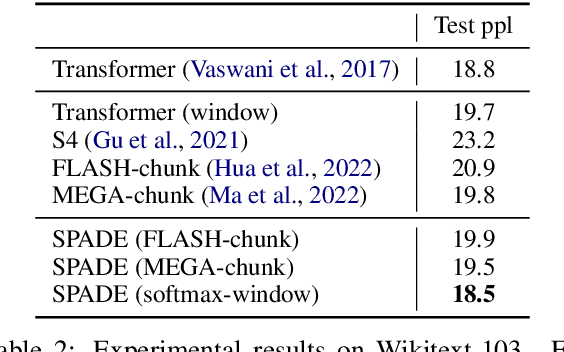
Transformer models have achieved superior performance in various natural language processing tasks. However, the quadratic computational cost of the attention mechanism limits its practicality for long sequences. There are existing attention variants that improve the computational efficiency, but they have limited ability to effectively compute global information. In parallel to Transformer models, state space models (SSMs) are tailored for long sequences, but they are not flexible enough to capture complicated local information. We propose SPADE, short for $\underline{\textbf{S}}$tate s$\underline{\textbf{P}}$ace $\underline{\textbf{A}}$ugmente$\underline{\textbf{D}}$ Transform$\underline{\textbf{E}}$r. Specifically, we augment a SSM into the bottom layer of SPADE, and we employ efficient local attention methods for the other layers. The SSM augments global information, which complements the lack of long-range dependency issue in local attention methods. Experimental results on the Long Range Arena benchmark and language modeling tasks demonstrate the effectiveness of the proposed method. To further demonstrate the scalability of SPADE, we pre-train large encoder-decoder models and present fine-tuning results on natural language understanding and natural language generation tasks.
Representation Learning for Clustering via Building Consensus
May 04, 2021
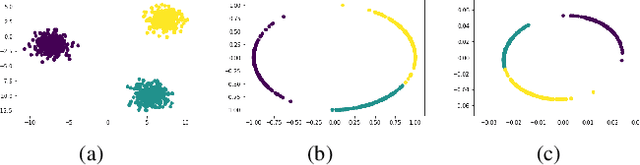
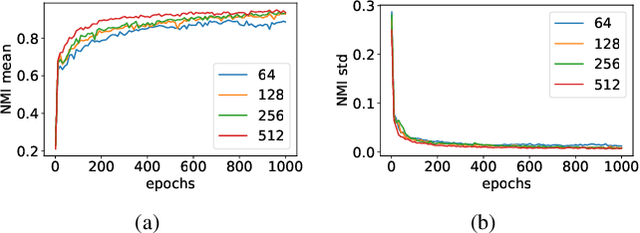

In this paper, we focus on deep clustering and unsupervised representation learning for images. Recent advances in deep clustering and unsupervised representation learning are based on the idea that different views of an input image (generated through data augmentation techniques) must be closer in the representation space (exemplar consistency), and/or similar images have a similar cluster assignment (population consistency). We define an additional notion of consistency, consensus consistency, which ensures that representations are learnt to induce similar partitions for variations in the representation space, different clustering algorithms or different initializations of a clustering algorithm. We define a clustering loss by performing variations in the representation space and seamlessly integrate all three consistencies (consensus, exemplar and population) into an end-to-end learning framework. The proposed algorithm, Consensus Clustering using Unsupervised Representation Learning (ConCURL) improves the clustering performance over state-of-the art methods on four out of five image datasets. Further, we extend the evaluation procedure for clustering to reflect the challenges in real world clustering tasks, such as clustering performance in the case of distribution shift. We also perform a detailed ablation study for a deeper understanding of the algorithm.
Consensus Clustering with Unsupervised Representation Learning
Oct 03, 2020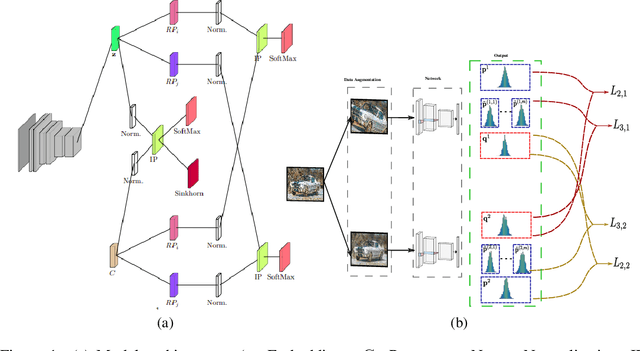


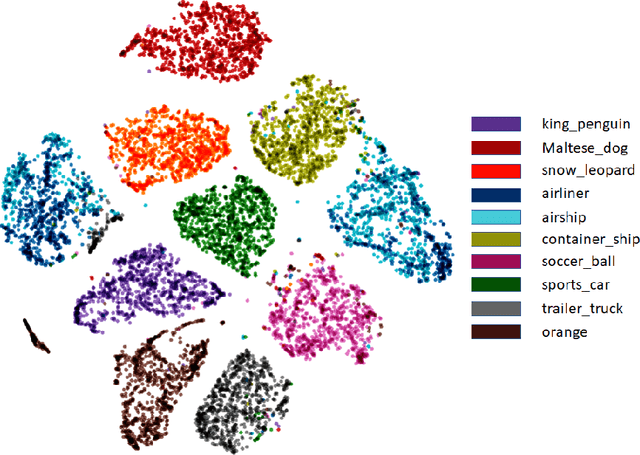
Recent advances in deep clustering and unsupervised representation learning are based on the idea that different views of an input image (generated through data augmentation techniques) must either be closer in the representation space, or have a similar cluster assignment. In this work, we leverage this idea together with ensemble learning to perform clustering and representation learning. Ensemble learning is widely used in the supervised learning setting but has not yet been practical in deep clustering. Previous works on ensemble learning for clustering neither work on the feature space nor learn features. We propose a novel ensemble learning algorithm dubbed Consensus Clustering with Unsupervised Representation Learning (ConCURL) which learns representations by creating a consensus on multiple clustering outputs. Specifically, we generate a cluster ensemble using random transformations on the embedding space, and define a consensus loss function that measures the disagreement among the constituents of the ensemble. Thus, diverse ensembles minimize this loss function in a synergistic way, which leads to better representations that work with all cluster ensemble constituents. Our proposed method ConCURL is easy to implement and integrate into any representation learning or deep clustering block. ConCURL outperforms all state of the art methods on various computer vision datasets. Specifically, we beat the closest state of the art method by 5.9 percent on the ImageNet-10 dataset, and by 18 percent on the ImageNet-Dogs dataset in terms of clustering accuracy. We further shed some light on the under-studied overfitting issue in clustering and show that our method does not overfit as much as existing methods, and thereby generalizes better for new data samples.
Self-Supervised Contextual Bandits in Computer Vision
Mar 18, 2020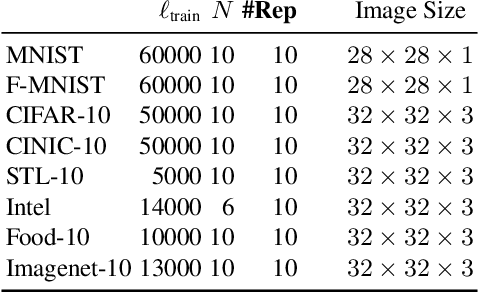
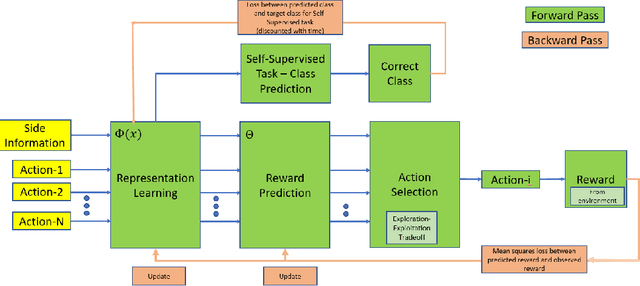
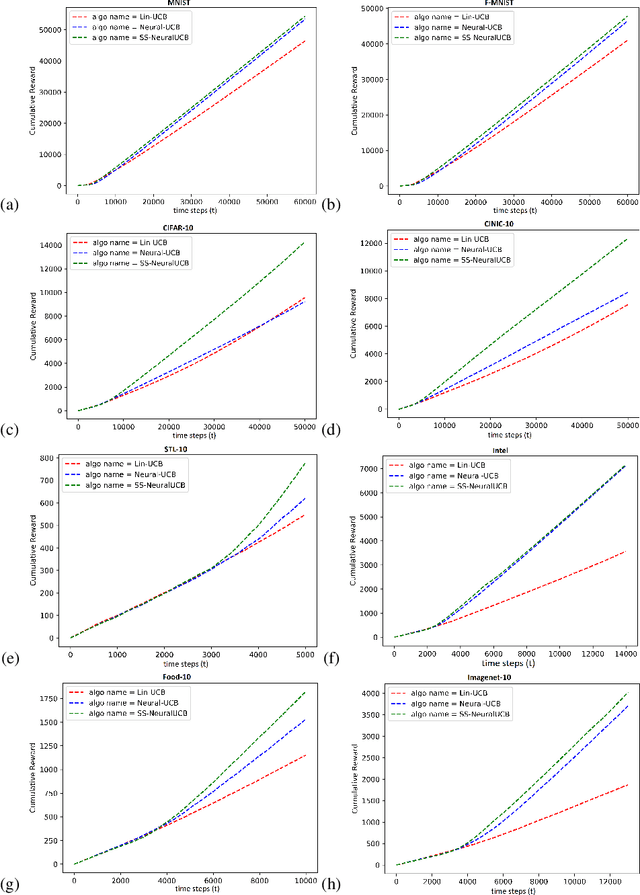
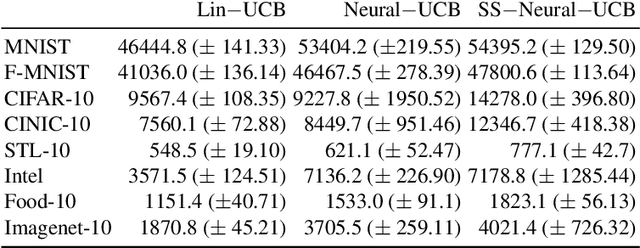
Contextual bandits are a common problem faced by machine learning practitioners in domains as diverse as hypothesis testing to product recommendations. There have been a lot of approaches in exploiting rich data representations for contextual bandit problems with varying degree of success. Self-supervised learning is a promising approach to find rich data representations without explicit labels. In a typical self-supervised learning scheme, the primary task is defined by the problem objective (e.g. clustering, classification, embedding generation etc.) and the secondary task is defined by the self-supervision objective (e.g. rotation prediction, words in neighborhood, colorization, etc.). In the usual self-supervision, we learn implicit labels from the training data for a secondary task. However, in the contextual bandit setting, we don't have the advantage of getting implicit labels due to lack of data in the initial phase of learning. We provide a novel approach to tackle this issue by combining a contextual bandit objective with a self supervision objective. By augmenting contextual bandit learning with self-supervision we get a better cumulative reward. Our results on eight popular computer vision datasets show substantial gains in cumulative reward. We provide cases where the proposed scheme doesn't perform optimally and give alternative methods for better learning in these cases.
Data Transformation Insights in Self-supervision with Clustering Tasks
Feb 18, 2020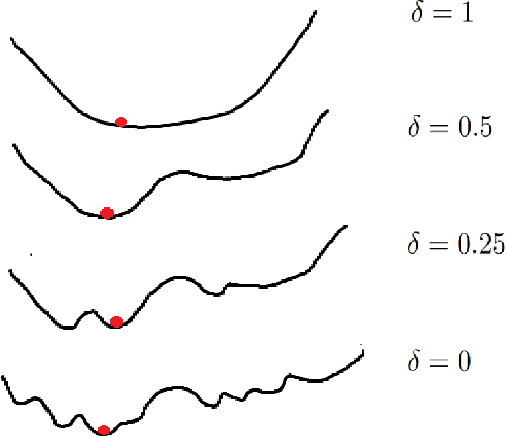

Self-supervision is key to extending use of deep learning for label scarce domains. For most of self-supervised approaches data transformations play an important role. However, up until now the impact of transformations have not been studied. Furthermore, different transformations may have different impact on the system. We provide novel insights into the use of data transformation in self-supervised tasks, specially pertaining to clustering. We show theoretically and empirically that certain set of transformations are helpful in convergence of self-supervised clustering. We also show the cases when the transformations are not helpful or in some cases even harmful. We show faster convergence rate with valid transformations for convex as well as certain family of non-convex objectives along with the proof of convergence to the original set of optima. We have synthetic as well as real world data experiments. Empirically our results conform with the theoretical insights provided.
A Unified Batch Online Learning Framework for Click Prediction
Sep 12, 2018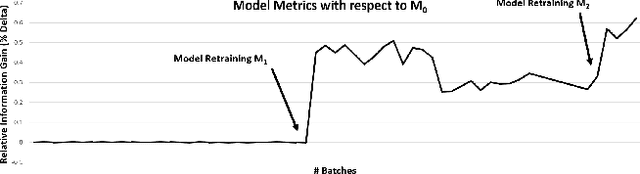
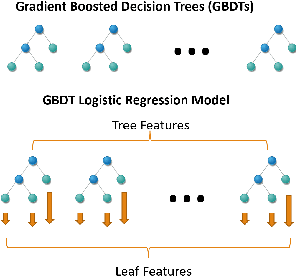
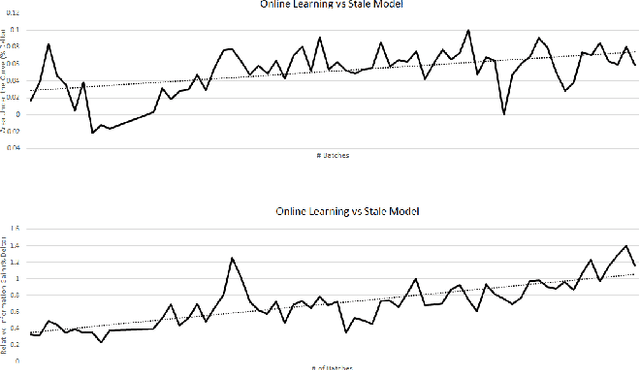
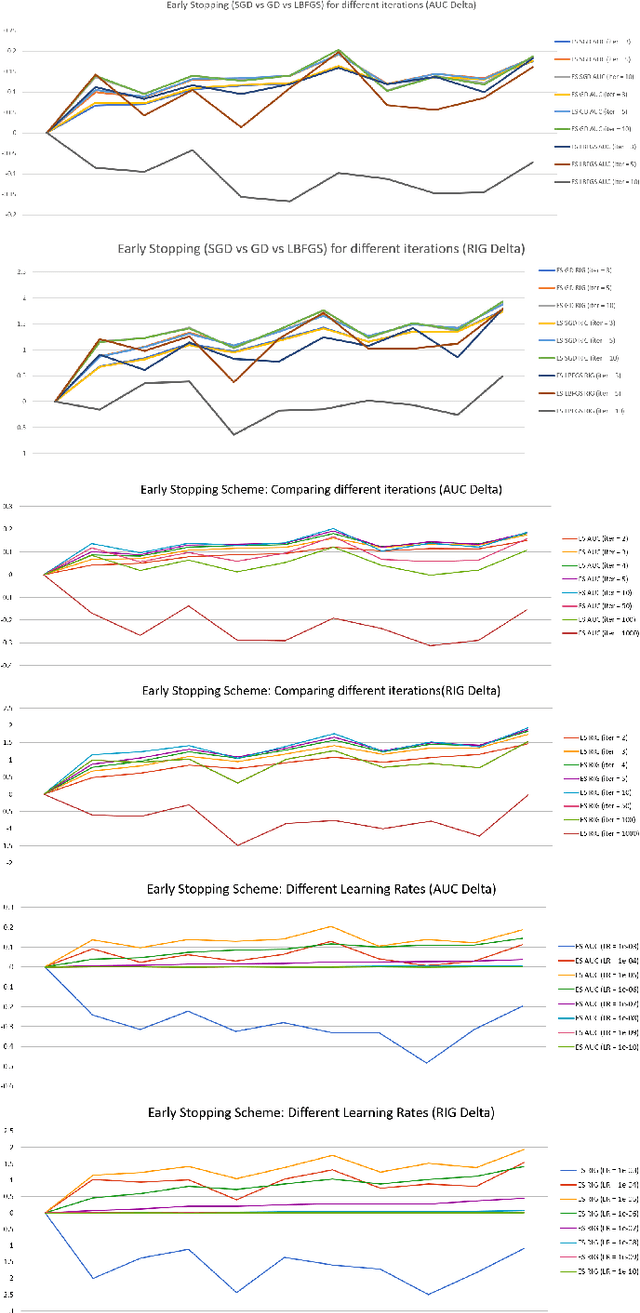
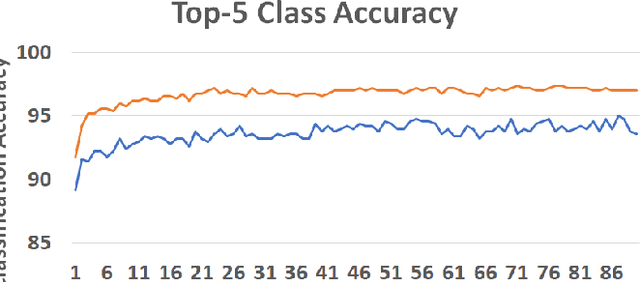
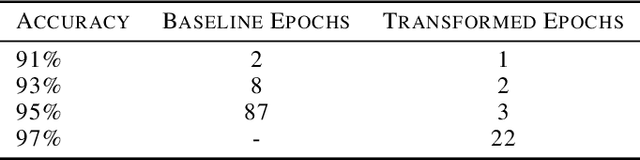
We present a unified framework for Batch Online Learning (OL) for Click Prediction in Search Advertisement. Machine Learning models once deployed, show non-trivial accuracy and calibration degradation over time due to model staleness. It is therefore necessary to regularly update models, and do so automatically. This paper presents two paradigms of Batch Online Learning, one which incrementally updates the model parameters via an early stopping mechanism, and another which does so through a proximal regularization. We argue how both these schemes naturally trade-off between old and new data. We then theoretically and empirically show that these two seemingly different schemes are closely related. Through extensive experiments, we demonstrate the utility of of our OL framework; how the two OL schemes relate to each other and how they trade-off between the new and historical data. We then compare batch OL to full model retrains, and show how online learning is more robust to data issues. We also demonstrate the long term impact of Online Learning, the role of the initial Models in OL, the impact of delays in the update, and finally conclude with some implementation details and challenges in deploying a real world online learning system in production. While this paper mostly focuses on application of click prediction for search advertisement, we hope that the lessons learned here can be carried over to other problem domains.
Modeling and Simultaneously Removing Bias via Adversarial Neural Networks
Apr 18, 2018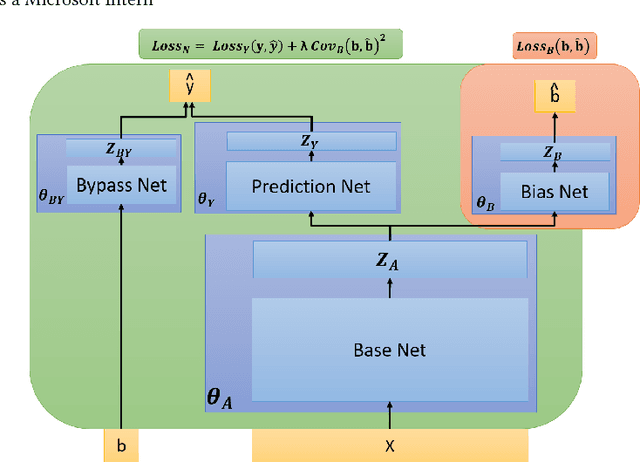
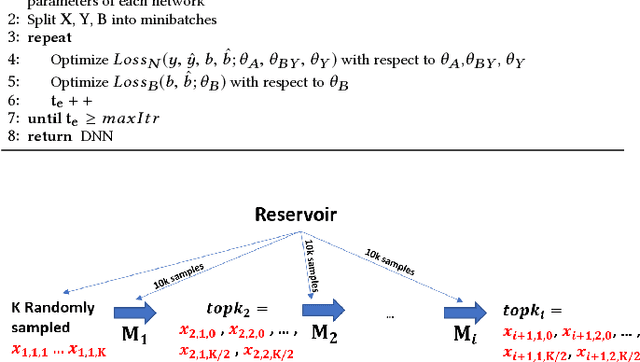
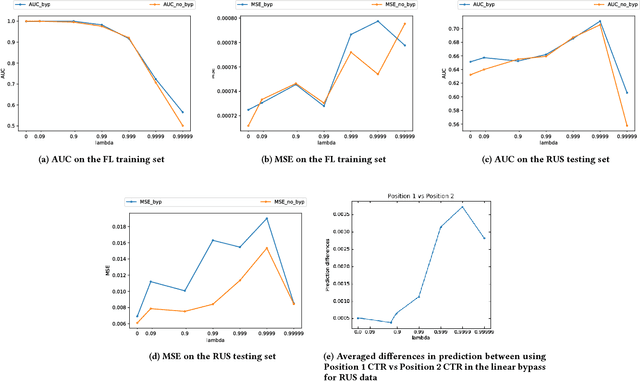
In real world systems, the predictions of deployed Machine Learned models affect the training data available to build subsequent models. This introduces a bias in the training data that needs to be addressed. Existing solutions to this problem attempt to resolve the problem by either casting this in the reinforcement learning framework or by quantifying the bias and re-weighting the loss functions. In this work, we develop a novel Adversarial Neural Network (ANN) model, an alternative approach which creates a representation of the data that is invariant to the bias. We take the Paid Search auction as our working example and ad display position features as the confounding features for this setting. We show the success of this approach empirically on both synthetic data as well as real world paid search auction data from a major search engine.