 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Contextual Bandits in Computer Vision
Mar 18, 2020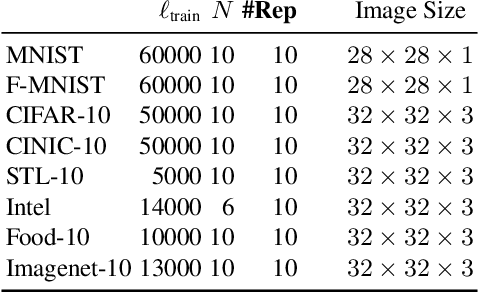
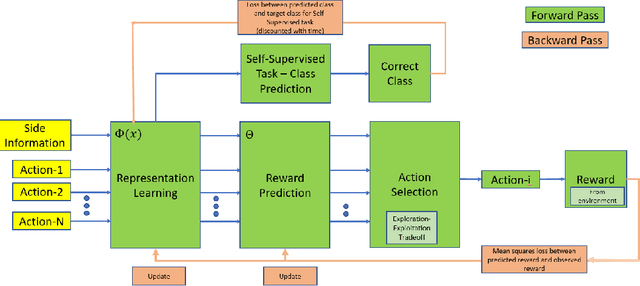
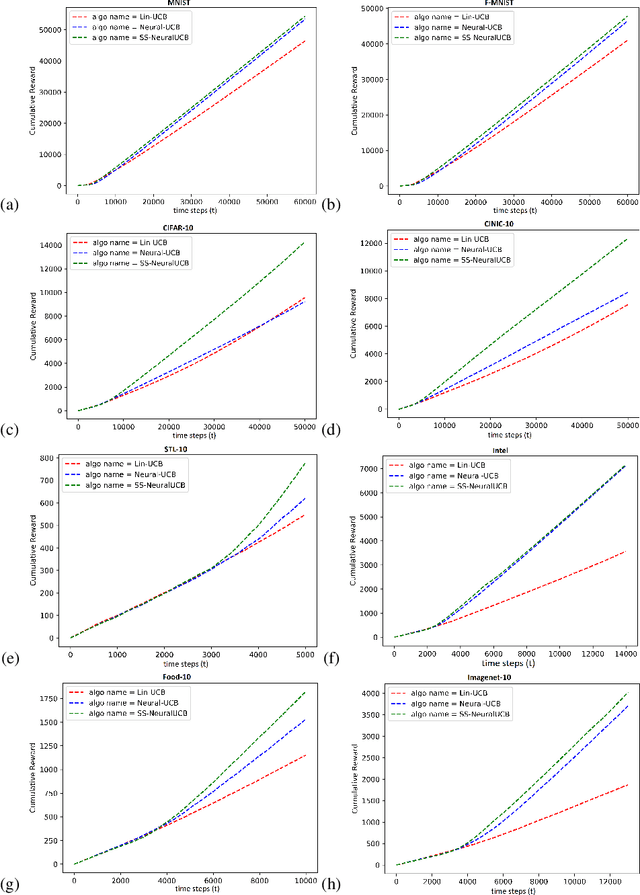
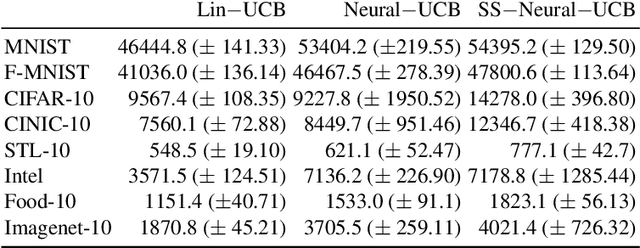
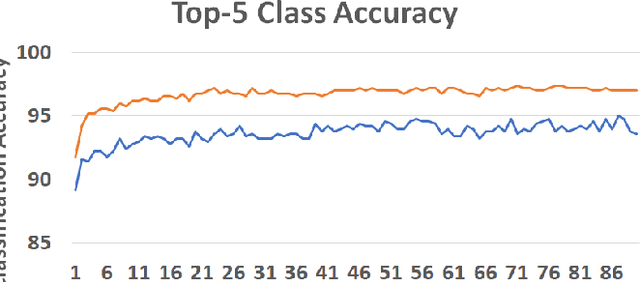
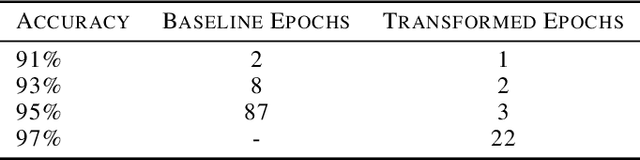
Contextual bandits are a common problem faced by machine learning practitioners in domains as diverse as hypothesis testing to product recommendations. There have been a lot of approaches in exploiting rich data representations for contextual bandit problems with varying degree of success. Self-supervised learning is a promising approach to find rich data representations without explicit labels. In a typical self-supervised learning scheme, the primary task is defined by the problem objective (e.g. clustering, classification, embedding generation etc.) and the secondary task is defined by the self-supervision objective (e.g. rotation prediction, words in neighborhood, colorization, etc.). In the usual self-supervision, we learn implicit labels from the training data for a secondary task. However, in the contextual bandit setting, we don't have the advantage of getting implicit labels due to lack of data in the initial phase of learning. We provide a novel approach to tackle this issue by combining a contextual bandit objective with a self supervision objective. By augmenting contextual bandit learning with self-supervision we get a better cumulative reward. Our results on eight popular computer vision datasets show substantial gains in cumulative reward. We provide cases where the proposed scheme doesn't perform optimally and give alternative methods for better learning in these cases.
Data Transformation Insights in Self-supervision with Clustering Tasks
Feb 18, 2020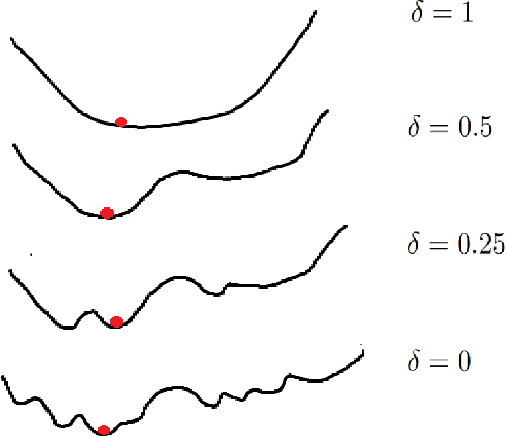

Self-supervision is key to extending use of deep learning for label scarce domains. For most of self-supervised approaches data transformations play an important role. However, up until now the impact of transformations have not been studied. Furthermore, different transformations may have different impact on the system. We provide novel insights into the use of data transformation in self-supervised tasks, specially pertaining to clustering. We show theoretically and empirically that certain set of transformations are helpful in convergence of self-supervised clustering. We also show the cases when the transformations are not helpful or in some cases even harmful. We show faster convergence rate with valid transformations for convex as well as certain family of non-convex objectives along with the proof of convergence to the original set of optima. We have synthetic as well as real world data experiments. Empirically our results conform with the theoretical insights provided.
Distributed Training of Deep Neural Networks with Theoretical Analysis: Under SSP Setting
Dec 11, 2015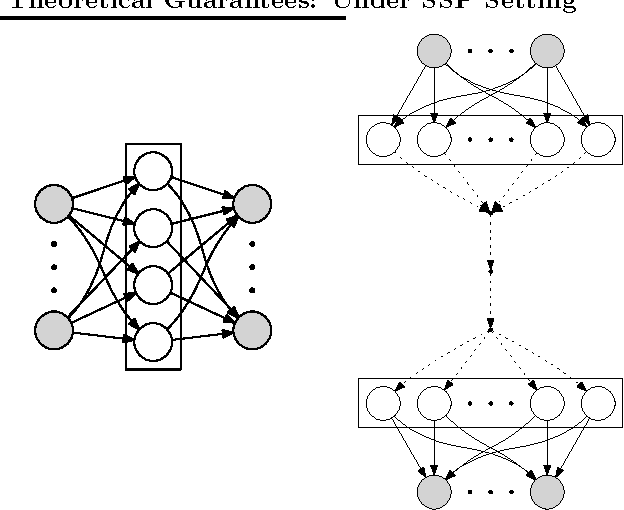

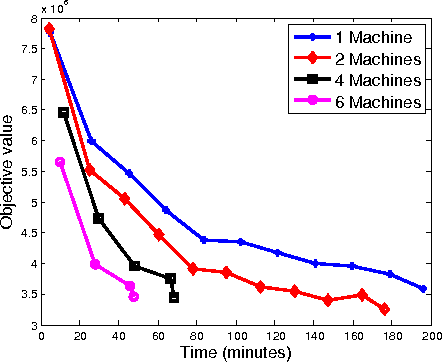
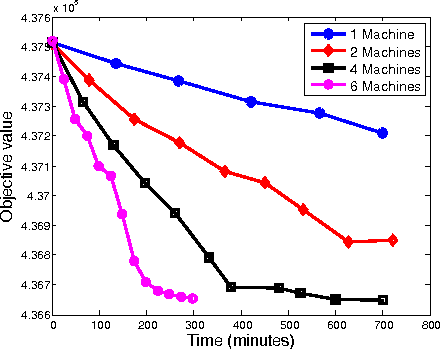
We propose a distributed approach to train deep neural networks (DNNs), which has guaranteed convergence theoretically and great scalability empirically: close to 6 times faster on instance of ImageNet data set when run with 6 machines. The proposed scheme is close to optimally scalable in terms of number of machines, and guaranteed to converge to the same optima as the undistributed setting. The convergence and scalability of the distributed setting is shown empirically across different datasets (TIMIT and ImageNet) and machine learning tasks (image classification and phoneme extraction). The convergence analysis provides novel insights into this complex learning scheme, including: 1) layerwise convergence, and 2) convergence of the weights in probability.
Scalable Modeling of Conversational-role based Self-presentation Characteristics in Large Online Forums
Dec 10, 2015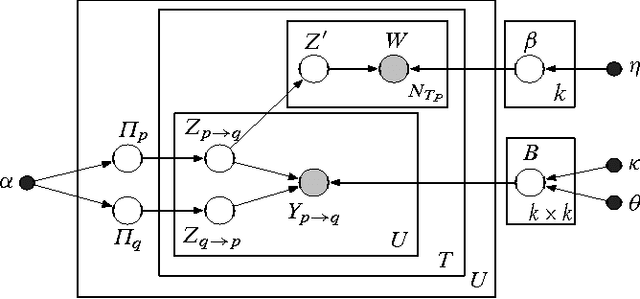
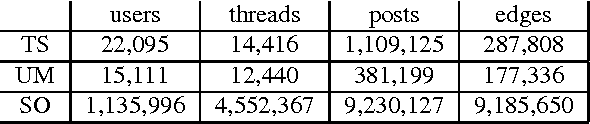
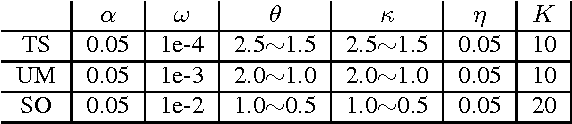
Online discussion forums are complex webs of overlapping subcommunities (macrolevel structure, across threads) in which users enact different roles depending on which subcommunity they are participating in within a particular time point (microlevel structure, within threads). This sub-network structure is implicit in massive collections of threads. To uncover this structure, we develop a scalable algorithm based on stochastic variational inference and leverage topic models (LDA) along with mixed membership stochastic block (MMSB) models. We evaluate our model on three large-scale datasets, Cancer-ThreadStarter (22K users and 14.4K threads), Cancer-NameMention(15.1K users and 12.4K threads) and StackOverFlow (1.19 million users and 4.55 million threads). Qualitatively, we demonstrate that our model can provide useful explanations of microlevel and macrolevel user presentation characteristics in different communities using the topics discovered from posts. Quantitatively, we show that our model does better than MMSB and LDA in predicting user reply structure within threads. In addition, we demonstrate via synthetic data experiments that the proposed active sub-network discovery model is stable and recovers the original parameters of the experimental setup with high probability.
Distributed Machine Learning via Sufficient Factor Broadcasting
Nov 26, 2015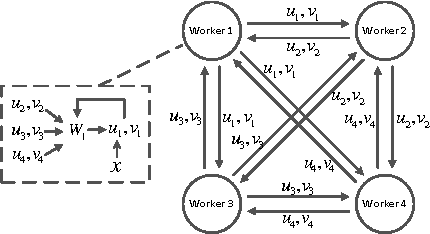
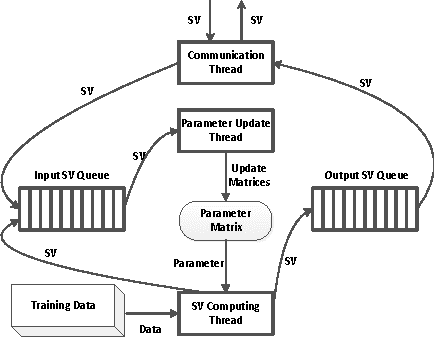


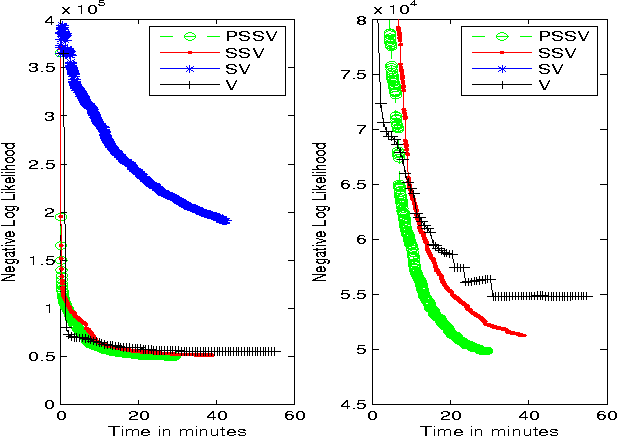
Matrix-parametrized models, including multiclass logistic regression and sparse coding, are used in machine learning (ML) applications ranging from computer vision to computational biology. When these models are applied to large-scale ML problems starting at millions of samples and tens of thousands of classes, their parameter matrix can grow at an unexpected rate, resulting in high parameter synchronization costs that greatly slow down distributed learning. To address this issue, we propose a Sufficient Factor Broadcasting (SFB) computation model for efficient distributed learning of a large family of matrix-parameterized models, which share the following property: the parameter update computed on each data sample is a rank-1 matrix, i.e., the outer product of two "sufficient factors" (SFs). By broadcasting the SFs among worker machines and reconstructing the update matrices locally at each worker, SFB improves communication efficiency --- communication costs are linear in the parameter matrix's dimensions, rather than quadratic --- without affecting computational correctness. We present a theoretical convergence analysis of SFB, and empirically corroborate its efficiency on four different matrix-parametrized ML models.
Petuum: A New Platform for Distributed Machine Learning on Big Data
May 14, 2015
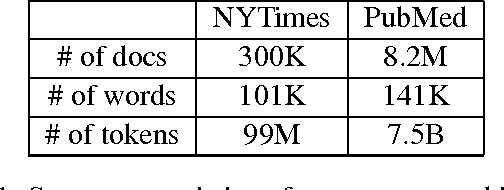

What is a systematic way to efficiently apply a wide spectrum of advanced ML programs to industrial scale problems, using Big Models (up to 100s of billions of parameters) on Big Data (up to terabytes or petabytes)? Modern parallelization strategies employ fine-grained operations and scheduling beyond the classic bulk-synchronous processing paradigm popularized by MapReduce, or even specialized graph-based execution that relies on graph representations of ML programs. The variety of approaches tends to pull systems and algorithms design in different directions, and it remains difficult to find a universal platform applicable to a wide range of ML programs at scale. We propose a general-purpose framework that systematically addresses data- and model-parallel challenges in large-scale ML, by observing that many ML programs are fundamentally optimization-centric and admit error-tolerant, iterative-convergent algorithmic solutions. This presents unique opportunities for an integrative system design, such as bounded-error network synchronization and dynamic scheduling based on ML program structure. We demonstrate the efficacy of these system designs versus well-known implementations of modern ML algorithms, allowing ML programs to run in much less time and at considerably larger model sizes, even on modestly-sized compute clusters.
High-Performance Distributed ML at Scale through Parameter Server Consistency Models
Oct 29, 2014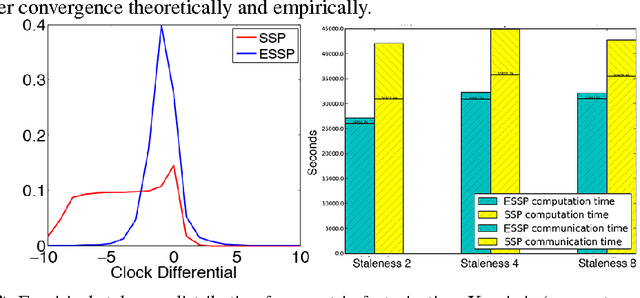
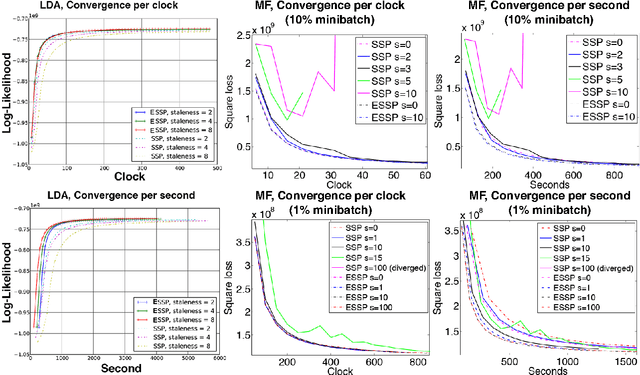
As Machine Learning (ML) applications increase in data size and model complexity, practitioners turn to distributed clusters to satisfy the increased computational and memory demands. Unfortunately, effective use of clusters for ML requires considerable expertise in writing distributed code, while highly-abstracted frameworks like Hadoop have not, in practice, approached the performance seen in specialized ML implementations. The recent Parameter Server (PS) paradigm is a middle ground between these extremes, allowing easy conversion of single-machine parallel ML applications into distributed ones, while maintaining high throughput through relaxed "consistency models" that allow inconsistent parameter reads. However, due to insufficient theoretical study, it is not clear which of these consistency models can really ensure correct ML algorithm output; at the same time, there remain many theoretically-motivated but undiscovered opportunities to maximize computational throughput. Motivated by this challenge, we study both the theoretical guarantees and empirical behavior of iterative-convergent ML algorithms in existing PS consistency models. We then use the gleaned insights to improve a consistency model using an "eager" PS communication mechanism, and implement it as a new PS system that enables ML algorithms to reach their solution more quickly.
Consistent Bounded-Asynchronous Parameter Servers for Distributed ML
Dec 31, 2013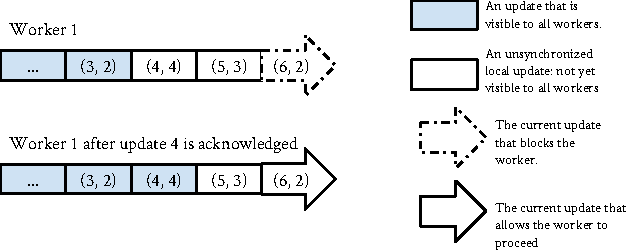

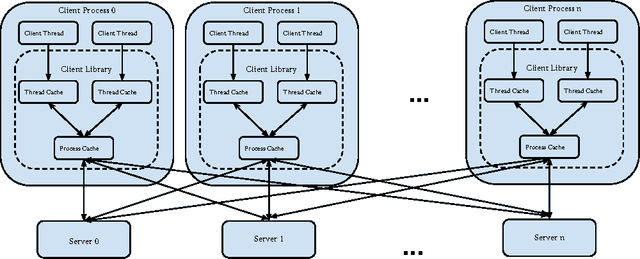
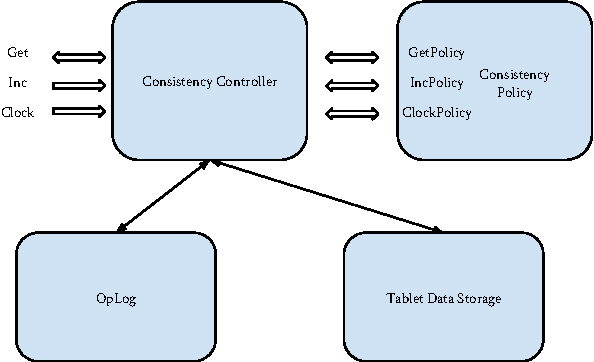
In distributed ML applications, shared parameters are usually replicated among computing nodes to minimize network overhead. Therefore, proper consistency model must be carefully chosen to ensure algorithm's correctness and provide high throughput. Existing consistency models used in general-purpose databases and modern distributed ML systems are either too loose to guarantee correctness of the ML algorithms or too strict and thus fail to fully exploit the computing power of the underlying distributed system. Many ML algorithms fall into the category of \emph{iterative convergent algorithms} which start from a randomly chosen initial point and converge to optima by repeating iteratively a set of procedures. We've found that many such algorithms are to a bounded amount of inconsistency and still converge correctly. This property allows distributed ML to relax strict consistency models to improve system performance while theoretically guarantees algorithmic correctness. In this paper, we present several relaxed consistency models for asynchronous parallel computation and theoretically prove their algorithmic correctness. The proposed consistency models are implemented in a distributed parameter server and evaluated in the context of a popular ML application: topic modeling.
Dating Texts without Explicit Temporal Cues
Nov 10, 2012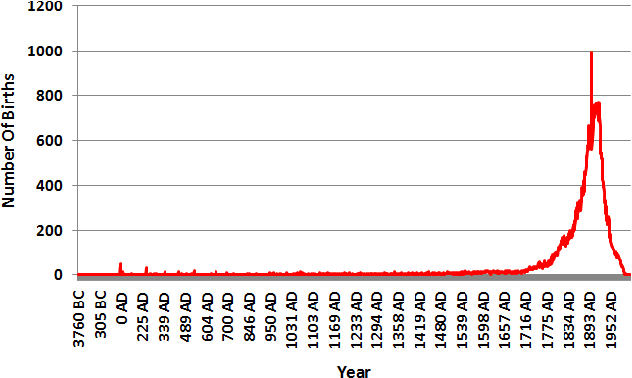

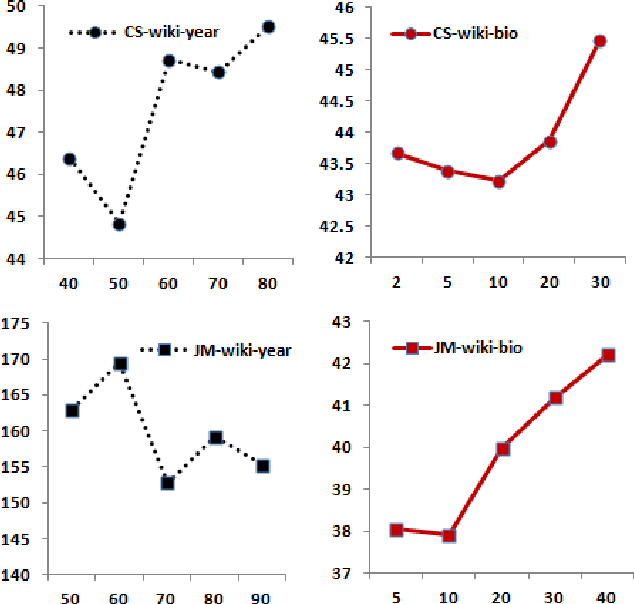
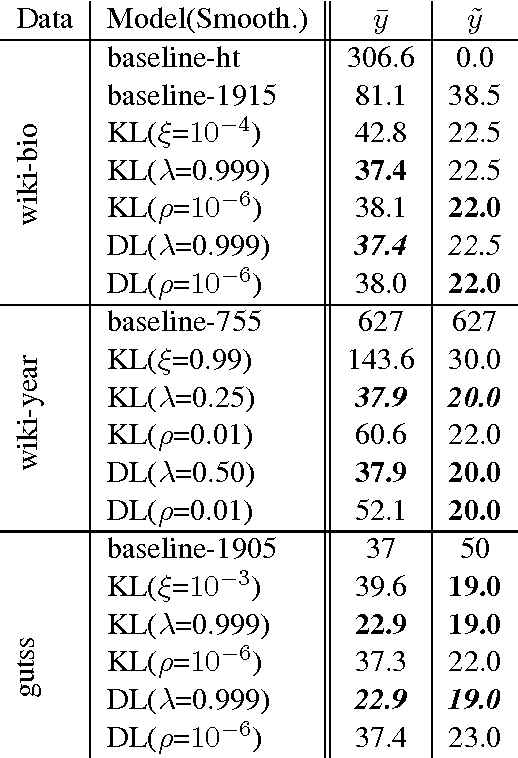
This paper tackles temporal resolution of documents, such as determining when a document is about or when it was written, based only on its text. We apply techniques from information retrieval that predict dates via language models over a discretized timeline. Unlike most previous works, we rely {\it solely} on temporal cues implicit in the text. We consider both document-likelihood and divergence based techniques and several smoothing methods for both of them. Our best model predicts the mid-point of individuals' lives with a median of 22 and mean error of 36 years for Wikipedia biographies from 3800 B.C. to the present day. We also show that this approach works well when training on such biographies and predicting dates both for non-biographical Wikipedia pages about specific years (500 B.C. to 2010 A.D.) and for publication dates of short stories (1798 to 2008). Together, our work shows that, even in absence of temporal extraction resources, it is possible to achieve remarkable temporal locality across a diverse set of texts.