 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen LLMs get significantly worse: A statistical approach to detect model degradations
Feb 09, 2026Minimizing the inference cost and latency of foundation models has become a crucial area of research. Optimization approaches include theoretically lossless methods and others without accuracy guarantees like quantization. In all of these cases it is crucial to ensure that the model quality has not degraded. However, even at temperature zero, model generations are not necessarily robust even to theoretically lossless model optimizations due to numerical errors. We thus require statistical tools to decide whether a finite-sample accuracy deviation is an evidence of a model's degradation or whether it can be attributed to (harmless) noise in the evaluation. We propose a statistically sound hypothesis testing framework based on McNemar's test allowing to efficiently detect model degradations, while guaranteeing a controlled rate of false positives. The crucial insight is that we have to confront the model scores on each sample, rather than aggregated on the task level. Furthermore, we propose three approaches to aggregate accuracy estimates across multiple benchmarks into a single decision. We provide an implementation on top of the largely adopted open source LM Evaluation Harness and provide a case study illustrating that the method correctly flags degraded models, while not flagging model optimizations that are provably lossless. We find that with our tests even empirical accuracy degradations of 0.3% can be confidently attributed to actual degradations rather than noise.
* https://openreview.net/forum?id=cM3gsqEI4K
Bridging Music and Text with Crowdsourced Music Comments: A Sequence-to-Sequence Framework for Thematic Music Comments Generation
Sep 05, 2022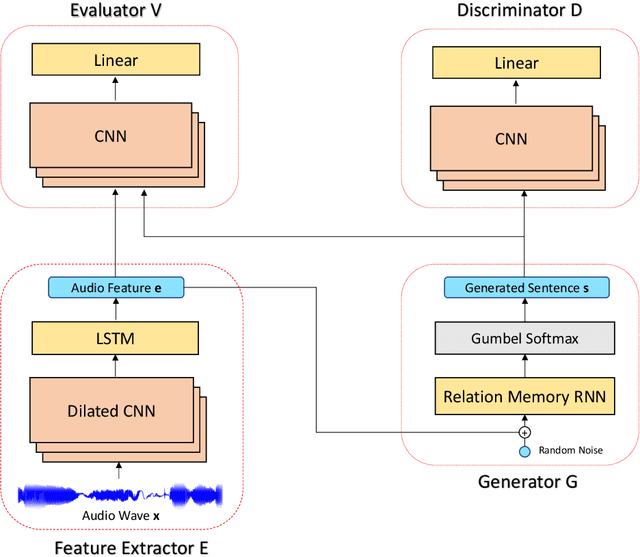
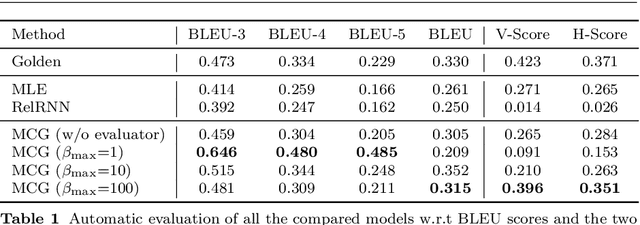
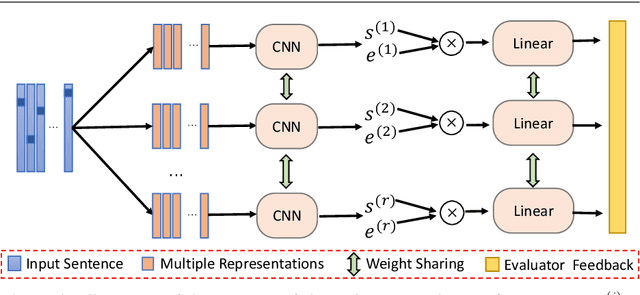

We consider a novel task of automatically generating text descriptions of music. Compared with other well-established text generation tasks such as image caption, the scarcity of well-paired music and text datasets makes it a much more challenging task. In this paper, we exploit the crowd-sourced music comments to construct a new dataset and propose a sequence-to-sequence model to generate text descriptions of music. More concretely, we use the dilated convolutional layer as the basic component of the encoder and a memory based recurrent neural network as the decoder. To enhance the authenticity and thematicity of generated texts, we further propose to fine-tune the model with a discriminator as well as a novel topic evaluator. To measure the quality of generated texts, we also propose two new evaluation metrics, which are more aligned with human evaluation than traditional metrics such as BLEU. Experimental results verify that our model is capable of generating fluent and meaningful comments while containing thematic and content information of the original music.
Thompson Sampling for Bandit Learning in Matching Markets
May 02, 2022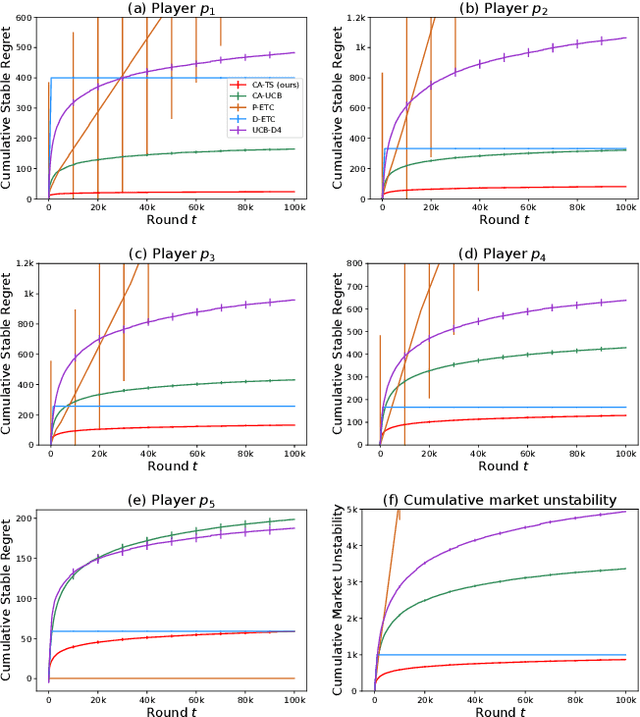
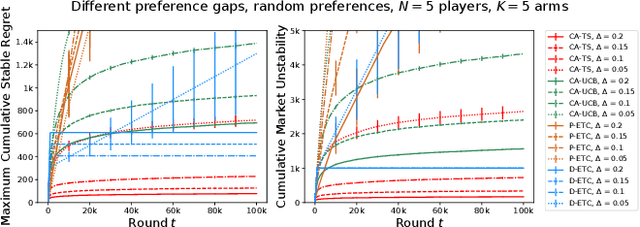
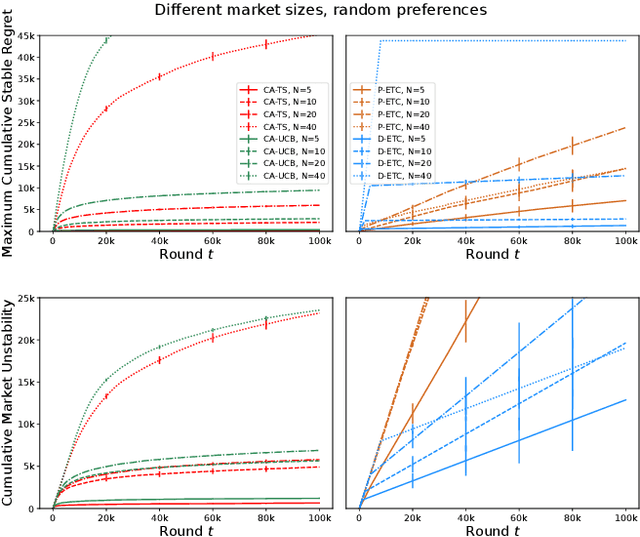
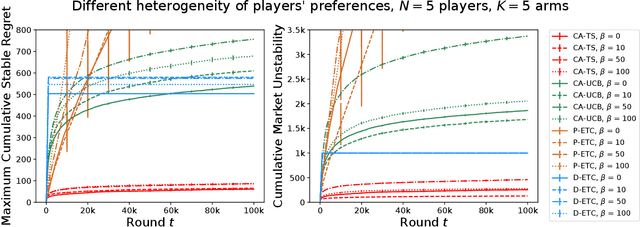
The problem of two-sided matching markets has a wide range of real-world applications and has been extensively studied in the literature. A line of recent works have focused on the problem setting where the preferences of one-side market participants are unknown \emph{a priori} and are learned by iteratively interacting with the other side of participants. All these works are based on explore-then-commit (ETC) and upper confidence bound (UCB) algorithms, two common strategies in multi-armed bandits (MAB). Thompson sampling (TS) is another popular approach, which attracts lots of attention due to its easier implementation and better empirical performances. In many problems, even when UCB and ETC-type algorithms have already been analyzed, researchers are still trying to study TS for its benefits. However, the convergence analysis of TS is much more challenging and remains open in many problem settings. In this paper, we provide the first regret analysis for TS in the new setting of iterative matching markets. Extensive experiments demonstrate the practical advantages of the TS-type algorithm over the ETC and UCB-type baselines.
Deep Reinforcement Learning for Personalized Search Story Recommendation
Jul 26, 2019
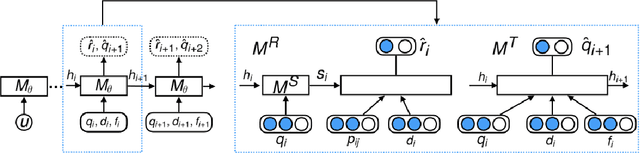
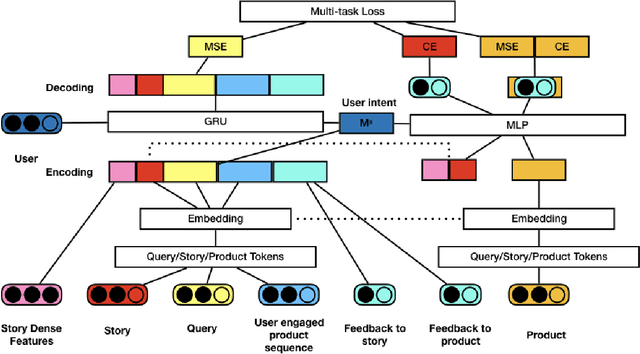
In recent years, \emph{search story}, a combined display with other organic channels, has become a major source of user traffic on platforms such as e-commerce search platforms, news feed platforms and web and image search platforms. The recommended search story guides a user to identify her own preference and personal intent, which subsequently influences the user's real-time and long-term search behavior. %With such an increased importance of search stories, As search stories become increasingly important, in this work, we study the problem of personalized search story recommendation within a search engine, which aims to suggest a search story relevant to both a search keyword and an individual user's interest. To address the challenge of modeling both immediate and future values of recommended search stories (i.e., cross-channel effect), for which conventional supervised learning framework is not applicable, we resort to a Markov decision process and propose a deep reinforcement learning architecture trained by both imitation learning and reinforcement learning. We empirically demonstrate the effectiveness of our proposed approach through extensive experiments on real-world data sets from JD.com.
Multi-Label Annotation Aggregation in Crowdsourcing
Jun 19, 2017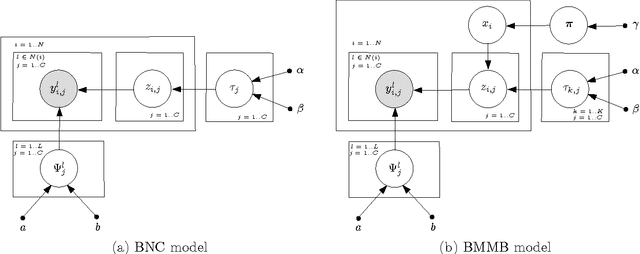

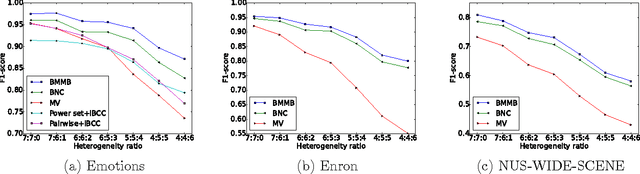
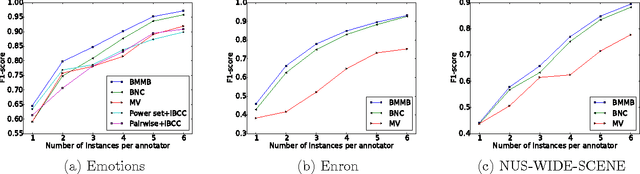
As a means of human-based computation, crowdsourcing has been widely used to annotate large-scale unlabeled datasets. One of the obvious challenges is how to aggregate these possibly noisy labels provided by a set of heterogeneous annotators. Another challenge stems from the difficulty in evaluating the annotator reliability without even knowing the ground truth, which can be used to build incentive mechanisms in crowdsourcing platforms. When each instance is associated with many possible labels simultaneously, the problem becomes even harder because of its combinatorial nature. In this paper, we present new flexible Bayesian models and efficient inference algorithms for multi-label annotation aggregation by taking both annotator reliability and label dependency into account. Extensive experiments on real-world datasets confirm that the proposed methods outperform other competitive alternatives, and the model can recover the type of the annotators with high accuracy. Besides, we empirically find that the mixture of multiple independent Bernoulli distribution is able to accurately capture label dependency in this unsupervised multi-label annotation aggregation scenario.
Convex-constrained Sparse Additive Modeling and Its Extensions
May 01, 2017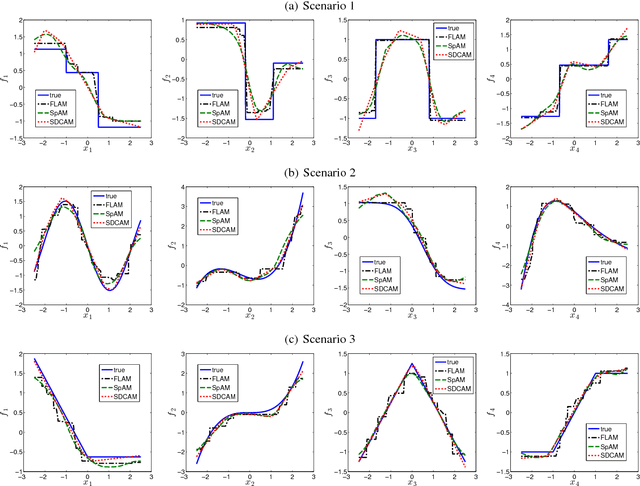

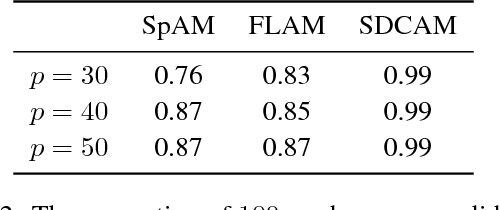
Sparse additive modeling is a class of effective methods for performing high-dimensional nonparametric regression. In this work we show how shape constraints such as convexity/concavity and their extensions, can be integrated into additive models. The proposed sparse difference of convex additive models (SDCAM) can estimate most continuous functions without any a priori smoothness assumption. Motivated by a characterization of difference of convex functions, our method incorporates a natural regularization functional to avoid overfitting and to reduce model complexity. Computationally, we develop an efficient backfitting algorithm with linear per-iteration complexity. Experiments on both synthetic and real data verify that our method is competitive against state-of-the-art sparse additive models, with improved performance in most scenarios.
Scalable Link Prediction in Dynamic Networks via Non-Negative Matrix Factorization
Jul 23, 2016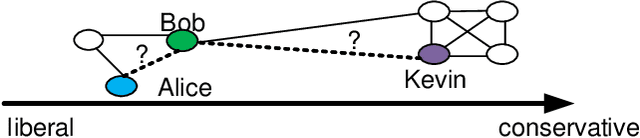

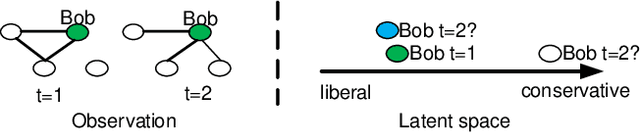
We propose a scalable temporal latent space model for link prediction in dynamic social networks, where the goal is to predict links over time based on a sequence of previous graph snapshots. The model assumes that each user lies in an unobserved latent space and interactions are more likely to form between similar users in the latent space representation. In addition, the model allows each user to gradually move its position in the latent space as the network structure evolves over time. We present a global optimization algorithm to effectively infer the temporal latent space, with a quadratic convergence rate. Two alternative optimization algorithms with local and incremental updates are also proposed, allowing the model to scale to larger networks without compromising prediction accuracy. Empirically, we demonstrate that our model, when evaluated on a number of real-world dynamic networks, significantly outperforms existing approaches for temporal link prediction in terms of both scalability and predictive power.
Distributed Training of Deep Neural Networks with Theoretical Analysis: Under SSP Setting
Dec 11, 2015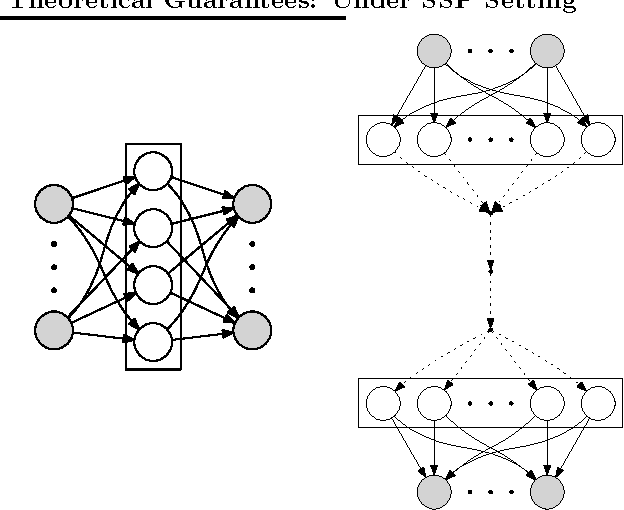

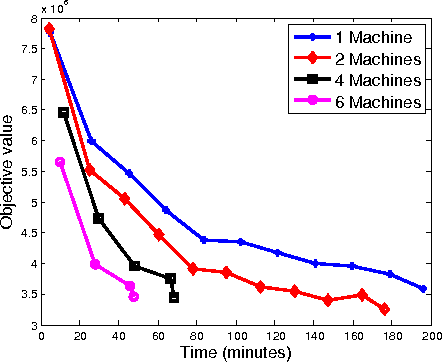
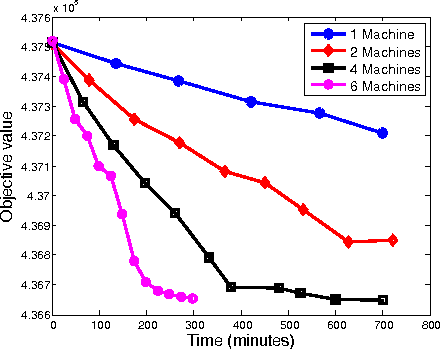
We propose a distributed approach to train deep neural networks (DNNs), which has guaranteed convergence theoretically and great scalability empirically: close to 6 times faster on instance of ImageNet data set when run with 6 machines. The proposed scheme is close to optimally scalable in terms of number of machines, and guaranteed to converge to the same optima as the undistributed setting. The convergence and scalability of the distributed setting is shown empirically across different datasets (TIMIT and ImageNet) and machine learning tasks (image classification and phoneme extraction). The convergence analysis provides novel insights into this complex learning scheme, including: 1) layerwise convergence, and 2) convergence of the weights in probability.
Group Sparse Additive Models
Jun 18, 2012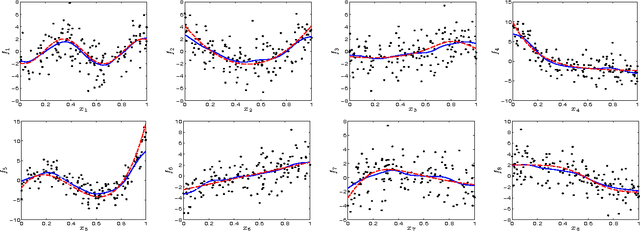
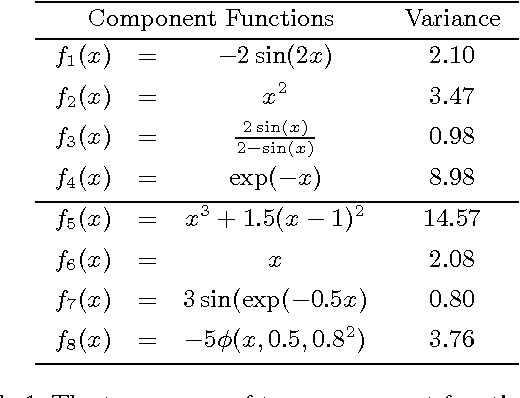
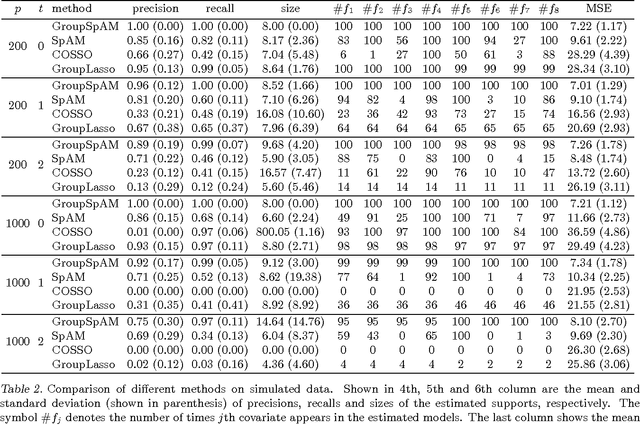
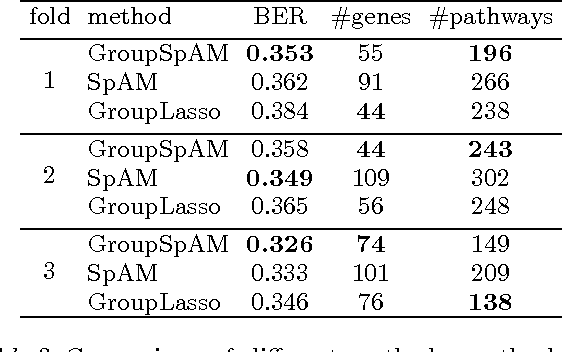
We consider the problem of sparse variable selection in nonparametric additive models, with the prior knowledge of the structure among the covariates to encourage those variables within a group to be selected jointly. Previous works either study the group sparsity in the parametric setting (e.g., group lasso), or address the problem in the non-parametric setting without exploiting the structural information (e.g., sparse additive models). In this paper, we present a new method, called group sparse additive models (GroupSpAM), which can handle group sparsity in additive models. We generalize the l1/l2 norm to Hilbert spaces as the sparsity-inducing penalty in GroupSpAM. Moreover, we derive a novel thresholding condition for identifying the functional sparsity at the group level, and propose an efficient block coordinate descent algorithm for constructing the estimate. We demonstrate by simulation that GroupSpAM substantially outperforms the competing methods in terms of support recovery and prediction accuracy in additive models, and also conduct a comparative experiment on a real breast cancer dataset.