 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Native Continuation for Action Chunking Flow Policies
Feb 13, 2026Action chunking enables Vision Language Action (VLA) models to run in real time, but naive chunked execution often exhibits discontinuities at chunk boundaries. Real-Time Chunking (RTC) alleviates this issue but is external to the policy, leading to spurious multimodal switching and trajectories that are not intrinsically smooth. We propose Legato, a training-time continuation method for action-chunked flow-based VLA policies. Specifically, Legato initializes denoising from a schedule-shaped mixture of known actions and noise, exposing the model to partial action information. Moreover, Legato reshapes the learned flow dynamics to ensure that the denoising process remains consistent between training and inference under per-step guidance. Legato further uses randomized schedule condition during training to support varying inference delays and achieve controllable smoothness. Empirically, Legato produces smoother trajectories and reduces spurious multimodal switching during execution, leading to less hesitation and shorter task completion time. Extensive real-world experiments show that Legato consistently outperforms RTC across five manipulation tasks, achieving approximately 10% improvements in both trajectory smoothness and task completion time.
Point What You Mean: Visually Grounded Instruction Policy
Dec 22, 2025
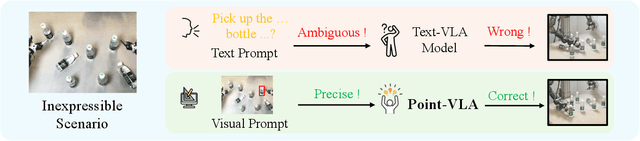
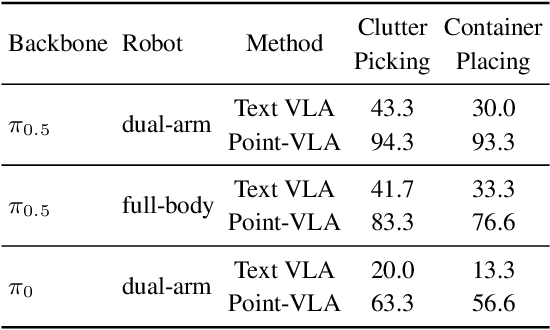
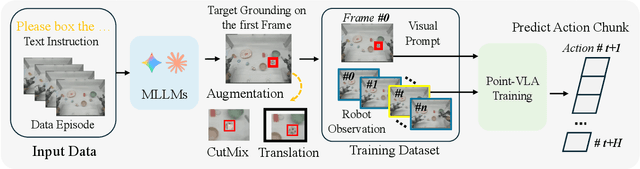
Vision-Language-Action (VLA) models align vision and language with embodied control, but their object referring ability remains limited when relying solely on text prompt, especially in cluttered or out-of-distribution (OOD) scenes. In this study, we introduce the Point-VLA, a plug-and-play policy that augments language instructions with explicit visual cues (e.g., bounding boxes) to resolve referential ambiguity and enable precise object-level grounding. To efficiently scale visually grounded datasets, we further develop an automatic data annotation pipeline requiring minimal human effort. We evaluate Point-VLA on diverse real-world referring tasks and observe consistently stronger performance than text-only instruction VLAs, particularly in cluttered or unseen-object scenarios, with robust generalization. These results demonstrate that Point-VLA effectively resolves object referring ambiguity through pixel-level visual grounding, achieving more generalizable embodied control.
Geometry Forcing: Marrying Video Diffusion and 3D Representation for Consistent World Modeling
Jul 10, 2025Videos inherently represent 2D projections of a dynamic 3D world. However, our analysis suggests that video diffusion models trained solely on raw video data often fail to capture meaningful geometric-aware structure in their learned representations. To bridge this gap between video diffusion models and the underlying 3D nature of the physical world, we propose Geometry Forcing, a simple yet effective method that encourages video diffusion models to internalize latent 3D representations. Our key insight is to guide the model's intermediate representations toward geometry-aware structure by aligning them with features from a pretrained geometric foundation model. To this end, we introduce two complementary alignment objectives: Angular Alignment, which enforces directional consistency via cosine similarity, and Scale Alignment, which preserves scale-related information by regressing unnormalized geometric features from normalized diffusion representation. We evaluate Geometry Forcing on both camera view-conditioned and action-conditioned video generation tasks. Experimental results demonstrate that our method substantially improves visual quality and 3D consistency over the baseline methods. Project page: https://GeometryForcing.github.io.
MineWorld: a Real-Time and Open-Source Interactive World Model on Minecraft
Apr 11, 2025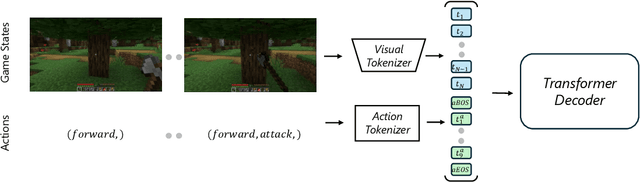

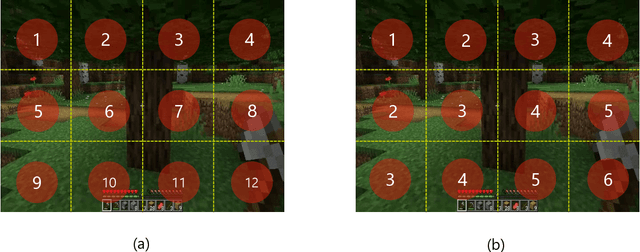
World modeling is a crucial task for enabling intelligent agents to effectively interact with humans and operate in dynamic environments. In this work, we propose MineWorld, a real-time interactive world model on Minecraft, an open-ended sandbox game which has been utilized as a common testbed for world modeling. MineWorld is driven by a visual-action autoregressive Transformer, which takes paired game scenes and corresponding actions as input, and generates consequent new scenes following the actions. Specifically, by transforming visual game scenes and actions into discrete token ids with an image tokenizer and an action tokenizer correspondingly, we consist the model input with the concatenation of the two kinds of ids interleaved. The model is then trained with next token prediction to learn rich representations of game states as well as the conditions between states and actions simultaneously. In inference, we develop a novel parallel decoding algorithm that predicts the spatial redundant tokens in each frame at the same time, letting models in different scales generate $4$ to $7$ frames per second and enabling real-time interactions with game players. In evaluation, we propose new metrics to assess not only visual quality but also the action following capacity when generating new scenes, which is crucial for a world model. Our comprehensive evaluation shows the efficacy of MineWorld, outperforming SoTA open-sourced diffusion based world models significantly. The code and model have been released.
Fast Autoregressive Video Generation with Diagonal Decoding
Mar 18, 2025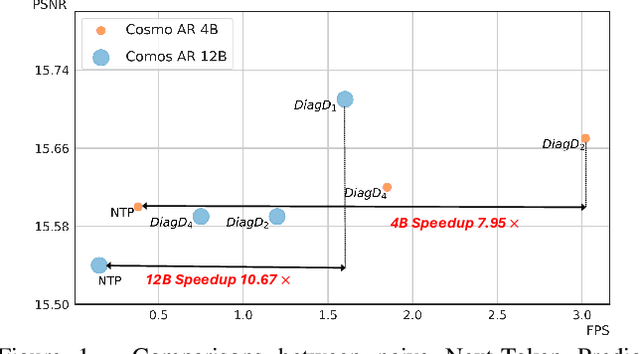
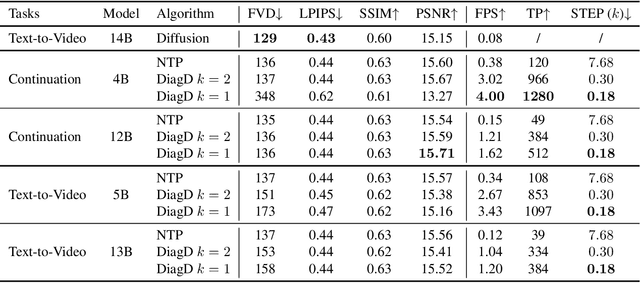
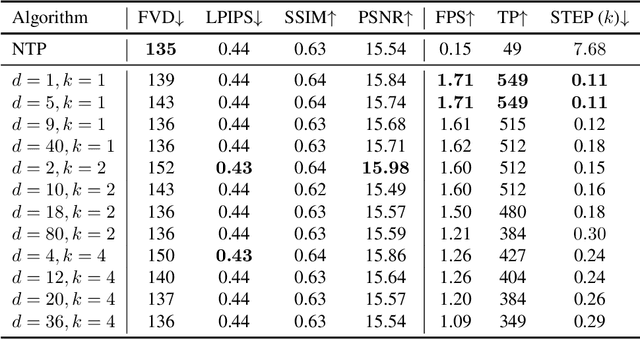
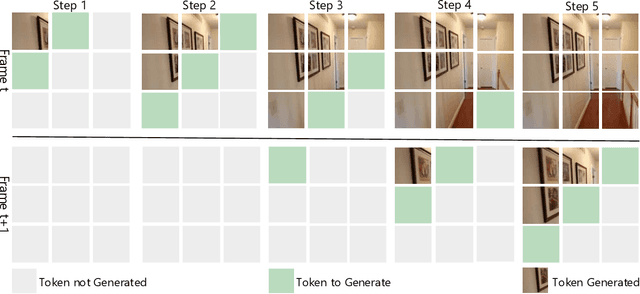
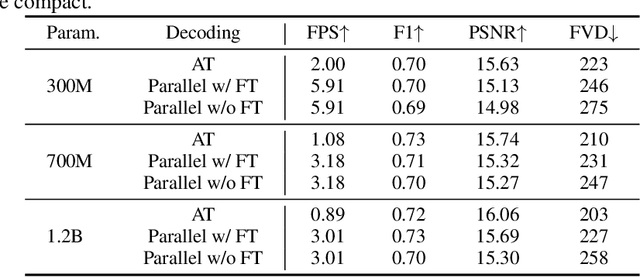
Autoregressive Transformer models have demonstrated impressive performance in video generation, but their sequential token-by-token decoding process poses a major bottleneck, particularly for long videos represented by tens of thousands of tokens. In this paper, we propose Diagonal Decoding (DiagD), a training-free inference acceleration algorithm for autoregressively pre-trained models that exploits spatial and temporal correlations in videos. Our method generates tokens along diagonal paths in the spatial-temporal token grid, enabling parallel decoding within each frame as well as partially overlapping across consecutive frames. The proposed algorithm is versatile and adaptive to various generative models and tasks, while providing flexible control over the trade-off between inference speed and visual quality. Furthermore, we propose a cost-effective finetuning strategy that aligns the attention patterns of the model with our decoding order, further mitigating the training-inference gap on small-scale models. Experiments on multiple autoregressive video generation models and datasets demonstrate that DiagD achieves up to $10\times$ speedup compared to naive sequential decoding, while maintaining comparable visual fidelity.
AR4D: Autoregressive 4D Generation from Monocular Videos
Jan 03, 2025



Recent advancements in generative models have ignited substantial interest in dynamic 3D content creation (\ie, 4D generation). Existing approaches primarily rely on Score Distillation Sampling (SDS) to infer novel-view videos, typically leading to issues such as limited diversity, spatial-temporal inconsistency and poor prompt alignment, due to the inherent randomness of SDS. To tackle these problems, we propose AR4D, a novel paradigm for SDS-free 4D generation. Specifically, our paradigm consists of three stages. To begin with, for a monocular video that is either generated or captured, we first utilize pre-trained expert models to create a 3D representation of the first frame, which is further fine-tuned to serve as the canonical space. Subsequently, motivated by the fact that videos happen naturally in an autoregressive manner, we propose to generate each frame's 3D representation based on its previous frame's representation, as this autoregressive generation manner can facilitate more accurate geometry and motion estimation. Meanwhile, to prevent overfitting during this process, we introduce a progressive view sampling strategy, utilizing priors from pre-trained large-scale 3D reconstruction models. To avoid appearance drift introduced by autoregressive generation, we further incorporate a refinement stage based on a global deformation field and the geometry of each frame's 3D representation. Extensive experiments have demonstrated that AR4D can achieve state-of-the-art 4D generation without SDS, delivering greater diversity, improved spatial-temporal consistency, and better alignment with input prompts.
VidTwin: Video VAE with Decoupled Structure and Dynamics
Dec 23, 2024Recent advancements in video autoencoders (Video AEs) have significantly improved the quality and efficiency of video generation. In this paper, we propose a novel and compact video autoencoder, VidTwin, that decouples video into two distinct latent spaces: Structure latent vectors, which capture overall content and global movement, and Dynamics latent vectors, which represent fine-grained details and rapid movements. Specifically, our approach leverages an Encoder-Decoder backbone, augmented with two submodules for extracting these latent spaces, respectively. The first submodule employs a Q-Former to extract low-frequency motion trends, followed by downsampling blocks to remove redundant content details. The second averages the latent vectors along the spatial dimension to capture rapid motion. Extensive experiments show that VidTwin achieves a high compression rate of 0.20% with high reconstruction quality (PSNR of 28.14 on the MCL-JCV dataset), and performs efficiently and effectively in downstream generative tasks. Moreover, our model demonstrates explainability and scalability, paving the way for future research in video latent representation and generation. Our code has been released at https://github.com/microsoft/VidTok/tree/main/vidtwin.
VidTok: A Versatile and Open-Source Video Tokenizer
Dec 17, 2024



Encoding video content into compact latent tokens has become a fundamental step in video generation and understanding, driven by the need to address the inherent redundancy in pixel-level representations. Consequently, there is a growing demand for high-performance, open-source video tokenizers as video-centric research gains prominence. We introduce VidTok, a versatile video tokenizer that delivers state-of-the-art performance in both continuous and discrete tokenizations. VidTok incorporates several key advancements over existing approaches: 1) model architecture such as convolutional layers and up/downsampling modules; 2) to address the training instability and codebook collapse commonly associated with conventional Vector Quantization (VQ), we integrate Finite Scalar Quantization (FSQ) into discrete video tokenization; 3) improved training strategies, including a two-stage training process and the use of reduced frame rates. By integrating these advancements, VidTok achieves substantial improvements over existing methods, demonstrating superior performance across multiple metrics, including PSNR, SSIM, LPIPS, and FVD, under standardized evaluation settings.
Predictor-Corrector Enhanced Transformers with Exponential Moving Average Coefficient Learning
Nov 05, 2024Residual networks, as discrete approximations of Ordinary Differential Equations (ODEs), have inspired significant advancements in neural network design, including multistep methods, high-order methods, and multi-particle dynamical systems. The precision of the solution to ODEs significantly affects parameter optimization, thereby impacting model performance. In this work, we present a series of advanced explorations of Transformer architecture design to minimize the error compared to the true ``solution.'' First, we introduce a predictor-corrector learning framework to minimize truncation errors, which consists of a high-order predictor and a multistep corrector. Second, we propose an exponential moving average-based coefficient learning method to strengthen our higher-order predictor. Extensive experiments on large-scale machine translation, abstractive summarization, language modeling, and natural language understanding benchmarks demonstrate the superiority of our approach. On the WMT'14 English-German and English-French tasks, our model achieved BLEU scores of 30.95 and 44.27, respectively. Furthermore, on the OPUS multilingual machine translation task, our model surpasses a robust 3.8B DeepNet by an average of 2.9 SacreBLEU, using only 1/3 parameters. Notably, it also beats LLama models by 5.7 accuracy points on the LM Harness Evaluation.
Compositional 3D-aware Video Generation with LLM Director
Aug 31, 2024



Significant progress has been made in text-to-video generation through the use of powerful generative models and large-scale internet data. However, substantial challenges remain in precisely controlling individual concepts within the generated video, such as the motion and appearance of specific characters and the movement of viewpoints. In this work, we propose a novel paradigm that generates each concept in 3D representation separately and then composes them with priors from Large Language Models (LLM) and 2D diffusion models. Specifically, given an input textual prompt, our scheme consists of three stages: 1) We leverage LLM as the director to first decompose the complex query into several sub-prompts that indicate individual concepts within the video~(\textit{e.g.}, scene, objects, motions), then we let LLM to invoke pre-trained expert models to obtain corresponding 3D representations of concepts. 2) To compose these representations, we prompt multi-modal LLM to produce coarse guidance on the scales and coordinates of trajectories for the objects. 3) To make the generated frames adhere to natural image distribution, we further leverage 2D diffusion priors and use Score Distillation Sampling to refine the composition. Extensive experiments demonstrate that our method can generate high-fidelity videos from text with diverse motion and flexible control over each concept. Project page: \url{https://aka.ms/c3v}.