 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIVE: Long-horizon Interactive Video World Modeling
Feb 03, 2026Autoregressive video world models predict future visual observations conditioned on actions. While effective over short horizons, these models often struggle with long-horizon generation, as small prediction errors accumulate over time. Prior methods alleviate this by introducing pre-trained teacher models and sequence-level distribution matching, which incur additional computational cost and fail to prevent error propagation beyond the training horizon. In this work, we propose LIVE, a Long-horizon Interactive Video world modEl that enforces bounded error accumulation via a novel cycle-consistency objective, thereby eliminating the need for teacher-based distillation. Specifically, LIVE first performs a forward rollout from ground-truth frames and then applies a reverse generation process to reconstruct the initial state. The diffusion loss is subsequently computed on the reconstructed terminal state, providing an explicit constraint on long-horizon error propagation. Moreover, we provide an unified view that encompasses different approaches and introduce progressive training curriculum to stabilize training. Experiments demonstrate that LIVE achieves state-of-the-art performance on long-horizon benchmarks, generating stable, high-quality videos far beyond training rollout lengths.
Luminark: Training-free, Probabilistically-Certified Watermarking for General Vision Generative Models
Jan 03, 2026In this paper, we introduce \emph{Luminark}, a training-free and probabilistically-certified watermarking method for general vision generative models. Our approach is built upon a novel watermark definition that leverages patch-level luminance statistics. Specifically, the service provider predefines a binary pattern together with corresponding patch-level thresholds. To detect a watermark in a given image, we evaluate whether the luminance of each patch surpasses its threshold and then verify whether the resulting binary pattern aligns with the target one. A simple statistical analysis demonstrates that the false positive rate of the proposed method can be effectively controlled, thereby ensuring certified detection. To enable seamless watermark injection across different paradigms, we leverage the widely adopted guidance technique as a plug-and-play mechanism and develop the \emph{watermark guidance}. This design enables Luminark to achieve generality across state-of-the-art generative models without compromising image quality. Empirically, we evaluate our approach on nine models spanning diffusion, autoregressive, and hybrid frameworks. Across all evaluations, Luminark consistently demonstrates high detection accuracy, strong robustness against common image transformations, and good performance on visual quality.
Geometry Forcing: Marrying Video Diffusion and 3D Representation for Consistent World Modeling
Jul 10, 2025Videos inherently represent 2D projections of a dynamic 3D world. However, our analysis suggests that video diffusion models trained solely on raw video data often fail to capture meaningful geometric-aware structure in their learned representations. To bridge this gap between video diffusion models and the underlying 3D nature of the physical world, we propose Geometry Forcing, a simple yet effective method that encourages video diffusion models to internalize latent 3D representations. Our key insight is to guide the model's intermediate representations toward geometry-aware structure by aligning them with features from a pretrained geometric foundation model. To this end, we introduce two complementary alignment objectives: Angular Alignment, which enforces directional consistency via cosine similarity, and Scale Alignment, which preserves scale-related information by regressing unnormalized geometric features from normalized diffusion representation. We evaluate Geometry Forcing on both camera view-conditioned and action-conditioned video generation tasks. Experimental results demonstrate that our method substantially improves visual quality and 3D consistency over the baseline methods. Project page: https://GeometryForcing.github.io.
MineWorld: a Real-Time and Open-Source Interactive World Model on Minecraft
Apr 11, 2025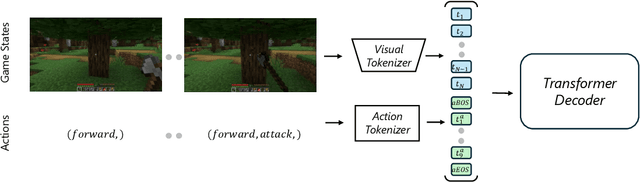

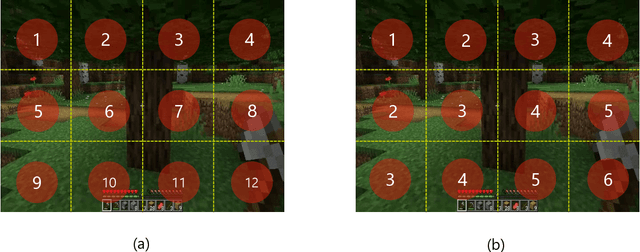
World modeling is a crucial task for enabling intelligent agents to effectively interact with humans and operate in dynamic environments. In this work, we propose MineWorld, a real-time interactive world model on Minecraft, an open-ended sandbox game which has been utilized as a common testbed for world modeling. MineWorld is driven by a visual-action autoregressive Transformer, which takes paired game scenes and corresponding actions as input, and generates consequent new scenes following the actions. Specifically, by transforming visual game scenes and actions into discrete token ids with an image tokenizer and an action tokenizer correspondingly, we consist the model input with the concatenation of the two kinds of ids interleaved. The model is then trained with next token prediction to learn rich representations of game states as well as the conditions between states and actions simultaneously. In inference, we develop a novel parallel decoding algorithm that predicts the spatial redundant tokens in each frame at the same time, letting models in different scales generate $4$ to $7$ frames per second and enabling real-time interactions with game players. In evaluation, we propose new metrics to assess not only visual quality but also the action following capacity when generating new scenes, which is crucial for a world model. Our comprehensive evaluation shows the efficacy of MineWorld, outperforming SoTA open-sourced diffusion based world models significantly. The code and model have been released.
Fast Autoregressive Video Generation with Diagonal Decoding
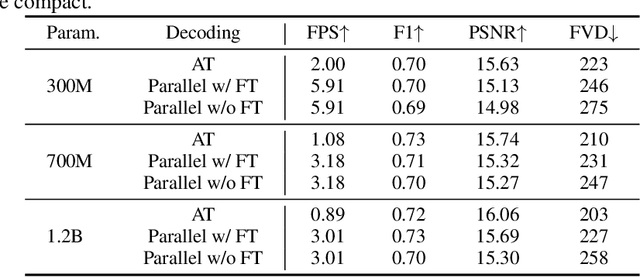
Mar 18, 2025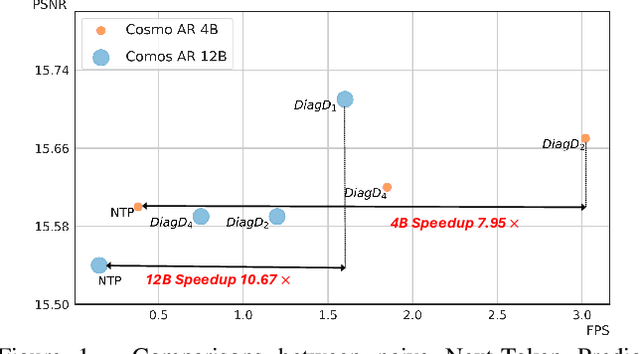
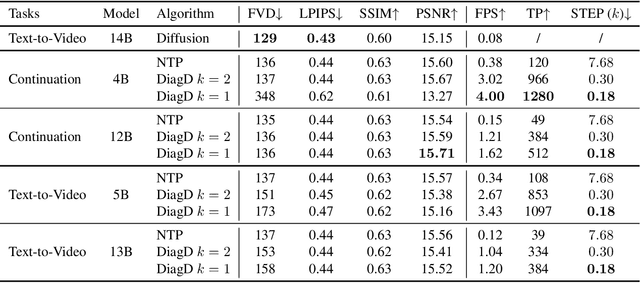
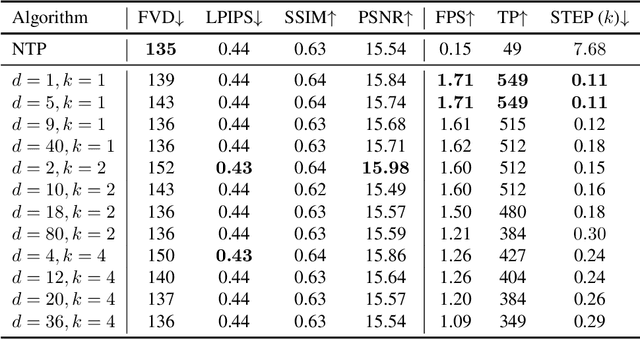
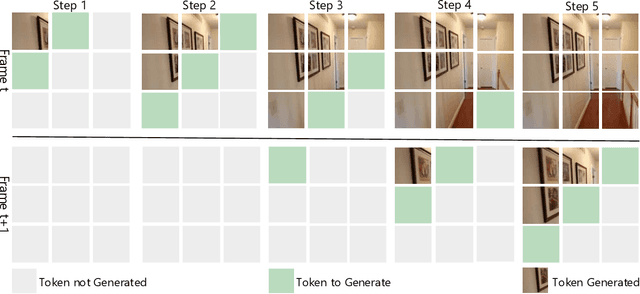
Autoregressive Transformer models have demonstrated impressive performance in video generation, but their sequential token-by-token decoding process poses a major bottleneck, particularly for long videos represented by tens of thousands of tokens. In this paper, we propose Diagonal Decoding (DiagD), a training-free inference acceleration algorithm for autoregressively pre-trained models that exploits spatial and temporal correlations in videos. Our method generates tokens along diagonal paths in the spatial-temporal token grid, enabling parallel decoding within each frame as well as partially overlapping across consecutive frames. The proposed algorithm is versatile and adaptive to various generative models and tasks, while providing flexible control over the trade-off between inference speed and visual quality. Furthermore, we propose a cost-effective finetuning strategy that aligns the attention patterns of the model with our decoding order, further mitigating the training-inference gap on small-scale models. Experiments on multiple autoregressive video generation models and datasets demonstrate that DiagD achieves up to $10\times$ speedup compared to naive sequential decoding, while maintaining comparable visual fidelity.
HiTVideo: Hierarchical Tokenizers for Enhancing Text-to-Video Generation with Autoregressive Large Language Models
Mar 14, 2025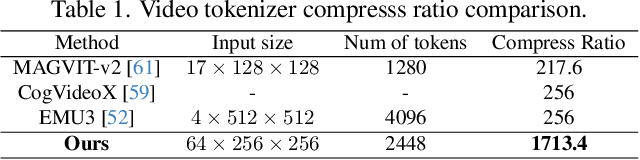
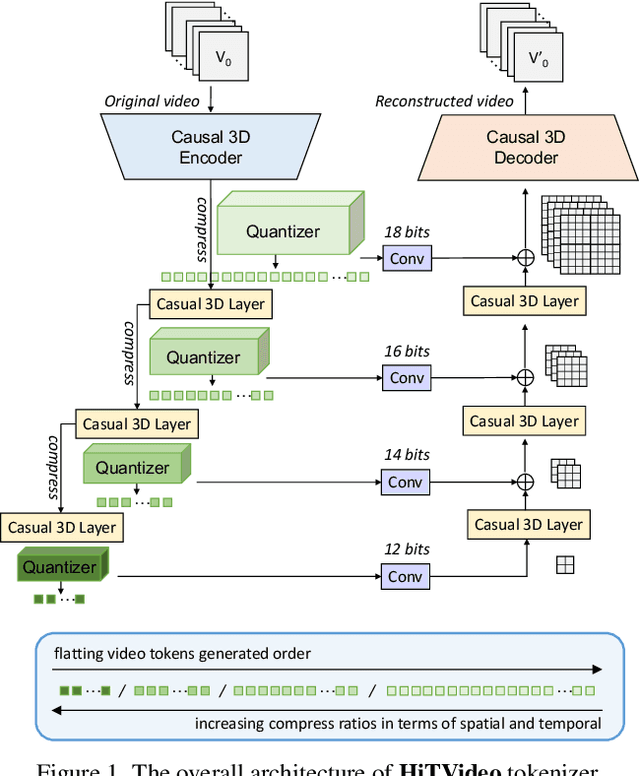
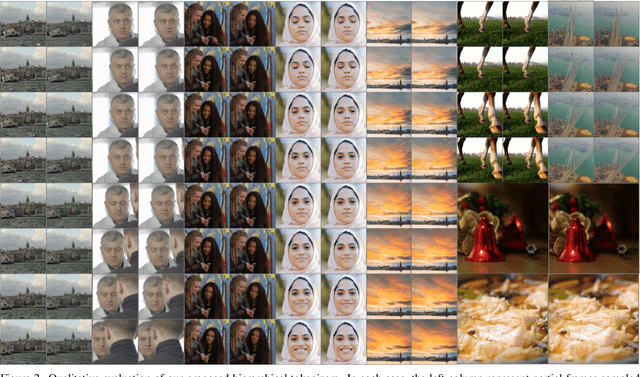

Text-to-video generation poses significant challenges due to the inherent complexity of video data, which spans both temporal and spatial dimensions. It introduces additional redundancy, abrupt variations, and a domain gap between language and vision tokens while generation. Addressing these challenges requires an effective video tokenizer that can efficiently encode video data while preserving essential semantic and spatiotemporal information, serving as a critical bridge between text and vision. Inspired by the observation in VQ-VAE-2 and workflows of traditional animation, we propose HiTVideo for text-to-video generation with hierarchical tokenizers. It utilizes a 3D causal VAE with a multi-layer discrete token framework, encoding video content into hierarchically structured codebooks. Higher layers capture semantic information with higher compression, while lower layers focus on fine-grained spatiotemporal details, striking a balance between compression efficiency and reconstruction quality. Our approach efficiently encodes longer video sequences (e.g., 8 seconds, 64 frames), reducing bits per pixel (bpp) by approximately 70\% compared to baseline tokenizers, while maintaining competitive reconstruction quality. We explore the trade-offs between compression and reconstruction, while emphasizing the advantages of high-compressed semantic tokens in text-to-video tasks. HiTVideo aims to address the potential limitations of existing video tokenizers in text-to-video generation tasks, striving for higher compression ratios and simplify LLMs modeling under language guidance, offering a scalable and promising framework for advancing text to video generation. Demo page: https://ziqinzhou66.github.io/project/HiTVideo.
AR4D: Autoregressive 4D Generation from Monocular Videos
Jan 03, 2025



Recent advancements in generative models have ignited substantial interest in dynamic 3D content creation (\ie, 4D generation). Existing approaches primarily rely on Score Distillation Sampling (SDS) to infer novel-view videos, typically leading to issues such as limited diversity, spatial-temporal inconsistency and poor prompt alignment, due to the inherent randomness of SDS. To tackle these problems, we propose AR4D, a novel paradigm for SDS-free 4D generation. Specifically, our paradigm consists of three stages. To begin with, for a monocular video that is either generated or captured, we first utilize pre-trained expert models to create a 3D representation of the first frame, which is further fine-tuned to serve as the canonical space. Subsequently, motivated by the fact that videos happen naturally in an autoregressive manner, we propose to generate each frame's 3D representation based on its previous frame's representation, as this autoregressive generation manner can facilitate more accurate geometry and motion estimation. Meanwhile, to prevent overfitting during this process, we introduce a progressive view sampling strategy, utilizing priors from pre-trained large-scale 3D reconstruction models. To avoid appearance drift introduced by autoregressive generation, we further incorporate a refinement stage based on a global deformation field and the geometry of each frame's 3D representation. Extensive experiments have demonstrated that AR4D can achieve state-of-the-art 4D generation without SDS, delivering greater diversity, improved spatial-temporal consistency, and better alignment with input prompts.
3D-LLaVA: Towards Generalist 3D LMMs with Omni Superpoint Transformer
Jan 02, 2025



Current 3D Large Multimodal Models (3D LMMs) have shown tremendous potential in 3D-vision-based dialogue and reasoning. However, how to further enhance 3D LMMs to achieve fine-grained scene understanding and facilitate flexible human-agent interaction remains a challenging problem. In this work, we introduce 3D-LLaVA, a simple yet highly powerful 3D LMM designed to act as an intelligent assistant in comprehending, reasoning, and interacting with the 3D world. Unlike existing top-performing methods that rely on complicated pipelines-such as offline multi-view feature extraction or additional task-specific heads-3D-LLaVA adopts a minimalist design with integrated architecture and only takes point clouds as input. At the core of 3D-LLaVA is a new Omni Superpoint Transformer (OST), which integrates three functionalities: (1) a visual feature selector that converts and selects visual tokens, (2) a visual prompt encoder that embeds interactive visual prompts into the visual token space, and (3) a referring mask decoder that produces 3D masks based on text description. This versatile OST is empowered by the hybrid pretraining to obtain perception priors and leveraged as the visual connector that bridges the 3D data to the LLM. After performing unified instruction tuning, our 3D-LLaVA reports impressive results on various benchmarks. The code and model will be released to promote future exploration.
VidTwin: Video VAE with Decoupled Structure and Dynamics
Dec 23, 2024Recent advancements in video autoencoders (Video AEs) have significantly improved the quality and efficiency of video generation. In this paper, we propose a novel and compact video autoencoder, VidTwin, that decouples video into two distinct latent spaces: Structure latent vectors, which capture overall content and global movement, and Dynamics latent vectors, which represent fine-grained details and rapid movements. Specifically, our approach leverages an Encoder-Decoder backbone, augmented with two submodules for extracting these latent spaces, respectively. The first submodule employs a Q-Former to extract low-frequency motion trends, followed by downsampling blocks to remove redundant content details. The second averages the latent vectors along the spatial dimension to capture rapid motion. Extensive experiments show that VidTwin achieves a high compression rate of 0.20% with high reconstruction quality (PSNR of 28.14 on the MCL-JCV dataset), and performs efficiently and effectively in downstream generative tasks. Moreover, our model demonstrates explainability and scalability, paving the way for future research in video latent representation and generation. Our code has been released at https://github.com/microsoft/VidTok/tree/main/vidtwin.
VidTok: A Versatile and Open-Source Video Tokenizer
Dec 17, 2024



Encoding video content into compact latent tokens has become a fundamental step in video generation and understanding, driven by the need to address the inherent redundancy in pixel-level representations. Consequently, there is a growing demand for high-performance, open-source video tokenizers as video-centric research gains prominence. We introduce VidTok, a versatile video tokenizer that delivers state-of-the-art performance in both continuous and discrete tokenizations. VidTok incorporates several key advancements over existing approaches: 1) model architecture such as convolutional layers and up/downsampling modules; 2) to address the training instability and codebook collapse commonly associated with conventional Vector Quantization (VQ), we integrate Finite Scalar Quantization (FSQ) into discrete video tokenization; 3) improved training strategies, including a two-stage training process and the use of reduced frame rates. By integrating these advancements, VidTok achieves substantial improvements over existing methods, demonstrating superior performance across multiple metrics, including PSNR, SSIM, LPIPS, and FVD, under standardized evaluation settings.