 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADNP-15: An Open-Source Histopathological Dataset for Neuritic Plaque Segmentation in Human Brain Whole Slide Images with Frequency Domain Image Enhancement for Stain Normalization
May 08, 2025Alzheimer's Disease (AD) is a neurodegenerative disorder characterized by amyloid-beta plaques and tau neurofibrillary tangles, which serve as key histopathological features. The identification and segmentation of these lesions are crucial for understanding AD progression but remain challenging due to the lack of large-scale annotated datasets and the impact of staining variations on automated image analysis. Deep learning has emerged as a powerful tool for pathology image segmentation; however, model performance is significantly influenced by variations in staining characteristics, necessitating effective stain normalization and enhancement techniques. In this study, we address these challenges by introducing an open-source dataset (ADNP-15) of neuritic plaques (i.e., amyloid deposits combined with a crown of dystrophic tau-positive neurites) in human brain whole slide images. We establish a comprehensive benchmark by evaluating five widely adopted deep learning models across four stain normalization techniques, providing deeper insights into their influence on neuritic plaque segmentation. Additionally, we propose a novel image enhancement method that improves segmentation accuracy, particularly in complex tissue structures, by enhancing structural details and mitigating staining inconsistencies. Our experimental results demonstrate that this enhancement strategy significantly boosts model generalization and segmentation accuracy. All datasets and code are open-source, ensuring transparency and reproducibility while enabling further advancements in the field.
Performance Estimation for Supervised Medical Image Segmentation Models on Unlabeled Data Using UniverSeg
Apr 22, 2025The performance of medical image segmentation models is usually evaluated using metrics like the Dice score and Hausdorff distance, which compare predicted masks to ground truth annotations. However, when applying the model to unseen data, such as in clinical settings, it is often impractical to annotate all the data, making the model's performance uncertain. To address this challenge, we propose the Segmentation Performance Evaluator (SPE), a framework for estimating segmentation models' performance on unlabeled data. This framework is adaptable to various evaluation metrics and model architectures. Experiments on six publicly available datasets across six evaluation metrics including pixel-based metrics such as Dice score and distance-based metrics like HD95, demonstrated the versatility and effectiveness of our approach, achieving a high correlation (0.956$\pm$0.046) and low MAE (0.025$\pm$0.019) compare with real Dice score on the independent test set. These results highlight its ability to reliably estimate model performance without requiring annotations. The SPE framework integrates seamlessly into any model training process without adding training overhead, enabling performance estimation and facilitating the real-world application of medical image segmentation algorithms. The source code is publicly available
In-Context Reverse Classification Accuracy: Efficient Estimation of Segmentation Quality without Ground-Truth
Mar 06, 2025Assessing the quality of automatic image segmentation is crucial in clinical practice, but often very challenging due to the limited availability of ground truth annotations. In this paper, we introduce In-Context Reverse Classification Accuracy (In-Context RCA), a novel framework for automatically estimating segmentation quality in the absence of ground-truth annotations. By leveraging recent in-context learning segmentation models and incorporating retrieval-augmentation techniques to select the most relevant reference images, our approach enables efficient quality estimation with minimal reference data. Validated across diverse medical imaging modalities, our method demonstrates robust performance and computational efficiency, offering a promising solution for automated quality control in clinical workflows, where fast and reliable segmentation assessment is essential. The code is available at https://github.com/mcosarinsky/In-Context-RCA.
Deep Learning-Based Feature Fusion for Emotion Analysis and Suicide Risk Differentiation in Chinese Psychological Support Hotlines
Jan 15, 2025



Mental health is a critical global public health issue, and psychological support hotlines play a pivotal role in providing mental health assistance and identifying suicide risks at an early stage. However, the emotional expressions conveyed during these calls remain underexplored in current research. This study introduces a method that combines pitch acoustic features with deep learning-based features to analyze and understand emotions expressed during hotline interactions. Using data from China's largest psychological support hotline, our method achieved an F1-score of 79.13% for negative binary emotion classification.Additionally, the proposed approach was validated on an open dataset for multi-class emotion classification,where it demonstrated better performance compared to the state-of-the-art methods. To explore its clinical relevance, we applied the model to analysis the frequency of negative emotions and the rate of emotional change in the conversation, comparing 46 subjects with suicidal behavior to those without. While the suicidal group exhibited more frequent emotional changes than the non-suicidal group, the difference was not statistically significant.Importantly, our findings suggest that emotional fluctuation intensity and frequency could serve as novel features for psychological assessment scales and suicide risk prediction.The proposed method provides valuable insights into emotional dynamics and has the potential to advance early intervention and improve suicide prevention strategies through integration with clinical tools and assessments The source code is publicly available at https://github.com/Sco-field/Speechemotionrecognition/tree/main.
SMILE-UHURA Challenge -- Small Vessel Segmentation at Mesoscopic Scale from Ultra-High Resolution 7T Magnetic Resonance Angiograms
Nov 14, 2024The human brain receives nutrients and oxygen through an intricate network of blood vessels. Pathology affecting small vessels, at the mesoscopic scale, represents a critical vulnerability within the cerebral blood supply and can lead to severe conditions, such as Cerebral Small Vessel Diseases. The advent of 7 Tesla MRI systems has enabled the acquisition of higher spatial resolution images, making it possible to visualise such vessels in the brain. However, the lack of publicly available annotated datasets has impeded the development of robust, machine learning-driven segmentation algorithms. To address this, the SMILE-UHURA challenge was organised. This challenge, held in conjunction with the ISBI 2023, in Cartagena de Indias, Colombia, aimed to provide a platform for researchers working on related topics. The SMILE-UHURA challenge addresses the gap in publicly available annotated datasets by providing an annotated dataset of Time-of-Flight angiography acquired with 7T MRI. This dataset was created through a combination of automated pre-segmentation and extensive manual refinement. In this manuscript, sixteen submitted methods and two baseline methods are compared both quantitatively and qualitatively on two different datasets: held-out test MRAs from the same dataset as the training data (with labels kept secret) and a separate 7T ToF MRA dataset where both input volumes and labels are kept secret. The results demonstrate that most of the submitted deep learning methods, trained on the provided training dataset, achieved reliable segmentation performance. Dice scores reached up to 0.838 $\pm$ 0.066 and 0.716 $\pm$ 0.125 on the respective datasets, with an average performance of up to 0.804 $\pm$ 0.15.
Topology and Intersection-Union Constrained Loss Function for Multi-Region Anatomical Segmentation in Ocular Images
Nov 01, 2024



Ocular Myasthenia Gravis (OMG) is a rare and challenging disease to detect in its early stages, but symptoms often first appear in the eye muscles, such as drooping eyelids and double vision. Ocular images can be used for early diagnosis by segmenting different regions, such as the sclera, iris, and pupil, which allows for the calculation of area ratios to support accurate medical assessments. However, no publicly available dataset and tools currently exist for this purpose. To address this, we propose a new topology and intersection-union constrained loss function (TIU loss) that improves performance using small training datasets. We conducted experiments on a public dataset consisting of 55 subjects and 2,197 images. Our proposed method outperformed two widely used loss functions across three deep learning networks, achieving a mean Dice score of 83.12% [82.47%, 83.81%] with a 95% bootstrap confidence interval. In a low-percentage training scenario (10% of the training data), our approach showed an 8.32% improvement in Dice score compared to the baseline. Additionally, we evaluated the method in a clinical setting with 47 subjects and 501 images, achieving a Dice score of 64.44% [63.22%, 65.62%]. We did observe some bias when applying the model in clinical settings. These results demonstrate that the proposed method is accurate, and our code along with the trained model is publicly available.
MentalGLM Series: Explainable Large Language Models for Mental Health Analysis on Chinese Social Media
Oct 14, 2024
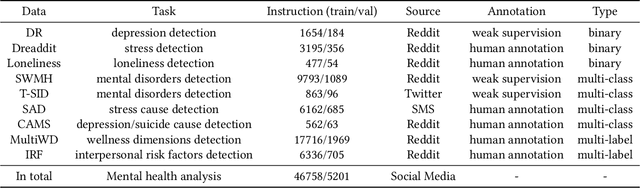
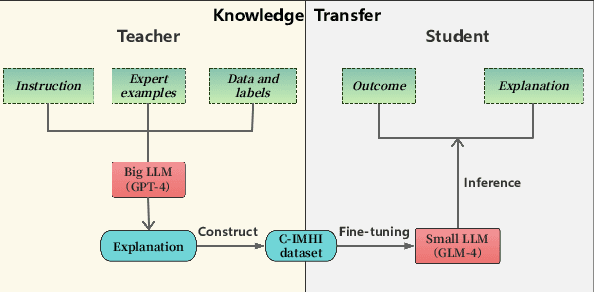

As the prevalence of mental health challenges, social media has emerged as a key platform for individuals to express their emotions.Deep learning tends to be a promising solution for analyzing mental health on social media. However, black box models are often inflexible when switching between tasks, and their results typically lack explanations. With the rise of large language models (LLMs), their flexibility has introduced new approaches to the field. Also due to the generative nature, they can be prompted to explain decision-making processes. However, their performance on complex psychological analysis still lags behind deep learning. In this paper, we introduce the first multi-task Chinese Social Media Interpretable Mental Health Instructions (C-IMHI) dataset, consisting of 9K samples, which has been quality-controlled and manually validated. We also propose MentalGLM series models, the first open-source LLMs designed for explainable mental health analysis targeting Chinese social media, trained on a corpus of 50K instructions. The proposed models were evaluated on three downstream tasks and achieved better or comparable performance compared to deep learning models, generalized LLMs, and task fine-tuned LLMs. We validated a portion of the generated decision explanations with experts, showing promising results. We also evaluated the proposed models on a clinical dataset, where they outperformed other LLMs, indicating their potential applicability in the clinical field. Our models show strong performance, validated across tasks and perspectives. The decision explanations enhance usability and facilitate better understanding and practical application of the models. Both the constructed dataset and the models are publicly available via: https://github.com/zwzzzQAQ/MentalGLM.
Deep Learning and Large Language Models for Audio and Text Analysis in Predicting Suicidal Acts in Chinese Psychological Support Hotlines
Sep 10, 2024



Suicide is a pressing global issue, demanding urgent and effective preventive interventions. Among the various strategies in place, psychological support hotlines had proved as a potent intervention method. Approximately two million people in China attempt suicide annually, with many individuals making multiple attempts. Prompt identification and intervention for high-risk individuals are crucial to preventing tragedies. With the rapid advancement of artificial intelligence (AI), especially the development of large-scale language models (LLMs), new technological tools have been introduced to the field of mental health. This study included 1284 subjects, and was designed to validate whether deep learning models and LLMs, using audio and transcribed text from support hotlines, can effectively predict suicide risk. We proposed a simple LLM-based pipeline that first summarizes transcribed text from approximately one hour of speech to extract key features, and then predict suicidial bahaviours in the future. We compared our LLM-based method with the traditional manual scale approach in a clinical setting and with five advanced deep learning models. Surprisingly, the proposed simple LLM pipeline achieved strong performance on a test set of 46 subjects, with an F1 score of 76\% when combined with manual scale rating. This is 7\% higher than the best speech-based deep learning models and represents a 27.82\% point improvement in F1 score compared to using the manual scale apporach alone. Our study explores new applications of LLMs and demonstrates their potential for future use in suicide prevention efforts.
An Exploratory Deep Learning Approach for Predicting Subsequent Suicidal Acts in Chinese Psychological Support Hotlines
Aug 29, 2024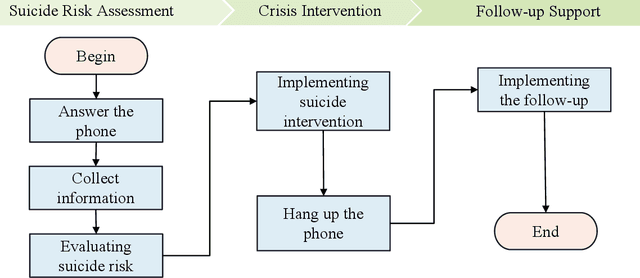

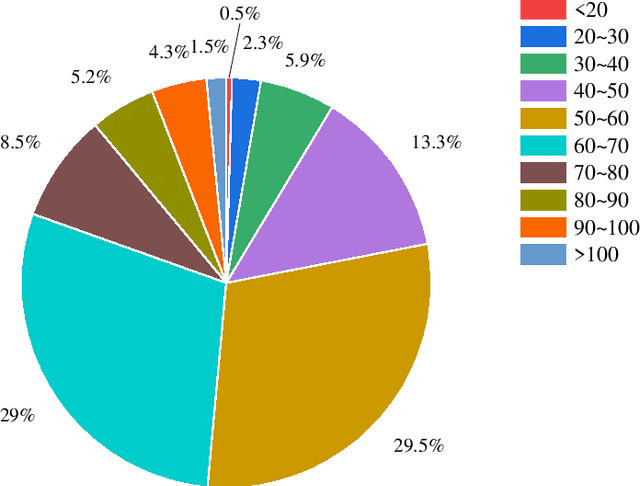

Psychological support hotlines are an effective suicide prevention measure that typically relies on professionals using suicide risk assessment scales to predict individual risk scores. However, the accuracy of scale-based predictive methods for suicide risk assessment can vary widely depending on the expertise of the operator. This limitation underscores the need for more reliable methods, prompting this research's innovative exploration of the use of artificial intelligence to improve the accuracy and efficiency of suicide risk prediction within the context of psychological support hotlines. The study included data from 1,549 subjects from 2015-2017 in China who contacted a psychological support hotline. Each participant was followed for 12 months to identify instances of suicidal behavior. We proposed a novel multi-task learning method that uses the large-scale pre-trained model Whisper for feature extraction and fits psychological scales while predicting the risk of suicide. The proposed method yields a 2.4\% points improvement in F1-score compared to the traditional manual approach based on the psychological scales. Our model demonstrated superior performance compared to the other eight popular models. To our knowledge, this study is the first to apply deep learning to long-term speech data to predict suicide risk in China, indicating grate potential for clinical applications. The source code is publicly available at: \url{https://github.com/songchangwei/Suicide-Risk-Prediction}.
A Generic Review of Integrating Artificial Intelligence in Cognitive Behavioral Therapy
Jul 28, 2024Cognitive Behavioral Therapy (CBT) is a well-established intervention for mitigating psychological issues by modifying maladaptive cognitive and behavioral patterns. However, delivery of CBT is often constrained by resource limitations and barriers to access. Advancements in artificial intelligence (AI) have provided technical support for the digital transformation of CBT. Particularly, the emergence of pre-training models (PTMs) and large language models (LLMs) holds immense potential to support, augment, optimize and automate CBT delivery. This paper reviews the literature on integrating AI into CBT interventions. We begin with an overview of CBT. Then, we introduce the integration of AI into CBT across various stages: pre-treatment, therapeutic process, and post-treatment. Next, we summarized the datasets relevant to some CBT-related tasks. Finally, we discuss the benefits and current limitations of applying AI to CBT. We suggest key areas for future research, highlighting the need for further exploration and validation of the long-term efficacy and clinical utility of AI-enhanced CBT. The transformative potential of AI in reshaping the practice of CBT heralds a new era of more accessible, efficient, and personalized mental health interventions.