 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMentalGLM Series: Explainable Large Language Models for Mental Health Analysis on Chinese Social Media
Oct 14, 2024
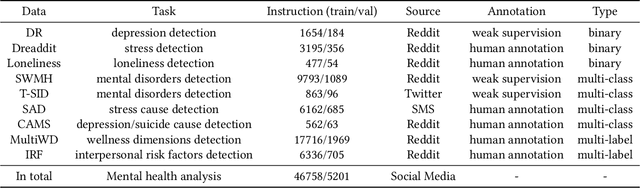
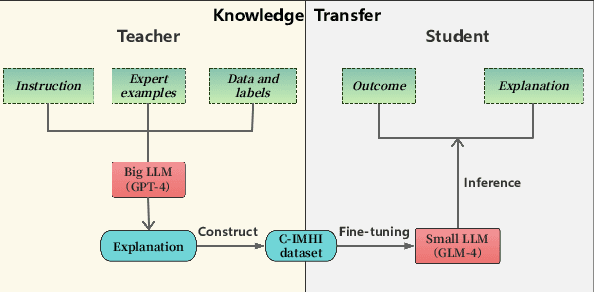

As the prevalence of mental health challenges, social media has emerged as a key platform for individuals to express their emotions.Deep learning tends to be a promising solution for analyzing mental health on social media. However, black box models are often inflexible when switching between tasks, and their results typically lack explanations. With the rise of large language models (LLMs), their flexibility has introduced new approaches to the field. Also due to the generative nature, they can be prompted to explain decision-making processes. However, their performance on complex psychological analysis still lags behind deep learning. In this paper, we introduce the first multi-task Chinese Social Media Interpretable Mental Health Instructions (C-IMHI) dataset, consisting of 9K samples, which has been quality-controlled and manually validated. We also propose MentalGLM series models, the first open-source LLMs designed for explainable mental health analysis targeting Chinese social media, trained on a corpus of 50K instructions. The proposed models were evaluated on three downstream tasks and achieved better or comparable performance compared to deep learning models, generalized LLMs, and task fine-tuned LLMs. We validated a portion of the generated decision explanations with experts, showing promising results. We also evaluated the proposed models on a clinical dataset, where they outperformed other LLMs, indicating their potential applicability in the clinical field. Our models show strong performance, validated across tasks and perspectives. The decision explanations enhance usability and facilitate better understanding and practical application of the models. Both the constructed dataset and the models are publicly available via: https://github.com/zwzzzQAQ/MentalGLM.
SOS-1K: A Fine-grained Suicide Risk Classification Dataset for Chinese Social Media Analysis
Apr 19, 2024In the social media, users frequently express personal emotions, a subset of which may indicate potential suicidal tendencies. The implicit and varied forms of expression in internet language complicate accurate and rapid identification of suicidal intent on social media, thus creating challenges for timely intervention efforts. The development of deep learning models for suicide risk detection is a promising solution, but there is a notable lack of relevant datasets, especially in the Chinese context. To address this gap, this study presents a Chinese social media dataset designed for fine-grained suicide risk classification, focusing on indicators such as expressions of suicide intent, methods of suicide, and urgency of timing. Seven pre-trained models were evaluated in two tasks: high and low suicide risk, and fine-grained suicide risk classification on a level of 0 to 10. In our experiments, deep learning models show good performance in distinguishing between high and low suicide risk, with the best model achieving an F1 score of 88.39%. However, the results for fine-grained suicide risk classification were still unsatisfactory, with an weighted F1 score of 50.89%. To address the issues of data imbalance and limited dataset size, we investigated both traditional and advanced, large language model based data augmentation techniques, demonstrating that data augmentation can enhance model performance by up to 4.65% points in F1-score. Notably, the Chinese MentalBERT model, which was pre-trained on psychological domain data, shows superior performance in both tasks. This study provides valuable insights for automatic identification of suicidal individuals, facilitating timely psychological intervention on social media platforms. The source code and data are publicly available.
AI-Enhanced Cognitive Behavioral Therapy: Deep Learning and Large Language Models for Extracting Cognitive Pathways from Social Media Texts
Apr 17, 2024



Cognitive Behavioral Therapy (CBT) is an effective technique for addressing the irrational thoughts stemming from mental illnesses, but it necessitates precise identification of cognitive pathways to be successfully implemented in patient care. In current society, individuals frequently express negative emotions on social media on specific topics, often exhibiting cognitive distortions, including suicidal behaviors in extreme cases. Yet, there is a notable absence of methodologies for analyzing cognitive pathways that could aid psychotherapists in conducting effective interventions online. In this study, we gathered data from social media and established the task of extracting cognitive pathways, annotating the data based on a cognitive theoretical framework. We initially categorized the task of extracting cognitive pathways as a hierarchical text classification with four main categories and nineteen subcategories. Following this, we structured a text summarization task to help psychotherapists quickly grasp the essential information. Our experiments evaluate the performance of deep learning and large language models (LLMs) on these tasks. The results demonstrate that our deep learning method achieved a micro-F1 score of 62.34% in the hierarchical text classification task. Meanwhile, in the text summarization task, GPT-4 attained a Rouge-1 score of 54.92 and a Rouge-2 score of 30.86, surpassing the experimental deep learning model's performance. However, it may suffer from an issue of hallucination. We have made all models and codes publicly available to support further research in this field.
Chinese MentalBERT: Domain-Adaptive Pre-training on Social Media for Chinese Mental Health Text Analysis
Feb 14, 2024In the current environment, psychological issues are prevalent and widespread, with social media serving as a key outlet for individuals to share their feelings. This results in the generation of vast quantities of data daily, where negative emotions have the potential to precipitate crisis situations. There is a recognized need for models capable of efficient analysis. While pre-trained language models have demonstrated their effectiveness broadly, there's a noticeable gap in pre-trained models tailored for specialized domains like psychology. To address this, we have collected a huge dataset from Chinese social media platforms and enriched it with publicly available datasets to create a comprehensive database encompassing 3.36 million text entries. To enhance the model's applicability to psychological text analysis, we integrated psychological lexicons into the pre-training masking mechanism. Building on an existing Chinese language model, we performed adaptive training to develop a model specialized for the psychological domain. We assessed our model's effectiveness across four public benchmarks, where it not only surpassed the performance of standard pre-trained models but also showed a inclination for making psychologically relevant predictions. Due to concerns regarding data privacy, the dataset will not be made publicly available. However, we have made the pre-trained models and codes publicly accessible to the community via: https://github.com/zwzzzQAQ/Chinese-MentalBERT.
Towards a Psychological Generalist AI: A Survey of Current Applications of Large Language Models and Future Prospects
Dec 01, 2023


The complexity of psychological principles underscore a significant societal challenge, given the vast social implications of psychological problems. Bridging the gap between understanding these principles and their actual clinical and real-world applications demands rigorous exploration and adept implementation. In recent times, the swift advancement of highly adaptive and reusable artificial intelligence (AI) models has emerged as a promising way to unlock unprecedented capabilities in the realm of psychology. This paper emphasizes the importance of performance validation for these large-scale AI models, emphasizing the need to offer a comprehensive assessment of their verification from diverse perspectives. Moreover, we review the cutting-edge advancements and practical implementations of these expansive models in psychology, highlighting pivotal work spanning areas such as social media analytics, clinical nursing insights, vigilant community monitoring, and the nuanced exploration of psychological theories. Based on our review, we project an acceleration in the progress of psychological fields, driven by these large-scale AI models. These future generalist AI models harbor the potential to substantially curtail labor costs and alleviate social stress. However, this forward momentum will not be without its set of challenges, especially when considering the paradigm changes and upgrades required for medical instrumentation and related applications.
Evaluating the Efficacy of Supervised Learning vs Large Language Models for Identifying Cognitive Distortions and Suicidal Risks in Chinese Social Media
Sep 07, 2023
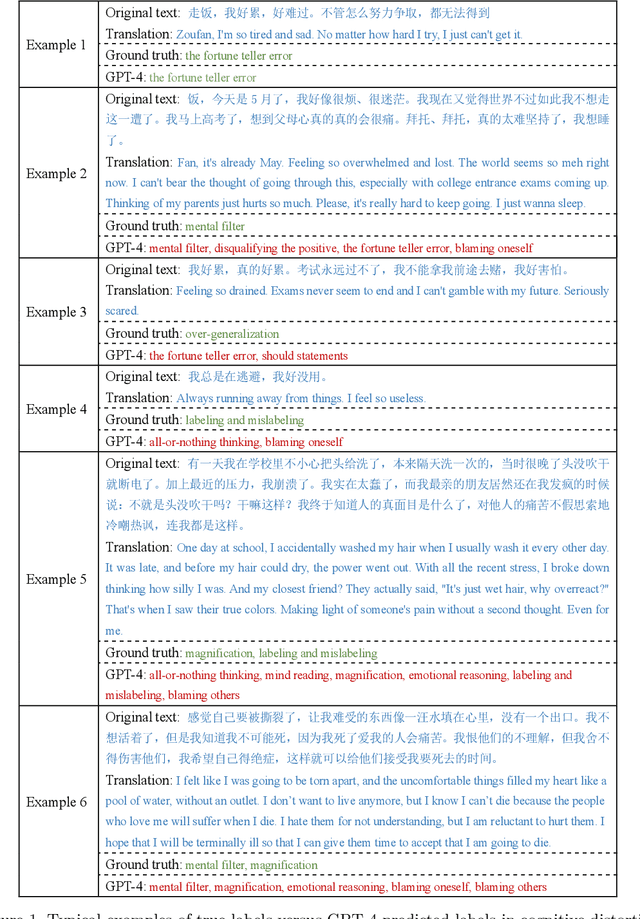

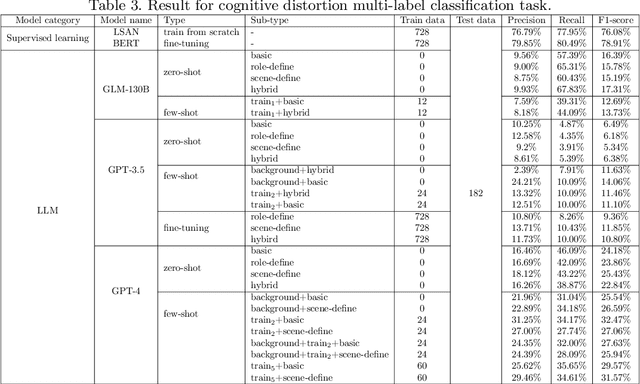
Large language models, particularly those akin to the rapidly progressing GPT series, are gaining traction for their expansive influence. While there is keen interest in their applicability within medical domains such as psychology, tangible explorations on real-world data remain scant. Concurrently, users on social media platforms are increasingly vocalizing personal sentiments; under specific thematic umbrellas, these sentiments often manifest as negative emotions, sometimes escalating to suicidal inclinations. Timely discernment of such cognitive distortions and suicidal risks is crucial to effectively intervene and potentially avert dire circumstances. Our study ventured into this realm by experimenting on two pivotal tasks: suicidal risk and cognitive distortion identification on Chinese social media platforms. Using supervised learning as a baseline, we examined and contrasted the efficacy of large language models via three distinct strategies: zero-shot, few-shot, and fine-tuning. Our findings revealed a discernible performance gap between the large language models and traditional supervised learning approaches, primarily attributed to the models' inability to fully grasp subtle categories. Notably, while GPT-4 outperforms its counterparts in multiple scenarios, GPT-3.5 shows significant enhancement in suicide risk classification after fine-tuning. To our knowledge, this investigation stands as the maiden attempt at gauging large language models on Chinese social media tasks. This study underscores the forward-looking and transformative implications of using large language models in the field of psychology. It lays the groundwork for future applications in psychological research and practice.