 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Coupled Reinforcement Learning for Multilingual Retrieval-Augmented Generation
Jan 21, 2026Multilingual retrieval-augmented generation (MRAG) requires models to effectively acquire and integrate beneficial external knowledge from multilingual collections. However, most existing studies employ a unitive process where queries of equivalent semantics across different languages are processed through a single-turn retrieval and subsequent optimization. Such a ``one-size-fits-all'' strategy is often suboptimal in multilingual settings, as the models occur to knowledge bias and conflict during the interaction with the search engine. To alleviate the issues, we propose LcRL, a multilingual search-augmented reinforcement learning framework that integrates a language-coupled Group Relative Policy Optimization into the policy and reward models. We adopt the language-coupled group sampling in the rollout module to reduce knowledge bias, and regularize an auxiliary anti-consistency penalty in the reward models to mitigate the knowledge conflict. Experimental results demonstrate that LcRL not only achieves competitive performance but is also appropriate for various practical scenarios such as constrained training data and retrieval over collections encompassing a large number of languages. Our code is available at https://github.com/Cherry-qwq/LcRL-Open.
Agentic Conversational Search with Contextualized Reasoning via Reinforcement Learning
Jan 19, 2026Large Language Models (LLMs) have become a popular interface for human-AI interaction, supporting information seeking and task assistance through natural, multi-turn dialogue. To respond to users within multi-turn dialogues, the context-dependent user intent evolves across interactions, requiring contextual interpretation, query reformulation, and dynamic coordination between retrieval and generation. Existing studies usually follow static rewrite, retrieve, and generate pipelines, which optimize different procedures separately and overlook the mixed-initiative action optimization simultaneously. Although the recent developments in deep search agents demonstrate the effectiveness in jointly optimizing retrieval and generation via reasoning, these approaches focus on single-turn scenarios, which might lack the ability to handle multi-turn interactions. We introduce a conversational agent that interleaves search and reasoning across turns, enabling exploratory and adaptive behaviors learned through reinforcement learning (RL) training with tailored rewards towards evolving user goals. The experimental results across four widely used conversational benchmarks demonstrate the effectiveness of our methods by surpassing several existing strong baselines.
MTMCS-Bench: Evaluating Contextual Safety of Multimodal Large Language Models in Multi-Turn Dialogues
Jan 11, 2026Multimodal large language models (MLLMs) are increasingly deployed as assistants that interact through text and images, making it crucial to evaluate contextual safety when risk depends on both the visual scene and the evolving dialogue. Existing contextual safety benchmarks are mostly single-turn and often miss how malicious intent can emerge gradually or how the same scene can support both benign and exploitative goals. We introduce the Multi-Turn Multimodal Contextual Safety Benchmark (MTMCS-Bench), a benchmark of realistic images and multi-turn conversations that evaluates contextual safety in MLLMs under two complementary settings, escalation-based risk and context-switch risk. MTMCS-Bench offers paired safe and unsafe dialogues with structured evaluation. It contains over 30 thousand multimodal (image+text) and unimodal (text-only) samples, with metrics that separately measure contextual intent recognition, safety-awareness on unsafe cases, and helpfulness on benign ones. Across eight open-source and seven proprietary MLLMs, we observe persistent trade-offs between contextual safety and utility, with models tending to either miss gradual risks or over-refuse benign dialogues. Finally, we evaluate five current guardrails and find that they mitigate some failures but do not fully resolve multi-turn contextual risks.
ClinicalReTrial: A Self-Evolving AI Agent for Clinical Trial Protocol Optimization
Jan 01, 2026Clinical trial failure remains a central bottleneck in drug development, where minor protocol design flaws can irreversibly compromise outcomes despite promising therapeutics. Although cutting-edge AI methods achieve strong performance in predicting trial success, they are inherently reactive for merely diagnosing risk without offering actionable remedies once failure is anticipated. To fill this gap, this paper proposes ClinicalReTrial, a self-evolving AI agent framework that addresses this gap by casting clinical trial reasoning as an iterative protocol redesign problem. Our method integrates failure diagnosis, safety-aware modification, and candidate evaluation in a closed-loop, reward-driven optimization framework. Serving the outcome prediction model as a simulation environment, ClinicalReTrial enables low-cost evaluation of protocol modifications and provides dense reward signals for continuous self-improvement. To support efficient exploration, the framework maintains hierarchical memory that captures iteration-level feedback within trials and distills transferable redesign patterns across trials. Empirically, ClinicalReTrial improves 83.3% of trial protocols with a mean success probability gain of 5.7%, and retrospective case studies demonstrate strong alignment between the discovered redesign strategies and real-world clinical trial modifications.
Open Polymer Challenge: Post-Competition Report
Dec 09, 2025Machine learning (ML) offers a powerful path toward discovering sustainable polymer materials, but progress has been limited by the lack of large, high-quality, and openly accessible polymer datasets. The Open Polymer Challenge (OPC) addresses this gap by releasing the first community-developed benchmark for polymer informatics, featuring a dataset with 10K polymers and 5 properties: thermal conductivity, radius of gyration, density, fractional free volume, and glass transition temperature. The challenge centers on multi-task polymer property prediction, a core step in virtual screening pipelines for materials discovery. Participants developed models under realistic constraints that include small data, label imbalance, and heterogeneous simulation sources, using techniques such as feature-based augmentation, transfer learning, self-supervised pretraining, and targeted ensemble strategies. The competition also revealed important lessons about data preparation, distribution shifts, and cross-group simulation consistency, informing best practices for future large-scale polymer datasets. The resulting models, analysis, and released data create a new foundation for molecular AI in polymer science and are expected to accelerate the development of sustainable and energy-efficient materials. Along with the competition, we release the test dataset at https://www.kaggle.com/datasets/alexliu99/neurips-open-polymer-prediction-2025-test-data. We also release the data generation pipeline at https://github.com/sobinalosious/ADEPT, which simulates more than 25 properties, including thermal conductivity, radius of gyration, and density.
A Decentralized Retrieval Augmented Generation System with Source Reliabilities Secured on Blockchain
Nov 10, 2025



Existing retrieval-augmented generation (RAG) systems typically use a centralized architecture, causing a high cost of data collection, integration, and management, as well as privacy concerns. There is a great need for a decentralized RAG system that enables foundation models to utilize information directly from data owners who maintain full control over their sources. However, decentralization brings a challenge: the numerous independent data sources vary significantly in reliability, which can diminish retrieval accuracy and response quality. To address this, our decentralized RAG system has a novel reliability scoring mechanism that dynamically evaluates each source based on the quality of responses it contributes to generate and prioritizes high-quality sources during retrieval. To ensure transparency and trust, the scoring process is securely managed through blockchain-based smart contracts, creating verifiable and tamper-proof reliability records without relying on a central authority. We evaluate our decentralized system with two Llama models (3B and 8B) in two simulated environments where six data sources have different levels of reliability. Our system achieves a +10.7\% performance improvement over its centralized counterpart in the real world-like unreliable data environments. Notably, it approaches the upper-bound performance of centralized systems under ideally reliable data environments. The decentralized infrastructure enables secure and trustworthy scoring management, achieving approximately 56\% marginal cost savings through batched update operations. Our code and system are open-sourced at github.com/yining610/Reliable-dRAG.
SPECTRA: Spectral Target-Aware Graph Augmentation for Imbalanced Molecular Property Regression
Nov 06, 2025In molecular property prediction, the most valuable compounds (e.g., high potency) often occupy sparse regions of the target space. Standard Graph Neural Networks (GNNs) commonly optimize for the average error, underperforming on these uncommon but critical cases, with existing oversampling methods often distorting molecular topology. In this paper, we introduce SPECTRA, a Spectral Target-Aware graph augmentation framework that generates realistic molecular graphs in the spectral domain. SPECTRA (i) reconstructs multi-attribute molecular graphs from SMILES; (ii) aligns molecule pairs via (Fused) Gromov-Wasserstein couplings to obtain node correspondences; (iii) interpolates Laplacian eigenvalues, eigenvectors and node features in a stable share-basis; and (iv) reconstructs edges to synthesize physically plausible intermediates with interpolated targets. A rarity-aware budgeting scheme, derived from a kernel density estimation of labels, concentrates augmentation where data are scarce. Coupled with a spectral GNN using edge-aware Chebyshev convolutions, SPECTRA densifies underrepresented regions without degrading global accuracy. On benchmarks, SPECTRA consistently improves error in relevant target ranges while maintaining competitive overall MAE, and yields interpretable synthetic molecules whose structure reflects the underlying spectral geometry. Our results demonstrate that spectral, geometry-aware augmentation is an effective and efficient strategy for imbalanced molecular property regression.
Multi-module GRPO: Composing Policy Gradients and Prompt Optimization for Language Model Programs
Aug 06, 2025Group Relative Policy Optimization (GRPO) has proven to be an effective tool for post-training language models (LMs). However, AI systems are increasingly expressed as modular programs that mix together multiple LM calls with distinct prompt templates and other tools, and it is not clear how best to leverage GRPO to improve these systems. We begin to address this challenge by defining mmGRPO, a simple multi-module generalization of GRPO that groups LM calls by module across rollouts and handles variable-length and interrupted trajectories. We find that mmGRPO, composed with automatic prompt optimization, improves accuracy by 11% on average across classification, many-hop search, and privacy-preserving delegation tasks against the post-trained LM, and by 5% against prompt optimization on its own. We open-source mmGRPO in DSPy as the dspy.GRPO optimizer.
Pre-trained Models Perform the Best When Token Distributions Follow Zipf's Law
Jul 30, 2025Tokenization is a fundamental step in natural language processing (NLP) and other sequence modeling domains, where the choice of vocabulary size significantly impacts model performance. Despite its importance, selecting an optimal vocabulary size remains underexplored, typically relying on heuristics or dataset-specific choices. In this work, we propose a principled method for determining the vocabulary size by analyzing token frequency distributions through Zipf's law. We show that downstream task performance correlates with how closely token distributions follow power-law behavior, and that aligning with Zipfian scaling improves both model efficiency and effectiveness. Extensive experiments across NLP, genomics, and chemistry demonstrate that models consistently achieve peak performance when the token distribution closely adheres to Zipf's law, establishing Zipfian alignment as a robust and generalizable criterion for vocabulary size selection.
UniConv: Unifying Retrieval and Response Generation for Large Language Models in Conversations
Jul 09, 2025
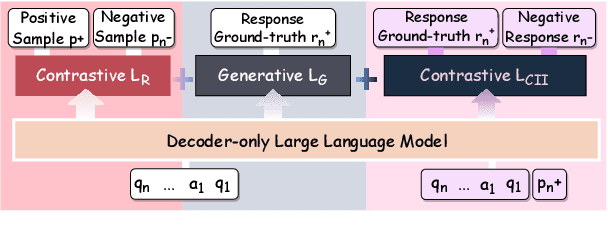
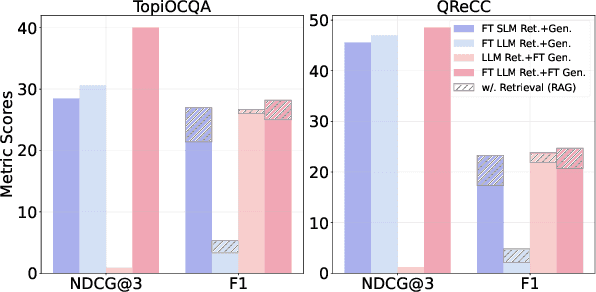
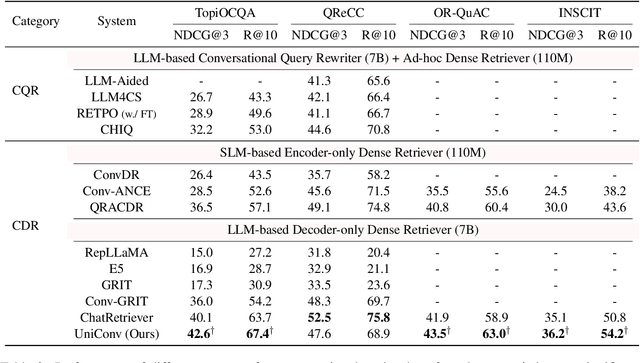
The rapid advancement of conversational search systems revolutionizes how information is accessed by enabling the multi-turn interaction between the user and the system. Existing conversational search systems are usually built with two different models. This separation restricts the system from leveraging the intrinsic knowledge of the models simultaneously, which cannot ensure the effectiveness of retrieval benefiting the generation. The existing studies for developing unified models cannot fully address the aspects of understanding conversational context, managing retrieval independently, and generating responses. In this paper, we explore how to unify dense retrieval and response generation for large language models in conversation. We conduct joint fine-tuning with different objectives and design two mechanisms to reduce the inconsistency risks while mitigating data discrepancy. The evaluations on five conversational search datasets demonstrate that our unified model can mutually improve both tasks and outperform the existing baselines.