 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPA: Achieving Consensus in LLM Alignment via Self-Priority Optimization
Nov 09, 2025In high-stakes scenarios-such as self-harm, legal, or medical queries-LLMs must be both trustworthy and helpful. However, these goals often conflict. We propose priority alignment, a new alignment paradigm that enforces a strict "trustworthy-before-helpful" ordering: optimization of helpfulness is conditioned on first meeting trustworthy thresholds (e.g., harmlessness or honesty). To realize this, we introduce Self-Priority Alignment (SPA)-a fully unsupervised framework that generates diverse responses, self-evaluates them and refines them by the model itself, and applies dual-criterion denoising to remove inconsistency and control variance. From this, SPA constructs lexicographically ordered preference pairs and fine-tunes the model using an uncertainty-weighted alignment loss that emphasizes high-confidence, high-gap decisions. Experiments across multiple benchmarks show that SPA improves helpfulness without compromising safety, outperforming strong baselines while preserving general capabilities. Our results demonstrate that SPA provides a scalable and interpretable alignment strategy for critical LLM applications.
Dissecting Logical Reasoning in LLMs: A Fine-Grained Evaluation and Supervision Study
Jun 05, 2025Logical reasoning is a core capability for many applications of large language models (LLMs), yet existing benchmarks often rely solely on final-answer accuracy, failing to capture the quality and structure of the reasoning process. We propose FineLogic, a fine-grained evaluation framework that assesses logical reasoning across three dimensions: overall benchmark accuracy, stepwise soundness, and representation-level alignment. In addition, to better understand how reasoning capabilities emerge, we conduct a comprehensive study on the effects of supervision format during fine-tuning. We construct four supervision styles (one natural language and three symbolic variants) and train LLMs under each. Our findings reveal that natural language supervision yields strong generalization even on out-of-distribution and long-context tasks, while symbolic reasoning styles promote more structurally sound and atomic inference chains. Further, our representation-level probing shows that fine-tuning primarily improves reasoning behaviors through step-by-step generation, rather than enhancing shortcut prediction or internalized correctness. Together, our framework and analysis provide a more rigorous and interpretable lens for evaluating and improving logical reasoning in LLMs.
AdaReasoner: Adaptive Reasoning Enables More Flexible Thinking
May 22, 2025LLMs often need effective configurations, like temperature and reasoning steps, to handle tasks requiring sophisticated reasoning and problem-solving, ranging from joke generation to mathematical reasoning. Existing prompting approaches usually adopt general-purpose, fixed configurations that work 'well enough' across tasks but seldom achieve task-specific optimality. To address this gap, we introduce AdaReasoner, an LLM-agnostic plugin designed for any LLM to automate adaptive reasoning configurations for tasks requiring different types of thinking. AdaReasoner is trained using a reinforcement learning (RL) framework, combining a factorized action space with a targeted exploration strategy, along with a pretrained reward model to optimize the policy model for reasoning configurations with only a few-shot guide. AdaReasoner is backed by theoretical guarantees and experiments of fast convergence and a sublinear policy gap. Across six different LLMs and a variety of reasoning tasks, it consistently outperforms standard baselines, preserves out-of-distribution robustness, and yield gains on knowledge-intensive tasks through tailored prompts.
Social Science Meets LLMs: How Reliable Are Large Language Models in Social Simulations?
Oct 30, 2024


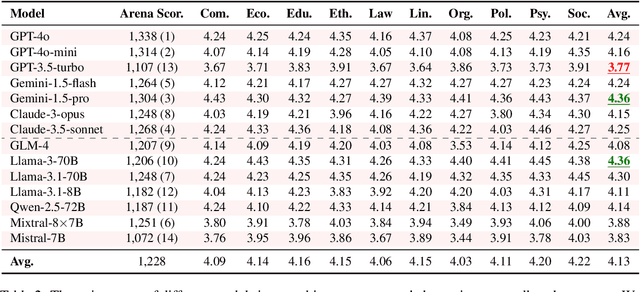
Large Language Models (LLMs) are increasingly employed for simulations, enabling applications in role-playing agents and Computational Social Science (CSS). However, the reliability of these simulations is under-explored, which raises concerns about the trustworthiness of LLMs in these applications. In this paper, we aim to answer ``How reliable is LLM-based simulation?'' To address this, we introduce TrustSim, an evaluation dataset covering 10 CSS-related topics, to systematically investigate the reliability of the LLM simulation. We conducted experiments on 14 LLMs and found that inconsistencies persist in the LLM-based simulated roles. In addition, the consistency level of LLMs does not strongly correlate with their general performance. To enhance the reliability of LLMs in simulation, we proposed Adaptive Learning Rate Based ORPO (AdaORPO), a reinforcement learning-based algorithm to improve the reliability in simulation across 7 LLMs. Our research provides a foundation for future studies to explore more robust and trustworthy LLM-based simulations.
CLIPErase: Efficient Unlearning of Visual-Textual Associations in CLIP
Oct 30, 2024



Machine unlearning (MU) has gained significant attention as a means to remove specific data from trained models without requiring a full retraining process. While progress has been made in unimodal domains like text and image classification, unlearning in multimodal models remains relatively underexplored. In this work, we address the unique challenges of unlearning in CLIP, a prominent multimodal model that aligns visual and textual representations. We introduce CLIPErase, a novel approach that disentangles and selectively forgets both visual and textual associations, ensuring that unlearning does not compromise model performance. CLIPErase consists of three key modules: a Forgetting Module that disrupts the associations in the forget set, a Retention Module that preserves performance on the retain set, and a Consistency Module that maintains consistency with the original model. Extensive experiments on the CIFAR-100 and Flickr30K datasets across four CLIP downstream tasks demonstrate that CLIPErase effectively forgets designated associations in zero-shot tasks for multimodal samples, while preserving the model's performance on the retain set after unlearning.
AutoBench-V: Can Large Vision-Language Models Benchmark Themselves?
Oct 29, 2024Large Vision-Language Models (LVLMs) have become essential for advancing the integration of visual and linguistic information, facilitating a wide range of complex applications and tasks. However, the evaluation of LVLMs presents significant challenges as the evaluation benchmark always demands lots of human cost for its construction, and remains static, lacking flexibility once constructed. Even though automatic evaluation has been explored in textual modality, the visual modality remains under-explored. As a result, in this work, we address a question: "Can LVLMs serve as a path to automatic benchmarking?". We introduce AutoBench-V, an automated framework for serving evaluation on demand, i.e., benchmarking LVLMs based on specific aspects of model capability. Upon receiving an evaluation capability, AutoBench-V leverages text-to-image models to generate relevant image samples and then utilizes LVLMs to orchestrate visual question-answering (VQA) tasks, completing the evaluation process efficiently and flexibly. Through an extensive evaluation of seven popular LVLMs across five demanded user inputs (i.e., evaluation capabilities), the framework shows effectiveness and reliability. We observe the following: (1) Our constructed benchmark accurately reflects varying task difficulties; (2) As task difficulty rises, the performance gap between models widens; (3) While models exhibit strong performance in abstract level understanding, they underperform in details reasoning tasks; and (4) Constructing a dataset with varying levels of difficulties is critical for a comprehensive and exhaustive evaluation. Overall, AutoBench-V not only successfully utilizes LVLMs for automated benchmarking but also reveals that LVLMs as judges have significant potential in various domains.
NS4AR: A new, focused on sampling areas sampling method in graphical recommendation Systems
Jul 13, 2023



The effectiveness of graphical recommender system depends on the quantity and quality of negative sampling. This paper selects some typical recommender system models, as well as some latest negative sampling strategies on the models as baseline. Based on typical graphical recommender model, we divide sample region into assigned-n areas and use AdaSim to give different weight to these areas to form positive set and negative set. Because of the volume and significance of negative items, we also proposed a subset selection model to narrow the core negative samples.