 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSave the Good Prefix: Precise Error Penalization via Process-Supervised RL to Enhance LLM Reasoning
Jan 26, 2026Reinforcement learning (RL) has emerged as a powerful framework for improving the reasoning capabilities of large language models (LLMs). However, most existing RL approaches rely on sparse outcome rewards, which fail to credit correct intermediate steps in partially successful solutions. Process reward models (PRMs) offer fine-grained step-level supervision, but their scores are often noisy and difficult to evaluate. As a result, recent PRM benchmarks focus on a more objective capability: detecting the first incorrect step in a reasoning path. However, this evaluation target is misaligned with how PRMs are typically used in RL, where their step-wise scores are treated as raw rewards to maximize. To bridge this gap, we propose Verifiable Prefix Policy Optimization (VPPO), which uses PRMs only to localize the first error during RL. Given an incorrect rollout, VPPO partitions the trajectory into a verified correct prefix and an erroneous suffix based on the first error, rewarding the former while applying targeted penalties only after the detected mistake. This design yields stable, interpretable learning signals and improves credit assignment. Across multiple reasoning benchmarks, VPPO consistently outperforms sparse-reward RL and prior PRM-guided baselines on both Pass@1 and Pass@K.
Stable and Efficient Single-Rollout RL for Multimodal Reasoning
Dec 20, 2025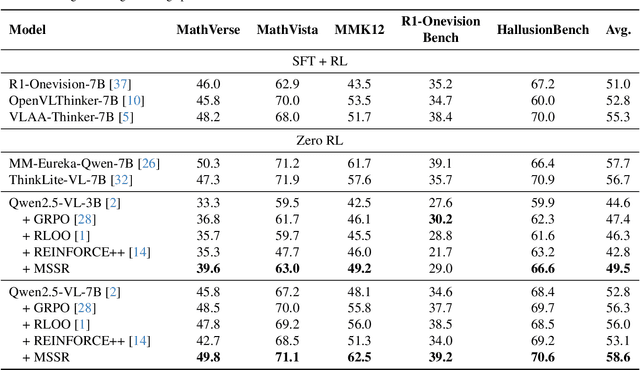
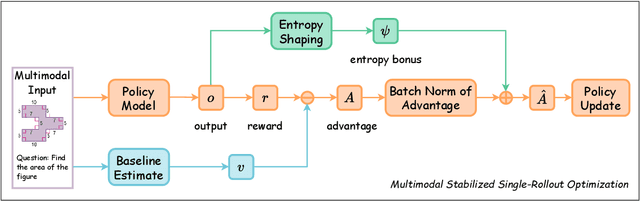

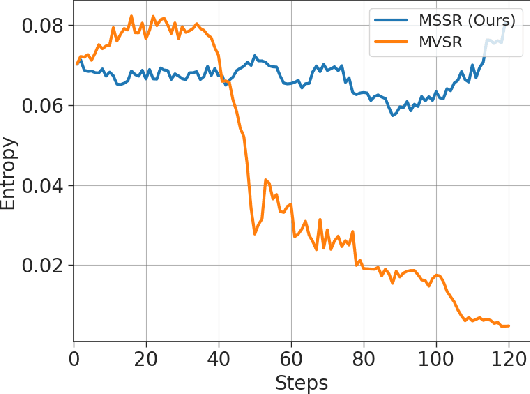
Reinforcement Learning with Verifiable Rewards (RLVR) has become a key paradigm to improve the reasoning capabilities of Multimodal Large Language Models (MLLMs). However, prevalent group-based algorithms such as GRPO require multi-rollout sampling for each prompt. While more efficient single-rollout variants have recently been explored in text-only settings, we find that they suffer from severe instability in multimodal contexts, often leading to training collapse. To address this training efficiency-stability trade-off, we introduce $\textbf{MSSR}$ (Multimodal Stabilized Single-Rollout), a group-free RLVR framework that achieves both stable optimization and effective multimodal reasoning performance. MSSR achieves this via an entropy-based advantage-shaping mechanism that adaptively regularizes advantage magnitudes, preventing collapse and maintaining training stability. While such mechanisms have been used in group-based RLVR, we show that in the multimodal single-rollout setting they are not merely beneficial but essential for stability. In in-distribution evaluations, MSSR demonstrates superior training compute efficiency, achieving similar validation accuracy to the group-based baseline with half the training steps. When trained for the same number of steps, MSSR's performance surpasses the group-based baseline and shows consistent generalization improvements across five diverse reasoning-intensive benchmarks. Together, these results demonstrate that MSSR enables stable, compute-efficient, and effective RLVR for complex multimodal reasoning tasks.
Can LLMs Guide Their Own Exploration? Gradient-Guided Reinforcement Learning for LLM Reasoning
Dec 17, 2025
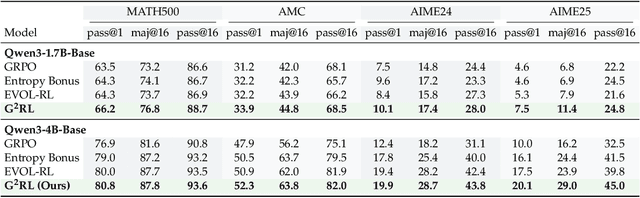
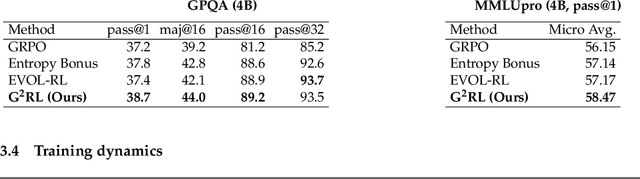
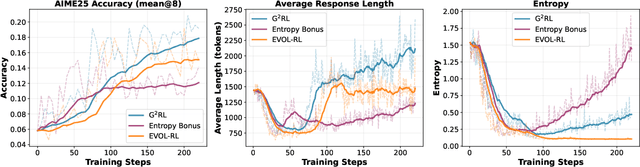
Reinforcement learning has become essential for strengthening the reasoning abilities of large language models, yet current exploration mechanisms remain fundamentally misaligned with how these models actually learn. Entropy bonuses and external semantic comparators encourage surface level variation but offer no guarantee that sampled trajectories differ in the update directions that shape optimization. We propose G2RL, a gradient guided reinforcement learning framework in which exploration is driven not by external heuristics but by the model own first order update geometry. For each response, G2RL constructs a sequence level feature from the model final layer sensitivity, obtainable at negligible cost from a standard forward pass, and measures how each trajectory would reshape the policy by comparing these features within a sampled group. Trajectories that introduce novel gradient directions receive a bounded multiplicative reward scaler, while redundant or off manifold updates are deemphasized, yielding a self referential exploration signal that is naturally aligned with PPO style stability and KL control. Across math and general reasoning benchmarks (MATH500, AMC, AIME24, AIME25, GPQA, MMLUpro) on Qwen3 base 1.7B and 4B models, G2RL consistently improves pass@1, maj@16, and pass@k over entropy based GRPO and external embedding methods. Analyzing the induced geometry, we find that G2RL expands exploration into substantially more orthogonal and often opposing gradient directions while maintaining semantic coherence, revealing that a policy own update space provides a far more faithful and effective basis for guiding exploration in large language model reinforcement learning.
CLUE: Non-parametric Verification from Experience via Hidden-State Clustering
Oct 02, 2025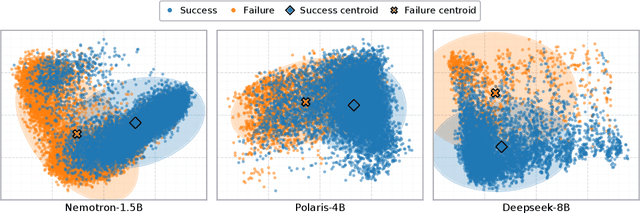
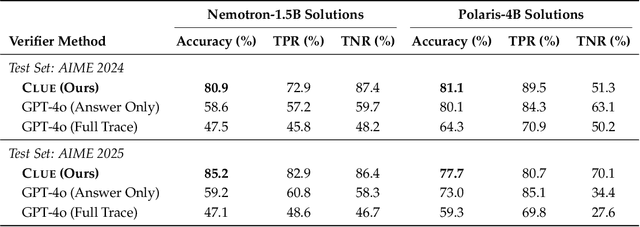
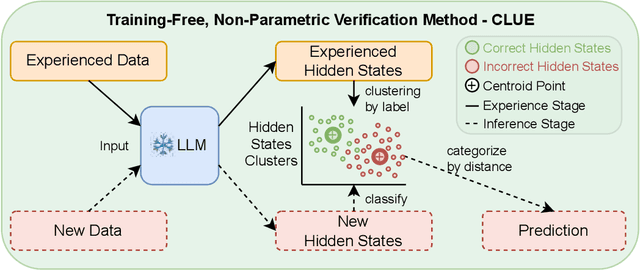
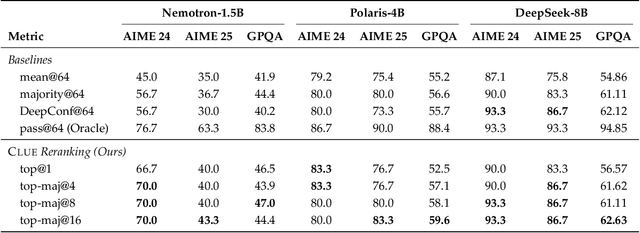
Assessing the quality of Large Language Model (LLM) outputs presents a critical challenge. Previous methods either rely on text-level information (e.g., reward models, majority voting), which can overfit to superficial cues, or on calibrated confidence from token probabilities, which would fail on less-calibrated models. Yet both of these signals are, in fact, partial projections of a richer source of information: the model's internal hidden states. Early layers, closer to token embeddings, preserve semantic and lexical features that underpin text-based judgments, while later layers increasingly align with output logits, embedding confidence-related information. This paper explores hidden states directly as a unified foundation for verification. We show that the correctness of a solution is encoded as a geometrically separable signature within the trajectory of hidden activations. To validate this, we present Clue (Clustering and Experience-based Verification), a deliberately minimalist, non-parametric verifier. With no trainable parameters, CLUE only summarizes each reasoning trace by an hidden state delta and classifies correctness via nearest-centroid distance to ``success'' and ``failure'' clusters formed from past experience. The simplicity of this method highlights the strength of the underlying signal. Empirically, CLUE consistently outperforms LLM-as-a-judge baselines and matches or exceeds modern confidence-based methods in reranking candidates, improving both top-1 and majority-vote accuracy across AIME 24/25 and GPQA. As a highlight, on AIME 24 with a 1.5B model, CLUE boosts accuracy from 56.7% (majority@64) to 70.0% (top-maj@16).
Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation
Sep 18, 2025Large language models (LLMs) are increasingly trained with reinforcement learning from verifiable rewards (RLVR), yet real-world deployment demands models that can self-improve without labels or external judges. Existing label-free methods, confidence minimization, self-consistency, or majority-vote objectives, stabilize learning but steadily shrink exploration, causing an entropy collapse: generations become shorter, less diverse, and brittle. Unlike prior approaches such as Test-Time Reinforcement Learning (TTRL), which primarily adapt models to the immediate unlabeled dataset at hand, our goal is broader: to enable general improvements without sacrificing the model's inherent exploration capacity and generalization ability, i.e., evolving. We formalize this issue and propose EVolution-Oriented and Label-free Reinforcement Learning (EVOL-RL), a simple rule that couples stability with variation under a label-free setting. EVOL-RL keeps the majority-voted answer as a stable anchor (selection) while adding a novelty-aware reward that favors responses whose reasoning differs from what has already been produced (variation), measured in semantic space. Implemented with GRPO, EVOL-RL also uses asymmetric clipping to preserve strong signals and an entropy regularizer to sustain search. This majority-for-selection + novelty-for-variation design prevents collapse, maintains longer and more informative chains of thought, and improves both pass@1 and pass@n. EVOL-RL consistently outperforms the majority-only TTRL baseline; e.g., training on label-free AIME24 lifts Qwen3-4B-Base AIME25 pass@1 from TTRL's 4.6% to 16.4%, and pass@16 from 18.5% to 37.9%. EVOL-RL not only prevents diversity collapse but also unlocks stronger generalization across domains (e.g., GPQA). Furthermore, we demonstrate that EVOL-RL also boosts performance in the RLVR setting, highlighting its broad applicability.
Dissecting Logical Reasoning in LLMs: A Fine-Grained Evaluation and Supervision Study
Jun 05, 2025Logical reasoning is a core capability for many applications of large language models (LLMs), yet existing benchmarks often rely solely on final-answer accuracy, failing to capture the quality and structure of the reasoning process. We propose FineLogic, a fine-grained evaluation framework that assesses logical reasoning across three dimensions: overall benchmark accuracy, stepwise soundness, and representation-level alignment. In addition, to better understand how reasoning capabilities emerge, we conduct a comprehensive study on the effects of supervision format during fine-tuning. We construct four supervision styles (one natural language and three symbolic variants) and train LLMs under each. Our findings reveal that natural language supervision yields strong generalization even on out-of-distribution and long-context tasks, while symbolic reasoning styles promote more structurally sound and atomic inference chains. Further, our representation-level probing shows that fine-tuning primarily improves reasoning behaviors through step-by-step generation, rather than enhancing shortcut prediction or internalized correctness. Together, our framework and analysis provide a more rigorous and interpretable lens for evaluating and improving logical reasoning in LLMs.
SocialMaze: A Benchmark for Evaluating Social Reasoning in Large Language Models
May 29, 2025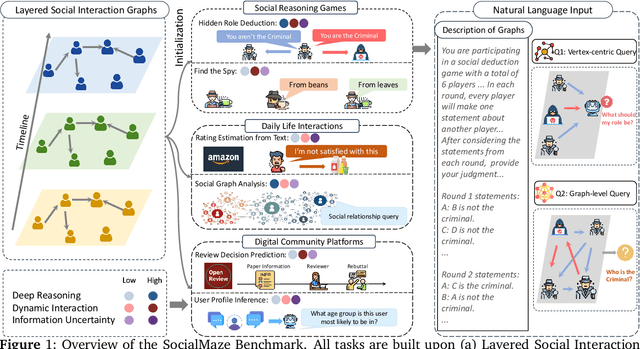
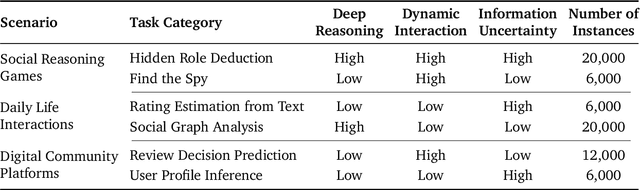
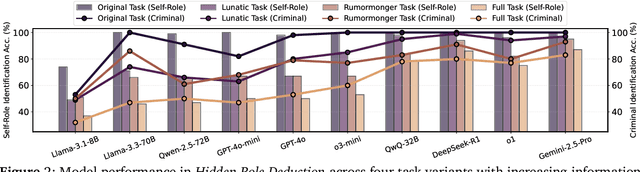
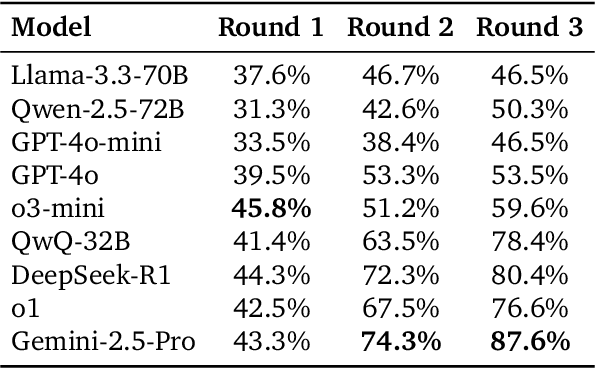
Large language models (LLMs) are increasingly applied to socially grounded tasks, such as online community moderation, media content analysis, and social reasoning games. Success in these contexts depends on a model's social reasoning ability - the capacity to interpret social contexts, infer others' mental states, and assess the truthfulness of presented information. However, there is currently no systematic evaluation framework that comprehensively assesses the social reasoning capabilities of LLMs. Existing efforts often oversimplify real-world scenarios and consist of tasks that are too basic to challenge advanced models. To address this gap, we introduce SocialMaze, a new benchmark specifically designed to evaluate social reasoning. SocialMaze systematically incorporates three core challenges: deep reasoning, dynamic interaction, and information uncertainty. It provides six diverse tasks across three key settings: social reasoning games, daily-life interactions, and digital community platforms. Both automated and human validation are used to ensure data quality. Our evaluation reveals several key insights: models vary substantially in their ability to handle dynamic interactions and integrate temporally evolving information; models with strong chain-of-thought reasoning perform better on tasks requiring deeper inference beyond surface-level cues; and model reasoning degrades significantly under uncertainty. Furthermore, we show that targeted fine-tuning on curated reasoning examples can greatly improve model performance in complex social scenarios. The dataset is publicly available at: https://huggingface.co/datasets/MBZUAI/SocialMaze
AdaReasoner: Adaptive Reasoning Enables More Flexible Thinking
May 22, 2025LLMs often need effective configurations, like temperature and reasoning steps, to handle tasks requiring sophisticated reasoning and problem-solving, ranging from joke generation to mathematical reasoning. Existing prompting approaches usually adopt general-purpose, fixed configurations that work 'well enough' across tasks but seldom achieve task-specific optimality. To address this gap, we introduce AdaReasoner, an LLM-agnostic plugin designed for any LLM to automate adaptive reasoning configurations for tasks requiring different types of thinking. AdaReasoner is trained using a reinforcement learning (RL) framework, combining a factorized action space with a targeted exploration strategy, along with a pretrained reward model to optimize the policy model for reasoning configurations with only a few-shot guide. AdaReasoner is backed by theoretical guarantees and experiments of fast convergence and a sublinear policy gap. Across six different LLMs and a variety of reasoning tasks, it consistently outperforms standard baselines, preserves out-of-distribution robustness, and yield gains on knowledge-intensive tasks through tailored prompts.
Beyond Single-Value Metrics: Evaluating and Enhancing LLM Unlearning with Cognitive Diagnosis
Feb 19, 2025Due to the widespread use of LLMs and the rising critical ethical and safety concerns, LLM unlearning methods have been developed to remove harmful knowledge and undesirable capabilities. In this context, evaluations are mostly based on single-value metrics such as QA accuracy. However, these metrics often fail to capture the nuanced retention of harmful knowledge components, making it difficult to assess the true effectiveness of unlearning. To address this issue, we propose UNCD (UNlearning evaluation via Cognitive Diagnosis), a novel framework that leverages Cognitive Diagnosis Modeling for fine-grained evaluation of LLM unlearning. Our dedicated benchmark, UNCD-Cyber, provides a detailed assessment of the removal of dangerous capabilities. Moreover, we introduce UNCD-Agent, which refines unlearning by diagnosing knowledge remnants and generating targeted unlearning data. Extensive experiments across eight unlearning methods and two base models demonstrate that UNCD not only enhances evaluation but also effectively facilitates the removal of harmful LLM abilities.
Social Science Meets LLMs: How Reliable Are Large Language Models in Social Simulations?
Oct 30, 2024


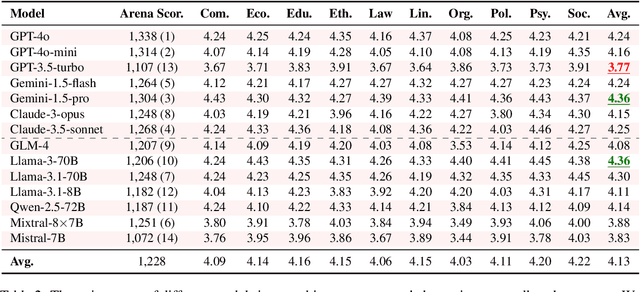
Large Language Models (LLMs) are increasingly employed for simulations, enabling applications in role-playing agents and Computational Social Science (CSS). However, the reliability of these simulations is under-explored, which raises concerns about the trustworthiness of LLMs in these applications. In this paper, we aim to answer ``How reliable is LLM-based simulation?'' To address this, we introduce TrustSim, an evaluation dataset covering 10 CSS-related topics, to systematically investigate the reliability of the LLM simulation. We conducted experiments on 14 LLMs and found that inconsistencies persist in the LLM-based simulated roles. In addition, the consistency level of LLMs does not strongly correlate with their general performance. To enhance the reliability of LLMs in simulation, we proposed Adaptive Learning Rate Based ORPO (AdaORPO), a reinforcement learning-based algorithm to improve the reliability in simulation across 7 LLMs. Our research provides a foundation for future studies to explore more robust and trustworthy LLM-based simulations.