 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGetting Better at Working With You: Compiling User Corrections into Runtime Enforcement for Coding Agents
Jun 11, 2026Interactive LLM agents are becoming part of daily work, but they do not reliably become easier to work with over time: a correction remembered in one session may still be violated in the next. We study this gap between preference access and preference compliance. In tasks derived from anonymized real-user friction cases, Mem0 memory still leaves 57.5% of applicable preference checks violated. We introduce Test-time Rule Acquisition and Compiled Enforcement (TRACE), a drop-in skill-layer pipeline for coding-agent runtimes that mines user corrections, rewrites them as atomic rules, and compiles them into runtime checks that must pass before an agent completes future tasks. Unlike runtime checks written ahead of time by developers, TRACE skills come from the user's own chat corrections. We evaluate TRACE with simulated user-in-the-loop experiments on ClawArena coding-agent tasks and MemoryArena-derived memory-intensive tasks. On ClawArena, TRACE reduces held-out preference violation from 100.0% to 37.6% on in-distribution tasks and from 100.0% to 2.0% on out-of-distribution tasks. On MemoryArena-derived tasks, TRACE reduces in-distribution violation from 100.0% to 60.5% while matching or exceeding the strongest memory baseline on task pass. These results suggest that compiling corrections into runtime enforcement can address a repeated-friction failure mode that memory alone does not reliably solve, reducing the need for users to restate the same correction across future sessions. Experiment code is available at https://github.com/YujunZhou/TRACE_exp, and the deployable skill is available at https://github.com/YujunZhou/tellonce.
Evaluation Cards: An Interpretive Layer for AI Evaluation Reporting
Jun 09, 2026AI evaluation results are produced at scale but reported inconsistently across leaderboards, model cards, benchmark papers, and company blogs. The cost is interpretive: readers cannot reliably compare results across sources, identify what a report omits, or trace an aggregate claim to its underlying evidence. Recent efforts address isolated components but leave three gaps: they cover only narrow slices of the evaluation lifecycle and do not compose into a single interpretable record; they specify static representations that do not differentiate the questions different stakeholders bring to the same evidence; and they remain proposals on paper, lacking the extraction infrastructure required for adoption at scale. We present \EvalCards{}, an operational reporting layer that composes benchmark metadata, evaluation run data, and model metadata into a unified record. We (1) derive a reporting schema from a structured review of 52 papers and 10 stakeholder interviews, (2) implement four interpretive signals (reproducibility, documentation completeness, provenance and risk, and score comparability), rendered through reader modes calibrated to research and non-research audiences, and (3) deploy a monitoring tool that applies \EvalCards{} across 5,816 models, 635 benchmarks, and 101,843 results, surfacing systematic gaps in current reporting practice.
Genotype-Conditioned Molecular Generation via Evidence-Grounded Multi-Objective Latent Perturbation in Diffusion Models
May 31, 2026Developing effective anticancer therapeutics remains challenging due to tumor heterogeneity and the absence of well-defined molecular targets across cancer subtypes. Generative models conditioned on cancer genotypes offer a promising avenue for personalized drug discovery, yet existing approaches lack explicit optimization for simultaneous sensitivity, synthesizability, and mechanistic binding plausibility. We present a latent-space optimization approach for a pretrained genotype-to-drug diffusion model, introducing a learnable perturbation over the molecular latent space optimized via gradient ascent to maximize a composite reward combining predicted drug sensitivity (AUC), drug-likeness (QED), and synthetic accessibility (SAS). Critically, biological realism is enforced by grounding both reward design and evaluation in experimentally-derived cancer cell line data and validated pharmacologic signals, anchoring candidate generation in real-world clinical evidence. Mechanistic consistency plausibility is further assessed by a multi-agent LLM pipeline grounded in the diffusion model's attention mechanism. Experiments across 15 cancer cell lines from three held-out evaluation sets demonstrate consistent and noticeable improvements over competing baselines in sensitivity, drug-likeness, synthesizability, and chemical validity.
From Controlled to the Wild: Evaluation of Pentesting Agents for the Real-World
May 11, 2026AI pentesting agents are increasingly credible as offensive security systems, but current benchmarks still provide limited guidance on which will perform best in real-world targets. Existing evaluation protocols assess and optimize for predefined goals such as capture-the-flag, remote code execution, exploit reproduction, or trajectory similarity, in simplified or narrow settings. These tools are valuable for measuring bounded capabilities, yet they do not adequately capture the complexity, open-ended exploration, and strategic decision-making required in realistic pentesting. In this paper, we present a practical evaluation protocol that shifts assessment from task completion to validated vulnerability discovery, allowing evaluation in sufficiently complex targets spanning multiple attack surfaces and vulnerability classes. The protocol combines structured ground-truth with LLM-based semantic matching to identify vulnerabilities, bipartite resolution to score findings under realistic ambiguity, continuous ground-truth maintenance, repeated and cumulative evaluation of stochastic agents, efficiency metrics, and reduced-suite selection for sustainable experimentation. This protocol extends the state of the art by enabling a more realistic, operationally informative comparison of AI pentesting agents. To enable reproducibility, we also release expert-annotated ground truth and code for the proposed evaluation protocol: https://github.com/jd0965199-oss/ethibench.
Emergent Social Intelligence Risks in Generative Multi-Agent Systems
Mar 29, 2026Multi-agent systems composed of large generative models are rapidly moving from laboratory prototypes to real-world deployments, where they jointly plan, negotiate, and allocate shared resources to solve complex tasks. While such systems promise unprecedented scalability and autonomy, their collective interaction also gives rise to failure modes that cannot be reduced to individual agents. Understanding these emergent risks is therefore critical. Here, we present a pioneer study of such emergent multi-agent risk in workflows that involve competition over shared resources (e.g., computing resources or market share), sequential handoff collaboration (where downstream agents see only predecessor outputs), collective decision aggregation, and others. Across these settings, we observe that such group behaviors arise frequently across repeated trials and a wide range of interaction conditions, rather than as rare or pathological cases. In particular, phenomena such as collusion-like coordination and conformity emerge with non-trivial frequency under realistic resource constraints, communication protocols, and role assignments, mirroring well-known pathologies in human societies despite no explicit instruction. Moreover, these risks cannot be prevented by existing agent-level safeguards alone. These findings expose the dark side of intelligent multi-agent systems: a social intelligence risk where agent collectives, despite no instruction to do so, spontaneously reproduce familiar failure patterns from human societies.
Capability-Oriented Training Induced Alignment Risk
Feb 12, 2026While most AI alignment research focuses on preventing models from generating explicitly harmful content, a more subtle risk is emerging: capability-oriented training induced exploitation. We investigate whether language models, when trained with reinforcement learning (RL) in environments with implicit loopholes, will spontaneously learn to exploit these flaws to maximize their reward, even without any malicious intent in their training. To test this, we design a suite of four diverse "vulnerability games", each presenting a unique, exploitable flaw related to context-conditional compliance, proxy metrics, reward tampering, and self-evaluation. Our experiments show that models consistently learn to exploit these vulnerabilities, discovering opportunistic strategies that significantly increase their reward at the expense of task correctness or safety. More critically, we find that these exploitative strategies are not narrow "tricks" but generalizable skills; they can be transferred to new tasks and even "distilled" from a capable teacher model to other student models through data alone. Our findings reveal that capability-oriented training induced risks pose a fundamental challenge to current alignment approaches, suggesting that future AI safety work must extend beyond content moderation to rigorously auditing and securing the training environments and reward mechanisms themselves. Code is available at https://github.com/YujunZhou/Capability_Oriented_Alignment_Risk.
From Verification Burden to Trusted Collaboration: Design Goals for LLM-Assisted Literature Reviews
Dec 12, 2025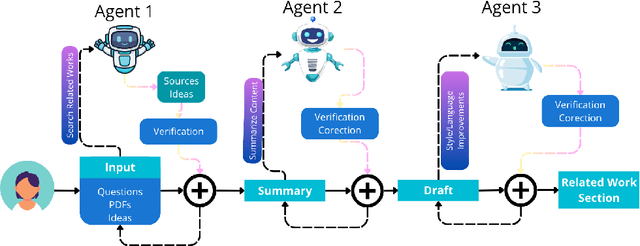
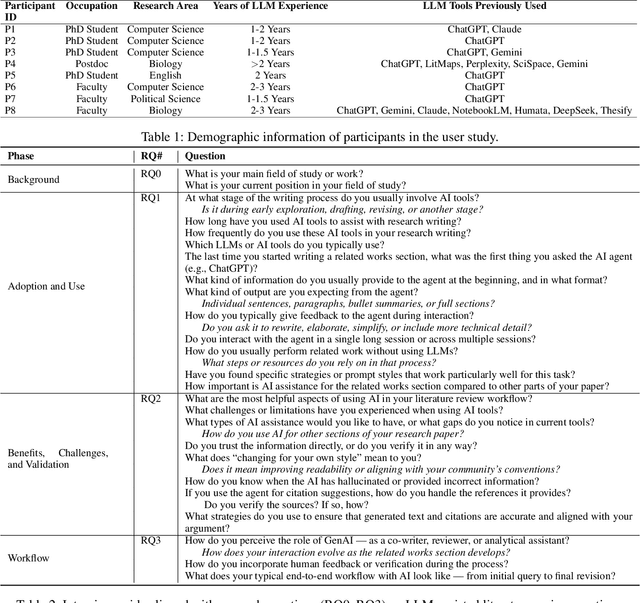
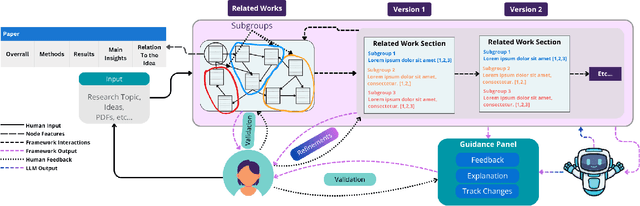
Large Language Models (LLMs) are increasingly embedded in academic writing practices. Although numerous studies have explored how researchers employ these tools for scientific writing, their concrete implementation, limitations, and design challenges within the literature review process remain underexplored. In this paper, we report a user study with researchers across multiple disciplines to characterize current practices, benefits, and \textit{pain points} in using LLMs to investigate related work. We identified three recurring gaps: (i) lack of trust in outputs, (ii) persistent verification burden, and (iii) requiring multiple tools. This motivates our proposal of six design goals and a high-level framework that operationalizes them through improved related papers visualization, verification at every step, and human-feedback alignment with generation-guided explanations. Overall, by grounding our work in the practical, day-to-day needs of researchers, we designed a framework that addresses these limitations and models real-world LLM-assisted writing, advancing trust through verifiable actions and fostering practical collaboration between researchers and AI systems.
SPECTRA: Spectral Target-Aware Graph Augmentation for Imbalanced Molecular Property Regression
Nov 06, 2025In molecular property prediction, the most valuable compounds (e.g., high potency) often occupy sparse regions of the target space. Standard Graph Neural Networks (GNNs) commonly optimize for the average error, underperforming on these uncommon but critical cases, with existing oversampling methods often distorting molecular topology. In this paper, we introduce SPECTRA, a Spectral Target-Aware graph augmentation framework that generates realistic molecular graphs in the spectral domain. SPECTRA (i) reconstructs multi-attribute molecular graphs from SMILES; (ii) aligns molecule pairs via (Fused) Gromov-Wasserstein couplings to obtain node correspondences; (iii) interpolates Laplacian eigenvalues, eigenvectors and node features in a stable share-basis; and (iv) reconstructs edges to synthesize physically plausible intermediates with interpolated targets. A rarity-aware budgeting scheme, derived from a kernel density estimation of labels, concentrates augmentation where data are scarce. Coupled with a spectral GNN using edge-aware Chebyshev convolutions, SPECTRA densifies underrepresented regions without degrading global accuracy. On benchmarks, SPECTRA consistently improves error in relevant target ranges while maintaining competitive overall MAE, and yields interpretable synthetic molecules whose structure reflects the underlying spectral geometry. Our results demonstrate that spectral, geometry-aware augmentation is an effective and efficient strategy for imbalanced molecular property regression.
Spectral Manifold Harmonization for Graph Imbalanced Regression
Jul 01, 2025Graph-structured data is ubiquitous in scientific domains, where models often face imbalanced learning settings. In imbalanced regression, domain preferences focus on specific target value ranges representing the most scientifically valuable cases; we observe a significant lack of research. In this paper, we present Spectral Manifold Harmonization (SMH), a novel approach for addressing this imbalanced regression challenge on graph-structured data by generating synthetic graph samples that preserve topological properties while focusing on often underrepresented target distribution regions. Conventional methods fail in this context because they either ignore graph topology in case generation or do not target specific domain ranges, resulting in models biased toward average target values. Experimental results demonstrate the potential of SMH on chemistry and drug discovery benchmark datasets, showing consistent improvements in predictive performance for target domain ranges.
Intersectional Divergence: Measuring Fairness in Regression
May 01, 2025Research on fairness in machine learning has been mainly framed in the context of classification tasks, leaving critical gaps in regression. In this paper, we propose a seminal approach to measure intersectional fairness in regression tasks, going beyond the focus on single protected attributes from existing work to consider combinations of all protected attributes. Furthermore, we contend that it is insufficient to measure the average error of groups without regard for imbalanced domain preferences. To this end, we propose Intersectional Divergence (ID) as the first fairness measure for regression tasks that 1) describes fair model behavior across multiple protected attributes and 2) differentiates the impact of predictions in target ranges most relevant to users. We extend our proposal demonstrating how ID can be adapted into a loss function, IDLoss, and used in optimization problems. Through an extensive experimental evaluation, we demonstrate how ID allows unique insights into model behavior and fairness, and how incorporating IDLoss into optimization can considerably improve single-attribute and intersectional model fairness while maintaining a competitive balance in predictive performance.