 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoLLMResearch: Training Research Agents for Automating LLM Experiment Configuration -- Learning from Cheap, Optimizing Expensive
May 12, 2026Effectively configuring scalable large language model (LLM) experiments, spanning architecture design, hyperparameter tuning, and beyond, is crucial for advancing LLM research, as poor configuration choices can waste substantial computational resources and prevent models from realizing their full potential. Prior automated methods are designed for low-cost settings where repeated trial and error is feasible, but scalable LLM experiments are too expensive for such extensive iteration. To our knowledge, no work has addressed the automation of high-cost LLM experiment configurations, leaving this problem labor-intensive and dependent on expert intuition. Motivated by this gap, we propose AutoLLMResearch, an agentic framework that mimics how human researchers learn generalizable principles from low-fidelity experiments and extrapolate to efficiently identify promising configurations in expensive LLM settings. The core challenge is how to enable an agent to learn, through interaction with a multi-fidelity experimental environment that captures the structure of the LLM configuration landscape. To achieve this, we propose a systematic framework with two key components: 1) LLMConfig-Gym, a multi-fidelity environment encompassing four critical LLM experiment tasks, supported by over one million GPU hours of verifiable experiment outcomes; 2) A structured training pipeline that formulates configuration research as a long-horizon Markov Decision Process and accordingly incentivizes cross-fidelity extrapolation reasoning. Extensive evaluation against diverse strong baselines on held-out experiments demonstrates the effectiveness, generalization, and interpretability of our framework, supporting its potential as a practical and general solution for scalable real-world LLM experiment automation.
Do LLMs have core beliefs?
May 05, 2026The rise of Large Language Models (LLMs) has sparked debate about whether these systems exhibit human-level cognition. In this debate, little attention has been paid to a structural component of human cognition: core beliefs, truths that provide a foundation around which we can build a worldview. These commitments usually resist debunking, as abandoning them would represent a fundamental shift in how we see reality. In this paper, we ask whether LLMs hold anything akin to core commitments. Using a probing framework we call Adversarial Dialogue Trees (ADTs) over five domains (science, history, geography, biology, and mathematics), we find that most LLMs fail to maintain a stable worldview. Though some recent models showed improved stability, they still eventually failed to maintain key commitments under conversational pressure. These results document an improvement in argumentative skills across model generations but indicate that all current models lack a key component of human-level cognition.
TeachingCoach: A Fine-Tuned Scaffolding Chatbot for Instructional Guidance to Instructors
Mar 18, 2026Higher education instructors often lack timely and pedagogically grounded support, as scalable instructional guidance remains limited and existing tools rely on generic chatbot advice or non-scalable teaching center human-human consultations. We present TeachingCoach, a pedagogically grounded chatbot designed to support instructor professional development through real-time, conversational guidance. TeachingCoach is built on a data-centric pipeline that extracts pedagogical rules from educational resources and uses synthetic dialogue generation to fine-tune a specialized language model that guides instructors through problem identification, diagnosis, and strategy development. Expert evaluations show TeachingCoach produces clearer, more reflective, and more responsive guidance than a GPT-4o mini baseline, while a user study with higher education instructors highlights trade-offs between conversational depth and interaction efficiency. Together, these results demonstrate that pedagogically grounded, synthetic data driven chatbots can improve instructional support and offer a scalable design approach for future instructional chatbot systems.
Generalist Large Language Models for Molecular Property Prediction: Distilling Knowledge from Specialist Models
Mar 12, 2026Molecular Property Prediction (MPP) is a central task in drug discovery. While Large Language Models (LLMs) show promise as generalist models for MPP, their current performance remains below the threshold for practical adoption. We propose TreeKD, a novel knowledge distillation method that transfers complementary knowledge from tree-based specialist models into LLMs. Our approach trains specialist decision trees on functional group features, then verbalizes their learned predictive rules as natural language to enable rule-augmented context learning. This enables LLMs to leverage structural insights that are difficult to extract from SMILES strings alone. We further introduce rule-consistency, a test-time scaling technique inspired by bagging that ensembles predictions across diverse rules from a Random Forest. Experiments on 22 ADMET properties from the TDC benchmark demonstrate that TreeKD substantially improves LLM performance, narrowing the gap with SOTA specialist models and advancing toward practical generalist models for molecular property prediction.
Transform-Augmented GRPO Improves Pass@k
Jan 30, 2026Large language models trained via next-token prediction are fundamentally pattern-matchers: sensitive to superficial phrasing variations even when the underlying problem is identical. Group Relative Policy Optimization (GRPO) was designed to improve reasoning, but in fact it worsens this situation through two failure modes: diversity collapse, where training amplifies a single solution strategy while ignoring alternatives of gradient signal, and gradient diminishing, where a large portion of questions yield zero gradients because all rollouts receive identical rewards. We propose TA-GRPO (Transform-Augmented GRPO), which generates semantically equivalent transformed variants of each question (via paraphrasing, variable renaming, and format changes) and computes advantages by pooling rewards across the entire group. This pooled computation ensures mixed rewards even when the original question is too easy or too hard, while training on diverse phrasings promotes multiple solution strategies. We provide theoretical justification showing that TA-GRPO reduces zero-gradient probability and improves generalization via reduced train-test distribution shift. Experiments on mathematical reasoning benchmarks show consistent Pass@k improvements, with gains up to 9.84 points on competition math (AMC12, AIME24) and 5.05 points on out-of-distribution scientific reasoning (GPQA-Diamond).
Automated Benchmark Generation from Domain Guidelines Informed by Bloom's Taxonomy
Jan 28, 2026Open-ended question answering (QA) evaluates a model's ability to perform contextualized reasoning beyond factual recall. This challenge is especially acute in practice-based domains, where knowledge is procedural and grounded in professional judgment, while most existing LLM benchmarks depend on pre-existing human exam datasets that are often unavailable in such settings. We introduce a framework for automated benchmark generation from expert-authored guidelines informed by Bloom's Taxonomy. It converts expert practices into implicit violation-based scenarios and expands them into auto-graded multiple-choice questions (MCQs) and multi-turn dialogues across four cognitive levels, enabling deterministic, reproducible, and scalable evaluation. Applied to three applied domains: teaching, dietetics, and caregiving, we find differences between model and human-like reasoning: LLMs sometimes perform relatively better on higher-order reasoning (Analyze) but fail more frequently on lower-level items (Remember). We produce large-scale, psychometrically informed benchmarks that surface these non-intuitive model behaviors and enable evaluation of contextualized reasoning in real-world settings.
From Verification Burden to Trusted Collaboration: Design Goals for LLM-Assisted Literature Reviews
Dec 12, 2025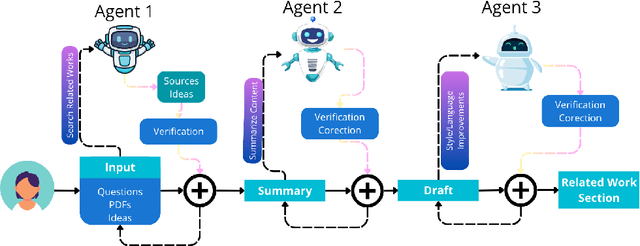
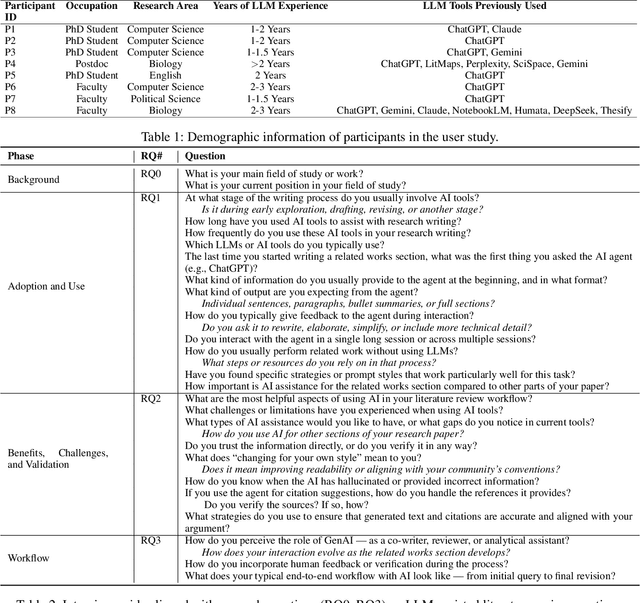
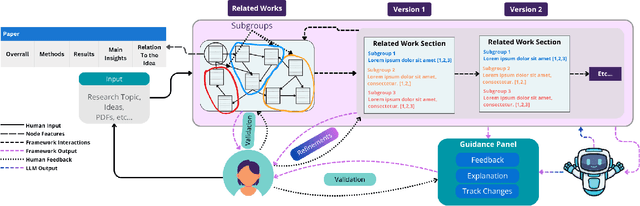
Large Language Models (LLMs) are increasingly embedded in academic writing practices. Although numerous studies have explored how researchers employ these tools for scientific writing, their concrete implementation, limitations, and design challenges within the literature review process remain underexplored. In this paper, we report a user study with researchers across multiple disciplines to characterize current practices, benefits, and \textit{pain points} in using LLMs to investigate related work. We identified three recurring gaps: (i) lack of trust in outputs, (ii) persistent verification burden, and (iii) requiring multiple tools. This motivates our proposal of six design goals and a high-level framework that operationalizes them through improved related papers visualization, verification at every step, and human-feedback alignment with generation-guided explanations. Overall, by grounding our work in the practical, day-to-day needs of researchers, we designed a framework that addresses these limitations and models real-world LLM-assisted writing, advancing trust through verifiable actions and fostering practical collaboration between researchers and AI systems.
CrochetBench: Can Vision-Language Models Move from Describing to Doing in Crochet Domain?
Nov 12, 2025

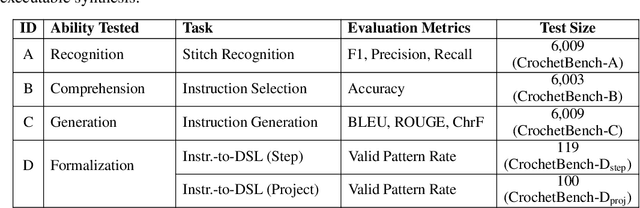
We present CrochetBench, a benchmark for evaluating the ability of multimodal large language models to perform fine-grained, low-level procedural reasoning in the domain of crochet. Unlike prior benchmarks that focus on high-level description or visual question answering, CrochetBench shifts the emphasis from describing to doing: models are required to recognize stitches, select structurally appropriate instructions, and generate compilable crochet procedures. We adopt the CrochetPARADE DSL as our intermediate representation, enabling structural validation and functional evaluation via execution. The benchmark covers tasks including stitch classification, instruction grounding, and both natural language and image-to-DSL translation. Across all tasks, performance sharply declines as the evaluation shifts from surface-level similarity to executable correctness, exposing limitations in long-range symbolic reasoning and 3D-aware procedural synthesis. CrochetBench offers a new lens for assessing procedural competence in multimodal models and highlights the gap between surface-level understanding and executable precision in real-world creative domains. Code is available at https://github.com/Peiyu-Georgia-Li/crochetBench.
SPECTRA: Spectral Target-Aware Graph Augmentation for Imbalanced Molecular Property Regression
Nov 06, 2025In molecular property prediction, the most valuable compounds (e.g., high potency) often occupy sparse regions of the target space. Standard Graph Neural Networks (GNNs) commonly optimize for the average error, underperforming on these uncommon but critical cases, with existing oversampling methods often distorting molecular topology. In this paper, we introduce SPECTRA, a Spectral Target-Aware graph augmentation framework that generates realistic molecular graphs in the spectral domain. SPECTRA (i) reconstructs multi-attribute molecular graphs from SMILES; (ii) aligns molecule pairs via (Fused) Gromov-Wasserstein couplings to obtain node correspondences; (iii) interpolates Laplacian eigenvalues, eigenvectors and node features in a stable share-basis; and (iv) reconstructs edges to synthesize physically plausible intermediates with interpolated targets. A rarity-aware budgeting scheme, derived from a kernel density estimation of labels, concentrates augmentation where data are scarce. Coupled with a spectral GNN using edge-aware Chebyshev convolutions, SPECTRA densifies underrepresented regions without degrading global accuracy. On benchmarks, SPECTRA consistently improves error in relevant target ranges while maintaining competitive overall MAE, and yields interpretable synthetic molecules whose structure reflects the underlying spectral geometry. Our results demonstrate that spectral, geometry-aware augmentation is an effective and efficient strategy for imbalanced molecular property regression.
The Reasoning Boundary Paradox: How Reinforcement Learning Constrains Language Models
Oct 02, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a key method for improving Large Language Models' reasoning capabilities, yet recent evidence suggests it may paradoxically shrink the reasoning boundary rather than expand it. This paper investigates the shrinkage issue of RLVR by analyzing its learning dynamics and reveals two critical phenomena that explain this failure. First, we expose negative interference in RLVR, where learning to solve certain training problems actively reduces the likelihood of correct solutions for others, leading to the decline of Pass@$k$ performance, or the probability of generating a correct solution within $k$ attempts. Second, we uncover the winner-take-all phenomenon: RLVR disproportionately reinforces problems with high likelihood, correct solutions, under the base model, while suppressing other initially low-likelihood ones. Through extensive theoretical and empirical analysis on multiple mathematical reasoning benchmarks, we show that this effect arises from the inherent on-policy sampling in standard RL objectives, causing the model to converge toward narrow solution strategies. Based on these insights, we propose a simple yet effective data curation algorithm that focuses RLVR learning on low-likelihood problems, achieving notable improvement in Pass@$k$ performance. Our code is available at https://github.com/mail-research/SELF-llm-interference.