 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding the Critique Mechanism in Large Reasoning Models
Mar 17, 2026Large Reasoning Models (LRMs) exhibit backtracking and self-verification mechanisms that enable them to revise intermediate steps and reach correct solutions, yielding strong performance on complex logical benchmarks. We hypothesize that such behaviors are beneficial only when the model has sufficiently strong "critique" ability to detect its own mistakes. This work systematically investigates how current LRMs recover from errors by inserting arithmetic mistakes in their intermediate reasoning steps. Notably, we discover a peculiar yet important phenomenon: despite the error propagating through the chain-of-thought (CoT), resulting in an incorrect intermediate conclusion, the model still reaches the correct final answer. This recovery implies that the model must possess an internal mechanism to detect errors and trigger self-correction, which we refer to as the hidden critique ability. Building on feature space analysis, we identify a highly interpretable critique vector representing this behavior. Extensive experiments across multiple model scales and families demonstrate that steering latent representations with this vector improves the model's error detection capability and enhances the performance of test-time scaling at no extra training cost. Our findings provide a valuable understanding of LRMs' critique behavior, suggesting a promising direction to control and improve their self-verification mechanism. Our code is available at https://github.com/mail-research/lrm-critique-vectors.
How Many Tokens Do 3D Point Cloud Transformer Architectures Really Need?
Nov 07, 2025Recent advances in 3D point cloud transformers have led to state-of-the-art results in tasks such as semantic segmentation and reconstruction. However, these models typically rely on dense token representations, incurring high computational and memory costs during training and inference. In this work, we present the finding that tokens are remarkably redundant, leading to substantial inefficiency. We introduce gitmerge3D, a globally informed graph token merging method that can reduce the token count by up to 90-95% while maintaining competitive performance. This finding challenges the prevailing assumption that more tokens inherently yield better performance and highlights that many current models are over-tokenized and under-optimized for scalability. We validate our method across multiple 3D vision tasks and show consistent improvements in computational efficiency. This work is the first to assess redundancy in large-scale 3D transformer models, providing insights into the development of more efficient 3D foundation architectures. Our code and checkpoints are publicly available at https://gitmerge3d.github.io
The Reasoning Boundary Paradox: How Reinforcement Learning Constrains Language Models
Oct 02, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a key method for improving Large Language Models' reasoning capabilities, yet recent evidence suggests it may paradoxically shrink the reasoning boundary rather than expand it. This paper investigates the shrinkage issue of RLVR by analyzing its learning dynamics and reveals two critical phenomena that explain this failure. First, we expose negative interference in RLVR, where learning to solve certain training problems actively reduces the likelihood of correct solutions for others, leading to the decline of Pass@$k$ performance, or the probability of generating a correct solution within $k$ attempts. Second, we uncover the winner-take-all phenomenon: RLVR disproportionately reinforces problems with high likelihood, correct solutions, under the base model, while suppressing other initially low-likelihood ones. Through extensive theoretical and empirical analysis on multiple mathematical reasoning benchmarks, we show that this effect arises from the inherent on-policy sampling in standard RL objectives, causing the model to converge toward narrow solution strategies. Based on these insights, we propose a simple yet effective data curation algorithm that focuses RLVR learning on low-likelihood problems, achieving notable improvement in Pass@$k$ performance. Our code is available at https://github.com/mail-research/SELF-llm-interference.
Mitigating Reward Over-optimization in Direct Alignment Algorithms with Importance Sampling
Jun 11, 2025Direct Alignment Algorithms (DAAs) such as Direct Preference Optimization (DPO) have emerged as alternatives to the standard Reinforcement Learning from Human Feedback (RLHF) for aligning large language models (LLMs) with human values. However, these methods are more susceptible to over-optimization, in which the model drifts away from the reference policy, leading to degraded performance as training progresses. This paper proposes a novel importance-sampling approach to mitigate the over-optimization problem of offline DAAs. This approach, called (IS-DAAs), multiplies the DAA objective with an importance ratio that accounts for the reference policy distribution. IS-DAAs additionally avoid the high variance issue associated with importance sampling by clipping the importance ratio to a maximum value. Our extensive experiments demonstrate that IS-DAAs can effectively mitigate over-optimization, especially under low regularization strength, and achieve better performance than other methods designed to address this problem. Our implementations are provided publicly at this link.
Are you SURE? Enhancing Multimodal Pretraining with Missing Modalities through Uncertainty Estimation
Apr 18, 2025Multimodal learning has demonstrated incredible successes by integrating diverse data sources, yet it often relies on the availability of all modalities - an assumption that rarely holds in real-world applications. Pretrained multimodal models, while effective, struggle when confronted with small-scale and incomplete datasets (i.e., missing modalities), limiting their practical applicability. Previous studies on reconstructing missing modalities have overlooked the reconstruction's potential unreliability, which could compromise the quality of the final outputs. We present SURE (Scalable Uncertainty and Reconstruction Estimation), a novel framework that extends the capabilities of pretrained multimodal models by introducing latent space reconstruction and uncertainty estimation for both reconstructed modalities and downstream tasks. Our method is architecture-agnostic, reconstructs missing modalities, and delivers reliable uncertainty estimates, improving both interpretability and performance. SURE introduces a unique Pearson Correlation-based loss and applies statistical error propagation in deep networks for the first time, allowing precise quantification of uncertainties from missing data and model predictions. Extensive experiments across tasks such as sentiment analysis, genre classification, and action recognition show that SURE consistently achieves state-of-the-art performance, ensuring robust predictions even in the presence of incomplete data.
Unveiling Concept Attribution in Diffusion Models
Dec 03, 2024



Diffusion models have shown remarkable abilities in generating realistic and high-quality images from text prompts. However, a trained model remains black-box; little do we know about the role of its components in exhibiting a concept such as objects or styles. Recent works employ causal tracing to localize layers storing knowledge in generative models without showing how those layers contribute to the target concept. In this work, we approach the model interpretability problem from a more general perspective and pose a question: \textit{``How do model components work jointly to demonstrate knowledge?''}. We adapt component attribution to decompose diffusion models, unveiling how a component contributes to a concept. Our framework allows effective model editing, in particular, we can erase a concept from diffusion models by removing positive components while remaining knowledge of other concepts. Surprisingly, we also show there exist components that contribute negatively to a concept, which has not been discovered in the knowledge localization approach. Experimental results confirm the role of positive and negative components pinpointed by our framework, depicting a complete view of interpreting generative models. Our code is available at \url{https://github.com/mail-research/CAD-attribution4diffusion}
Flatness-aware Sequential Learning Generates Resilient Backdoors
Jul 20, 2024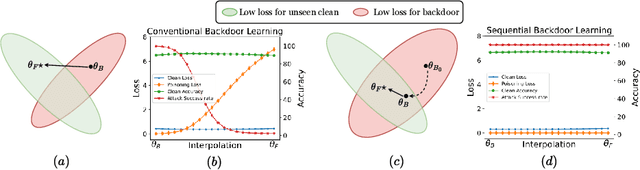
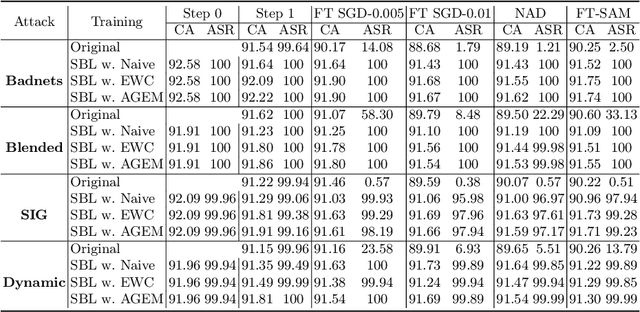
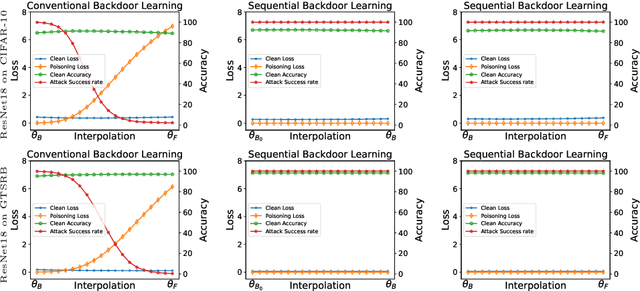
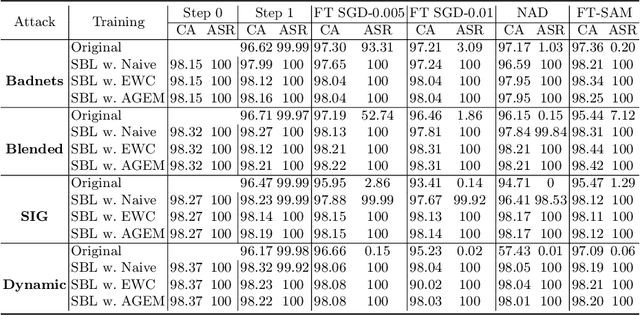
Recently, backdoor attacks have become an emerging threat to the security of machine learning models. From the adversary's perspective, the implanted backdoors should be resistant to defensive algorithms, but some recently proposed fine-tuning defenses can remove these backdoors with notable efficacy. This is mainly due to the catastrophic forgetting (CF) property of deep neural networks. This paper counters CF of backdoors by leveraging continual learning (CL) techniques. We begin by investigating the connectivity between a backdoored and fine-tuned model in the loss landscape. Our analysis confirms that fine-tuning defenses, especially the more advanced ones, can easily push a poisoned model out of the backdoor regions, making it forget all about the backdoors. Based on this finding, we re-formulate backdoor training through the lens of CL and propose a novel framework, named Sequential Backdoor Learning (SBL), that can generate resilient backdoors. This framework separates the backdoor poisoning process into two tasks: the first task learns a backdoored model, while the second task, based on the CL principles, moves it to a backdoored region resistant to fine-tuning. We additionally propose to seek flatter backdoor regions via a sharpness-aware minimizer in the framework, further strengthening the durability of the implanted backdoor. Finally, we demonstrate the effectiveness of our method through extensive empirical experiments on several benchmark datasets in the backdoor domain. The source code is available at https://github.com/mail-research/SBL-resilient-backdoors
Less is More: Sparse Watermarking in LLMs with Enhanced Text Quality
Jul 17, 2024With the widespread adoption of Large Language Models (LLMs), concerns about potential misuse have emerged. To this end, watermarking has been adapted to LLM, enabling a simple and effective way to detect and monitor generated text. However, while the existing methods can differentiate between watermarked and unwatermarked text with high accuracy, they often face a trade-off between the quality of the generated text and the effectiveness of the watermarking process. In this work, we present a novel type of LLM watermark, Sparse Watermark, which aims to mitigate this trade-off by applying watermarks to a small subset of generated tokens distributed across the text. The key strategy involves anchoring watermarked tokens to words that have specific Part-of-Speech (POS) tags. Our experimental results demonstrate that the proposed watermarking scheme achieves high detectability while generating text that outperforms previous LLM watermarking methods in quality across various tasks
Wicked Oddities: Selectively Poisoning for Effective Clean-Label Backdoor Attacks
Jul 16, 2024
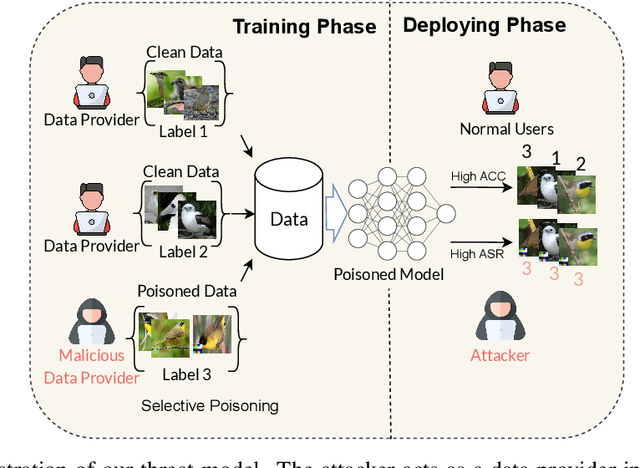
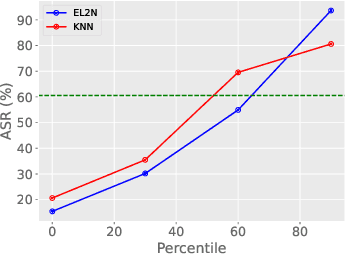
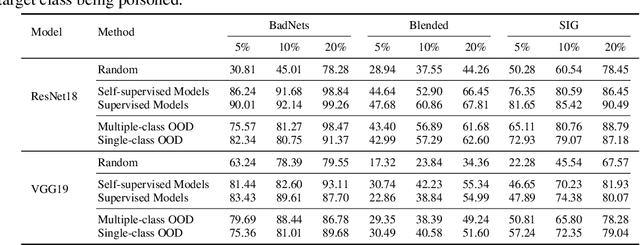
Deep neural networks are vulnerable to backdoor attacks, a type of adversarial attack that poisons the training data to manipulate the behavior of models trained on such data. Clean-label attacks are a more stealthy form of backdoor attacks that can perform the attack without changing the labels of poisoned data. Early works on clean-label attacks added triggers to a random subset of the training set, ignoring the fact that samples contribute unequally to the attack's success. This results in high poisoning rates and low attack success rates. To alleviate the problem, several supervised learning-based sample selection strategies have been proposed. However, these methods assume access to the entire labeled training set and require training, which is expensive and may not always be practical. This work studies a new and more practical (but also more challenging) threat model where the attacker only provides data for the target class (e.g., in face recognition systems) and has no knowledge of the victim model or any other classes in the training set. We study different strategies for selectively poisoning a small set of training samples in the target class to boost the attack success rate in this setting. Our threat model poses a serious threat in training machine learning models with third-party datasets, since the attack can be performed effectively with limited information. Experiments on benchmark datasets illustrate the effectiveness of our strategies in improving clean-label backdoor attacks.
MetaLLM: A High-performant and Cost-efficient Dynamic Framework for Wrapping LLMs
Jul 15, 2024The rapid progress in machine learning (ML) has brought forth many large language models (LLMs) that excel in various tasks and areas. These LLMs come with different abilities and costs in terms of computation or pricing. Since the demand for each query can vary, e.g., because of the queried domain or its complexity, defaulting to one LLM in an application is not usually the best choice, whether it is the biggest, priciest, or even the one with the best average test performance. Consequently, picking the right LLM that is both accurate and cost-effective for an application remains a challenge. In this paper, we introduce MetaLLM, a framework that dynamically and intelligently routes each query to the optimal LLM (among several available LLMs) for classification tasks, achieving significantly improved accuracy and cost-effectiveness. By framing the selection problem as a multi-armed bandit, MetaLLM balances prediction accuracy and cost efficiency under uncertainty. Our experiments, conducted on popular LLM platforms such as OpenAI's GPT models, Amazon's Titan, Anthropic's Claude, and Meta's LLaMa, showcase MetaLLM's efficacy in real-world scenarios, laying the groundwork for future extensions beyond classification tasks.