 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPAR: Session-based Pipeline for Adaptive Retrieval on Legacy File Systems
Dec 15, 2025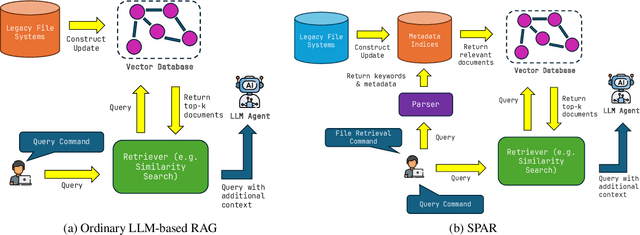

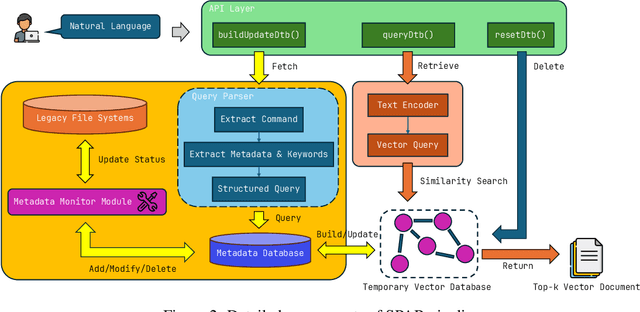

The ability to extract value from historical data is essential for enterprise decision-making. However, much of this information remains inaccessible within large legacy file systems that lack structured organization and semantic indexing, making retrieval and analysis inefficient and error-prone. We introduce SPAR (Session-based Pipeline for Adaptive Retrieval), a conceptual framework that integrates Large Language Models (LLMs) into a Retrieval-Augmented Generation (RAG) architecture specifically designed for legacy enterprise environments. Unlike conventional RAG pipelines, which require costly construction and maintenance of full-scale vector databases that mirror the entire file system, SPAR employs a lightweight two-stage process: a semantic Metadata Index is first created, after which session-specific vector databases are dynamically generated on demand. This design reduces computational overhead while improving transparency, controllability, and relevance in retrieval. We provide a theoretical complexity analysis comparing SPAR with standard LLM-based RAG pipelines, demonstrating its computational advantages. To validate the framework, we apply SPAR to a synthesized enterprise-scale file system containing a large corpus of biomedical literature, showing improvements in both retrieval effectiveness and downstream model accuracy. Finally, we discuss design trade-offs and outline open challenges for deploying SPAR across diverse enterprise settings.
Robult: Leveraging Redundancy and Modality Specific Features for Robust Multimodal Learning
Sep 03, 2025Addressing missing modalities and limited labeled data is crucial for advancing robust multimodal learning. We propose Robult, a scalable framework designed to mitigate these challenges by preserving modality-specific information and leveraging redundancy through a novel information-theoretic approach. Robult optimizes two core objectives: (1) a soft Positive-Unlabeled (PU) contrastive loss that maximizes task-relevant feature alignment while effectively utilizing limited labeled data in semi-supervised settings, and (2) a latent reconstruction loss that ensures unique modality-specific information is retained. These strategies, embedded within a modular design, enhance performance across various downstream tasks and ensure resilience to incomplete modalities during inference. Experimental results across diverse datasets validate that Robult achieves superior performance over existing approaches in both semi-supervised learning and missing modality contexts. Furthermore, its lightweight design promotes scalability and seamless integration with existing architectures, making it suitable for real-world multimodal applications.
Are you SURE? Enhancing Multimodal Pretraining with Missing Modalities through Uncertainty Estimation
Apr 18, 2025Multimodal learning has demonstrated incredible successes by integrating diverse data sources, yet it often relies on the availability of all modalities - an assumption that rarely holds in real-world applications. Pretrained multimodal models, while effective, struggle when confronted with small-scale and incomplete datasets (i.e., missing modalities), limiting their practical applicability. Previous studies on reconstructing missing modalities have overlooked the reconstruction's potential unreliability, which could compromise the quality of the final outputs. We present SURE (Scalable Uncertainty and Reconstruction Estimation), a novel framework that extends the capabilities of pretrained multimodal models by introducing latent space reconstruction and uncertainty estimation for both reconstructed modalities and downstream tasks. Our method is architecture-agnostic, reconstructs missing modalities, and delivers reliable uncertainty estimates, improving both interpretability and performance. SURE introduces a unique Pearson Correlation-based loss and applies statistical error propagation in deep networks for the first time, allowing precise quantification of uncertainties from missing data and model predictions. Extensive experiments across tasks such as sentiment analysis, genre classification, and action recognition show that SURE consistently achieves state-of-the-art performance, ensuring robust predictions even in the presence of incomplete data.
RL-based Query Rewriting with Distilled LLM for online E-Commerce Systems
Jan 29, 2025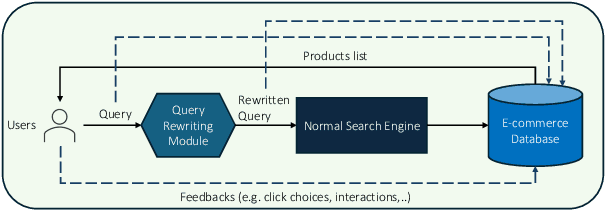

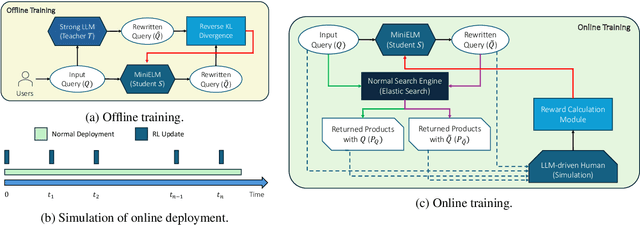
Query rewriting (QR) is a critical technique in e-commerce search, addressing the lexical gap between user queries and product descriptions to enhance search performance. Existing QR approaches typically fall into two categories: discriminative models and generative methods leveraging large language models (LLMs). Discriminative models often struggle with natural language understanding and offer limited flexibility in rewriting, while generative LLMs, despite producing high-quality rewrites, face high inference latency and cost in online settings. These limitations force offline deployment, making them vulnerable to issues like information staleness and semantic drift. To overcome these challenges, we propose a novel hybrid pipeline for QR that balances efficiency and effectiveness. Our approach combines offline knowledge distillation to create a lightweight but efficient student model with online reinforcement learning (RL) to refine query rewriting dynamically using real-time feedback. A key innovation is the use of LLMs as simulated human feedback, enabling scalable reward signals and cost-effective evaluation without manual annotations. Experimental results on Amazon ESCI dataset demonstrate significant improvements in query relevance, diversity, and adaptability, as well as positive feedback from the LLM simulation. This work contributes to advancing LLM capabilities for domain-specific applications, offering a robust solution for dynamic and complex e-commerce search environments.