 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHugRAG: Hierarchical Causal Knowledge Graph Design for RAG
Feb 04, 2026Retrieval augmented generation (RAG) has enhanced large language models by enabling access to external knowledge, with graph-based RAG emerging as a powerful paradigm for structured retrieval and reasoning. However, existing graph-based methods often over-rely on surface-level node matching and lack explicit causal modeling, leading to unfaithful or spurious answers. Prior attempts to incorporate causality are typically limited to local or single-document contexts and also suffer from information isolation that arises from modular graph structures, which hinders scalability and cross-module causal reasoning. To address these challenges, we propose HugRAG, a framework that rethinks knowledge organization for graph-based RAG through causal gating across hierarchical modules. HugRAG explicitly models causal relationships to suppress spurious correlations while enabling scalable reasoning over large-scale knowledge graphs. Extensive experiments demonstrate that HugRAG consistently outperforms competitive graph-based RAG baselines across multiple datasets and evaluation metrics. Our work establishes a principled foundation for structured, scalable, and causally grounded RAG systems.
RL-based Query Rewriting with Distilled LLM for online E-Commerce Systems
Jan 29, 2025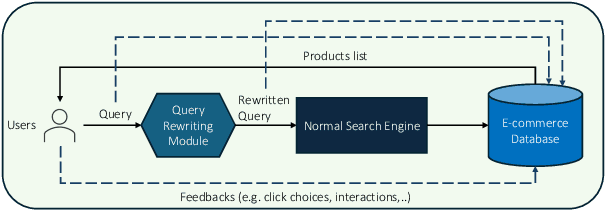

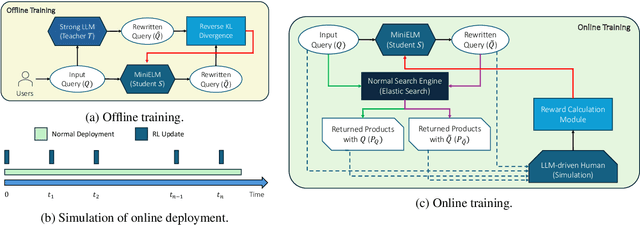
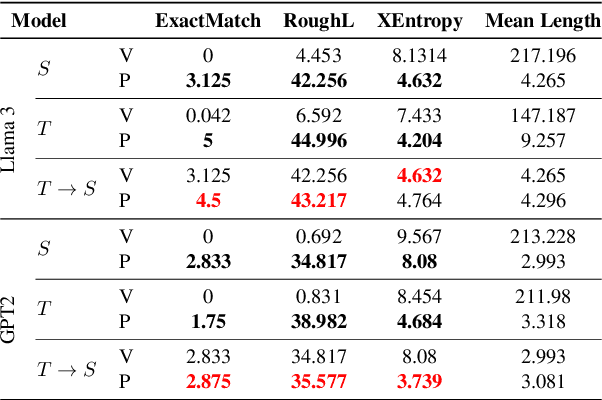
Query rewriting (QR) is a critical technique in e-commerce search, addressing the lexical gap between user queries and product descriptions to enhance search performance. Existing QR approaches typically fall into two categories: discriminative models and generative methods leveraging large language models (LLMs). Discriminative models often struggle with natural language understanding and offer limited flexibility in rewriting, while generative LLMs, despite producing high-quality rewrites, face high inference latency and cost in online settings. These limitations force offline deployment, making them vulnerable to issues like information staleness and semantic drift. To overcome these challenges, we propose a novel hybrid pipeline for QR that balances efficiency and effectiveness. Our approach combines offline knowledge distillation to create a lightweight but efficient student model with online reinforcement learning (RL) to refine query rewriting dynamically using real-time feedback. A key innovation is the use of LLMs as simulated human feedback, enabling scalable reward signals and cost-effective evaluation without manual annotations. Experimental results on Amazon ESCI dataset demonstrate significant improvements in query relevance, diversity, and adaptability, as well as positive feedback from the LLM simulation. This work contributes to advancing LLM capabilities for domain-specific applications, offering a robust solution for dynamic and complex e-commerce search environments.