 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Recommending Category: A Cascading Approach
Dec 17, 2025Recommendation plays a key role in e-commerce, enhancing user experience and boosting commercial success. Existing works mainly focus on recommending a set of items, but online e-commerce platforms have recently begun to pay attention to exploring users' potential interests at the category level. Category-level recommendation allows e-commerce platforms to promote users' engagements by expanding their interests to different types of items. In addition, it complements item-level recommendations when the latter becomes extremely challenging for users with little-known information and past interactions. Furthermore, it facilitates item-level recommendations in existing works. The predicted category, which is called intention in those works, aids the exploration of item-level preference. However, such category-level preference prediction has mostly been accomplished through applying item-level models. Some key differences between item-level recommendations and category-level recommendations are ignored in such a simplistic adaptation. In this paper, we propose a cascading category recommender (CCRec) model with a variational autoencoder (VAE) to encode item-level information to perform category-level recommendations. Experiments show the advantages of this model over methods designed for item-level recommendations.
Understanding Cross-Domain Adaptation in Low-Resource Topic Modeling
Jun 09, 2025Topic modeling plays a vital role in uncovering hidden semantic structures within text corpora, but existing models struggle in low-resource settings where limited target-domain data leads to unstable and incoherent topic inference. We address this challenge by formally introducing domain adaptation for low-resource topic modeling, where a high-resource source domain informs a low-resource target domain without overwhelming it with irrelevant content. We establish a finite-sample generalization bound showing that effective knowledge transfer depends on robust performance in both domains, minimizing latent-space discrepancy, and preventing overfitting to the data. Guided by these insights, we propose DALTA (Domain-Aligned Latent Topic Adaptation), a new framework that employs a shared encoder for domain-invariant features, specialized decoders for domain-specific nuances, and adversarial alignment to selectively transfer relevant information. Experiments on diverse low-resource datasets demonstrate that DALTA consistently outperforms state-of-the-art methods in terms of topic coherence, stability, and transferability.
ERU-KG: Efficient Reference-aligned Unsupervised Keyphrase Generation
May 30, 2025Unsupervised keyphrase prediction has gained growing interest in recent years. However, existing methods typically rely on heuristically defined importance scores, which may lead to inaccurate informativeness estimation. In addition, they lack consideration for time efficiency. To solve these problems, we propose ERU-KG, an unsupervised keyphrase generation (UKG) model that consists of an informativeness and a phraseness module. The former estimates the relevance of keyphrase candidates, while the latter generate those candidates. The informativeness module innovates by learning to model informativeness through references (e.g., queries, citation contexts, and titles) and at the term-level, thereby 1) capturing how the key concepts of documents are perceived in different contexts and 2) estimating informativeness of phrases more efficiently by aggregating term informativeness, removing the need for explicit modeling of the candidates. ERU-KG demonstrates its effectiveness on keyphrase generation benchmarks by outperforming unsupervised baselines and achieving on average 89\% of the performance of a supervised model for top 10 predictions. Additionally, to highlight its practical utility, we evaluate the model on text retrieval tasks and show that keyphrases generated by ERU-KG are effective when employed as query and document expansions. Furthermore, inference speed tests reveal that ERU-KG is the fastest among baselines of similar model sizes. Finally, our proposed model can switch between keyphrase generation and extraction by adjusting hyperparameters, catering to diverse application requirements.
RL-based Query Rewriting with Distilled LLM for online E-Commerce Systems
Jan 29, 2025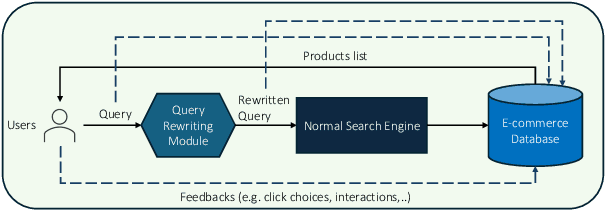

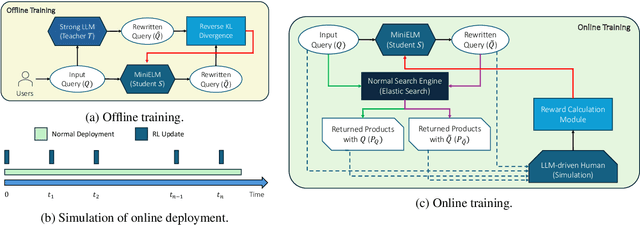
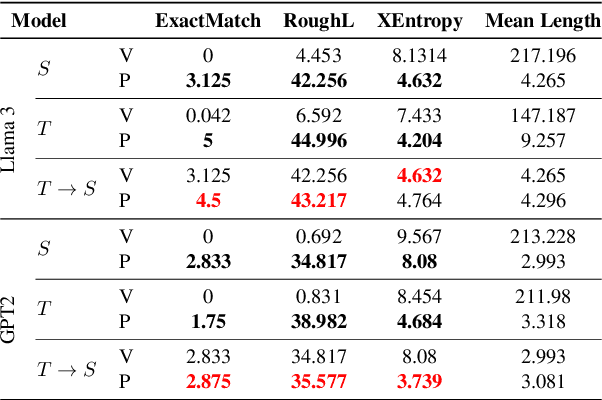
Query rewriting (QR) is a critical technique in e-commerce search, addressing the lexical gap between user queries and product descriptions to enhance search performance. Existing QR approaches typically fall into two categories: discriminative models and generative methods leveraging large language models (LLMs). Discriminative models often struggle with natural language understanding and offer limited flexibility in rewriting, while generative LLMs, despite producing high-quality rewrites, face high inference latency and cost in online settings. These limitations force offline deployment, making them vulnerable to issues like information staleness and semantic drift. To overcome these challenges, we propose a novel hybrid pipeline for QR that balances efficiency and effectiveness. Our approach combines offline knowledge distillation to create a lightweight but efficient student model with online reinforcement learning (RL) to refine query rewriting dynamically using real-time feedback. A key innovation is the use of LLMs as simulated human feedback, enabling scalable reward signals and cost-effective evaluation without manual annotations. Experimental results on Amazon ESCI dataset demonstrate significant improvements in query relevance, diversity, and adaptability, as well as positive feedback from the LLM simulation. This work contributes to advancing LLM capabilities for domain-specific applications, offering a robust solution for dynamic and complex e-commerce search environments.
Query Optimization for Parametric Knowledge Refinement in Retrieval-Augmented Large Language Models
Nov 13, 2024



We introduce the Extract-Refine-Retrieve-Read (ERRR) framework, a novel approach designed to bridge the pre-retrieval information gap in Retrieval-Augmented Generation (RAG) systems through query optimization tailored to meet the specific knowledge requirements of Large Language Models (LLMs). Unlike conventional query optimization techniques used in RAG, the ERRR framework begins by extracting parametric knowledge from LLMs, followed by using a specialized query optimizer for refining these queries. This process ensures the retrieval of only the most pertinent information essential for generating accurate responses. Moreover, to enhance flexibility and reduce computational costs, we propose a trainable scheme for our pipeline that utilizes a smaller, tunable model as the query optimizer, which is refined through knowledge distillation from a larger teacher model. Our evaluations on various question-answering (QA) datasets and with different retrieval systems show that ERRR consistently outperforms existing baselines, proving to be a versatile and cost-effective module for improving the utility and accuracy of RAG systems.
ConTReGen: Context-driven Tree-structured Retrieval for Open-domain Long-form Text Generation
Oct 20, 2024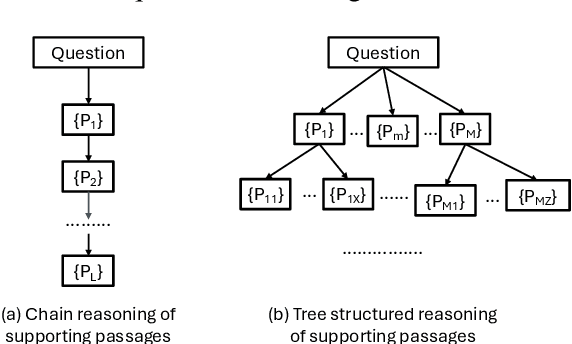



Open-domain long-form text generation requires generating coherent, comprehensive responses that address complex queries with both breadth and depth. This task is challenging due to the need to accurately capture diverse facets of input queries. Existing iterative retrieval-augmented generation (RAG) approaches often struggle to delve deeply into each facet of complex queries and integrate knowledge from various sources effectively. This paper introduces ConTReGen, a novel framework that employs a context-driven, tree-structured retrieval approach to enhance the depth and relevance of retrieved content. ConTReGen integrates a hierarchical, top-down in-depth exploration of query facets with a systematic bottom-up synthesis, ensuring comprehensive coverage and coherent integration of multifaceted information. Extensive experiments on multiple datasets, including LFQA and ODSUM, alongside a newly introduced dataset, ODSUM-WikiHow, demonstrate that ConTReGen outperforms existing state-of-the-art RAG models.
Enhancing Short-Text Topic Modeling with LLM-Driven Context Expansion and Prefix-Tuned VAEs
Oct 04, 2024Topic modeling is a powerful technique for uncovering hidden themes within a collection of documents. However, the effectiveness of traditional topic models often relies on sufficient word co-occurrence, which is lacking in short texts. Therefore, existing approaches, whether probabilistic or neural, frequently struggle to extract meaningful patterns from such data, resulting in incoherent topics. To address this challenge, we propose a novel approach that leverages large language models (LLMs) to extend short texts into more detailed sequences before applying topic modeling. To further improve the efficiency and solve the problem of semantic inconsistency from LLM-generated texts, we propose to use prefix tuning to train a smaller language model coupled with a variational autoencoder for short-text topic modeling. Our method significantly improves short-text topic modeling performance, as demonstrated by extensive experiments on real-world datasets with extreme data sparsity, outperforming current state-of-the-art topic models.
Long-form Question Answering: An Iterative Planning-Retrieval-Generation Approach
Nov 15, 2023Long-form question answering (LFQA) poses a challenge as it involves generating detailed answers in the form of paragraphs, which go beyond simple yes/no responses or short factual answers. While existing QA models excel in questions with concise answers, LFQA requires handling multiple topics and their intricate relationships, demanding comprehensive explanations. Previous attempts at LFQA focused on generating long-form answers by utilizing relevant contexts from a corpus, relying solely on the question itself. However, they overlooked the possibility that the question alone might not provide sufficient information to identify the relevant contexts. Additionally, generating detailed long-form answers often entails aggregating knowledge from diverse sources. To address these limitations, we propose an LFQA model with iterative Planning, Retrieval, and Generation. This iterative process continues until a complete answer is generated for the given question. From an extensive experiment on both an open domain and a technical domain QA dataset, we find that our model outperforms the state-of-the-art models on various textual and factual metrics for the LFQA task.
Let the Pretrained Language Models "Imagine" for Short Texts Topic Modeling
Oct 24, 2023



Topic models are one of the compelling methods for discovering latent semantics in a document collection. However, it assumes that a document has sufficient co-occurrence information to be effective. However, in short texts, co-occurrence information is minimal, which results in feature sparsity in document representation. Therefore, existing topic models (probabilistic or neural) mostly fail to mine patterns from them to generate coherent topics. In this paper, we take a new approach to short-text topic modeling to address the data-sparsity issue by extending short text into longer sequences using existing pre-trained language models (PLMs). Besides, we provide a simple solution extending a neural topic model to reduce the effect of noisy out-of-topics text generation from PLMs. We observe that our model can substantially improve the performance of short-text topic modeling. Extensive experiments on multiple real-world datasets under extreme data sparsity scenarios show that our models can generate high-quality topics outperforming state-of-the-art models.
TopicAdapt- An Inter-Corpora Topics Adaptation Approach
Oct 08, 2023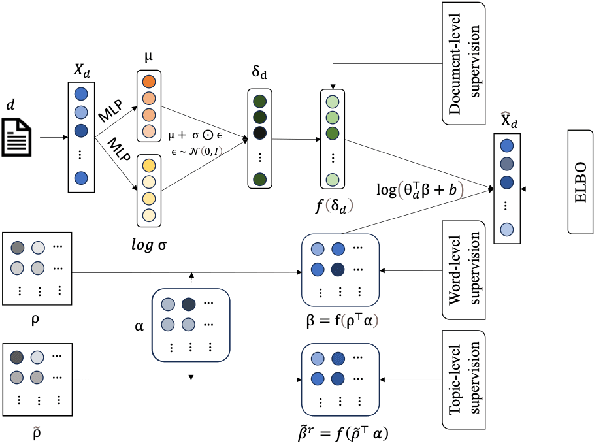
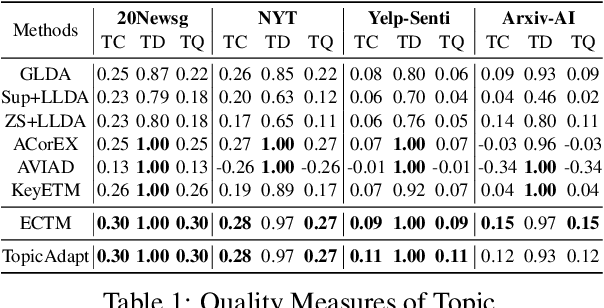
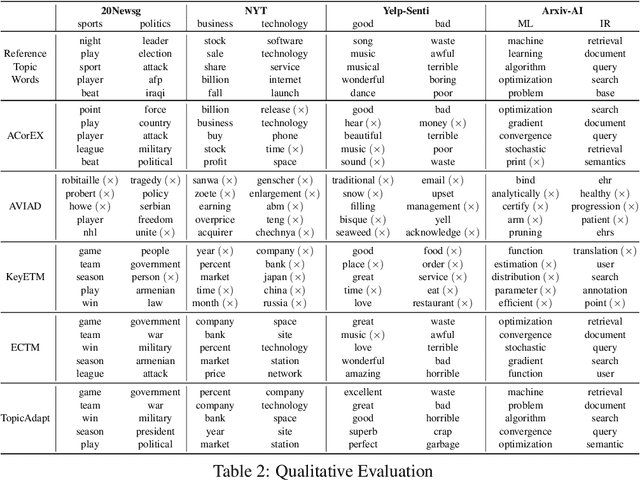

Topic models are popular statistical tools for detecting latent semantic topics in a text corpus. They have been utilized in various applications across different fields. However, traditional topic models have some limitations, including insensitivity to user guidance, sensitivity to the amount and quality of data, and the inability to adapt learned topics from one corpus to another. To address these challenges, this paper proposes a neural topic model, TopicAdapt, that can adapt relevant topics from a related source corpus and also discover new topics in a target corpus that are absent in the source corpus. The proposed model offers a promising approach to improve topic modeling performance in practical scenarios. Experiments over multiple datasets from diverse domains show the superiority of the proposed model against the state-of-the-art topic models.