 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTRAG-UN: A Benchmark for Open Challenges in Multi-Turn RAG Conversations
Feb 26, 2026We present MTRAG-UN, a benchmark for exploring open challenges in multi-turn retrieval augmented generation, a popular use of large language models. We release a benchmark of 666 tasks containing over 2,800 conversation turns across 6 domains with accompanying corpora. Our experiments show that retrieval and generation models continue to struggle on conversations with UNanswerable, UNderspecified, and NONstandalone questions and UNclear responses. Our benchmark is available at https://github.com/IBM/mt-rag-benchmark
Activated LoRA: Fine-tuned LLMs for Intrinsics
Apr 16, 2025Low-Rank Adaptation (LoRA) has emerged as a highly efficient framework for finetuning the weights of large foundation models, and has become the go-to method for data-driven customization of LLMs. Despite the promise of highly customized behaviors and capabilities, switching between relevant LoRAs in a multiturn setting is highly inefficient, as the key-value (KV) cache of the entire turn history must be recomputed with the LoRA weights before generation can begin. To address this problem, we propose Activated LoRA (aLoRA), which modifies the LoRA framework to only adapt weights for the tokens in the sequence \emph{after} the aLoRA is invoked. This change crucially allows aLoRA to accept the base model's KV cache of the input string, meaning that aLoRA can be instantly activated whenever needed in a chain without recomputing the cache. This enables building what we call \emph{intrinsics}, i.e. highly specialized models invoked to perform well-defined operations on portions of an input chain or conversation that otherwise uses the base model by default. We use aLoRA to train a set of intrinsics models, demonstrating competitive accuracy with standard LoRA while achieving significant inference benefits.
A Library of LLM Intrinsics for Retrieval-Augmented Generation
Apr 16, 2025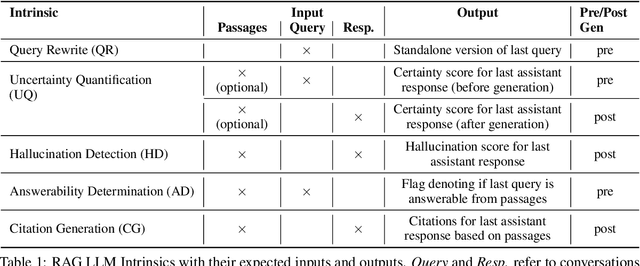
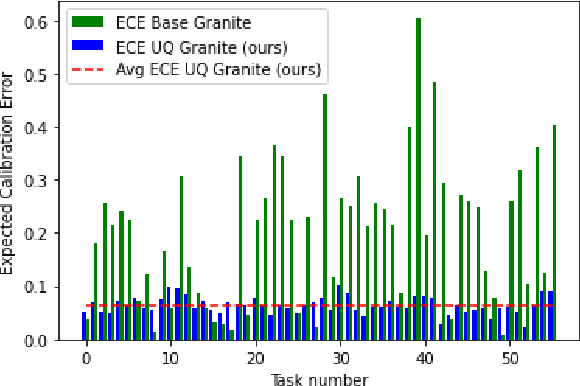

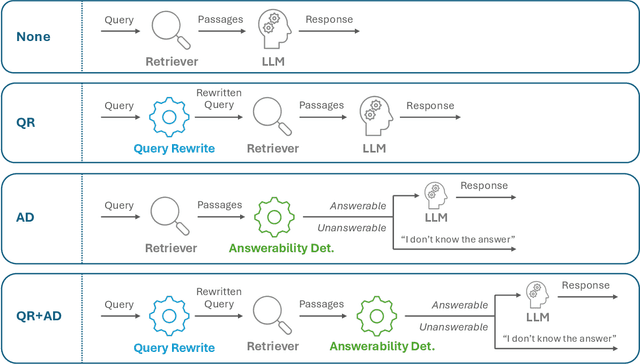
In the developer community for large language models (LLMs), there is not yet a clean pattern analogous to a software library, to support very large scale collaboration. Even for the commonplace use case of Retrieval-Augmented Generation (RAG), it is not currently possible to write a RAG application against a well-defined set of APIs that are agreed upon by different LLM providers. Inspired by the idea of compiler intrinsics, we propose some elements of such a concept through introducing a library of LLM Intrinsics for RAG. An LLM intrinsic is defined as a capability that can be invoked through a well-defined API that is reasonably stable and independent of how the LLM intrinsic itself is implemented. The intrinsics in our library are released as LoRA adapters on HuggingFace, and through a software interface with clear structured input/output characteristics on top of vLLM as an inference platform, accompanied in both places with documentation and code. This article describes the intended usage, training details, and evaluations for each intrinsic, as well as compositions of multiple intrinsics.
MTRAG: A Multi-Turn Conversational Benchmark for Evaluating Retrieval-Augmented Generation Systems
Jan 07, 2025



Retrieval-augmented generation (RAG) has recently become a very popular task for Large Language Models (LLMs). Evaluating them on multi-turn RAG conversations, where the system is asked to generate a response to a question in the context of a preceding conversation is an important and often overlooked task with several additional challenges. We present MTRAG: an end-to-end human-generated multi-turn RAG benchmark that reflects several real-world properties across diverse dimensions for evaluating the full RAG pipeline. MTRAG contains 110 conversations averaging 7.7 turns each across four domains for a total of 842 tasks. We also explore automation paths via synthetic data and LLM-as-a-Judge evaluation. Our human and automatic evaluations show that even state-of-the-art LLM RAG systems struggle on MTRAG. We demonstrate the need for strong retrieval and generation systems that can handle later turns, unanswerable questions, non-standalone questions, and multiple domains. MTRAG is available at https://github.com/ibm/mt-rag-benchmark.
DELIFT: Data Efficient Language model Instruction Fine Tuning
Nov 07, 2024Fine-tuning large language models (LLMs) is essential for enhancing their performance on specific tasks but is often resource-intensive due to redundant or uninformative data. To address this inefficiency, we introduce DELIFT (Data Efficient Language model Instruction Fine-Tuning), a novel algorithm that systematically optimizes data selection across the three key stages of fine-tuning: (1) instruction tuning, (2) task-specific fine-tuning (e.g., reasoning, question-answering), and (3) continual fine-tuning (e.g., incorporating new data versions). Unlike existing methods that focus on single-stage optimization or rely on computationally intensive gradient calculations, DELIFT operates efficiently across all stages. Central to our approach is a pairwise utility metric that quantifies how beneficial a data sample is for improving the model's responses to other samples, effectively measuring the informational value relative to the model's current capabilities. By leveraging different submodular functions applied to this metric, DELIFT selects diverse and optimal subsets that are useful across all stages of fine-tuning. Experiments across various tasks and model scales demonstrate that DELIFT can reduce the fine-tuning data size by up to 70% without compromising performance, offering significant computational savings and outperforming existing methods in both efficiency and efficacy.
ConTReGen: Context-driven Tree-structured Retrieval for Open-domain Long-form Text Generation
Oct 20, 2024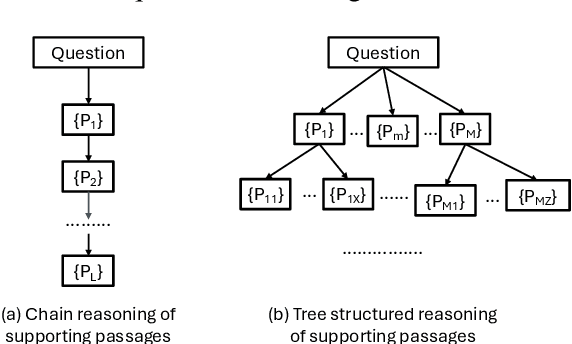



Open-domain long-form text generation requires generating coherent, comprehensive responses that address complex queries with both breadth and depth. This task is challenging due to the need to accurately capture diverse facets of input queries. Existing iterative retrieval-augmented generation (RAG) approaches often struggle to delve deeply into each facet of complex queries and integrate knowledge from various sources effectively. This paper introduces ConTReGen, a novel framework that employs a context-driven, tree-structured retrieval approach to enhance the depth and relevance of retrieved content. ConTReGen integrates a hierarchical, top-down in-depth exploration of query facets with a systematic bottom-up synthesis, ensuring comprehensive coverage and coherent integration of multifaceted information. Extensive experiments on multiple datasets, including LFQA and ODSUM, alongside a newly introduced dataset, ODSUM-WikiHow, demonstrate that ConTReGen outperforms existing state-of-the-art RAG models.
Seed-Guided Fine-Grained Entity Typing in Science and Engineering Domains
Jan 23, 2024



Accurately typing entity mentions from text segments is a fundamental task for various natural language processing applications. Many previous approaches rely on massive human-annotated data to perform entity typing. Nevertheless, collecting such data in highly specialized science and engineering domains (e.g., software engineering and security) can be time-consuming and costly, without mentioning the domain gaps between training and inference data if the model needs to be applied to confidential datasets. In this paper, we study the task of seed-guided fine-grained entity typing in science and engineering domains, which takes the name and a few seed entities for each entity type as the only supervision and aims to classify new entity mentions into both seen and unseen types (i.e., those without seed entities). To solve this problem, we propose SEType which first enriches the weak supervision by finding more entities for each seen type from an unlabeled corpus using the contextualized representations of pre-trained language models. It then matches the enriched entities to unlabeled text to get pseudo-labeled samples and trains a textual entailment model that can make inferences for both seen and unseen types. Extensive experiments on two datasets covering four domains demonstrate the effectiveness of SEType in comparison with various baselines.
Long-form Question Answering: An Iterative Planning-Retrieval-Generation Approach
Nov 15, 2023Long-form question answering (LFQA) poses a challenge as it involves generating detailed answers in the form of paragraphs, which go beyond simple yes/no responses or short factual answers. While existing QA models excel in questions with concise answers, LFQA requires handling multiple topics and their intricate relationships, demanding comprehensive explanations. Previous attempts at LFQA focused on generating long-form answers by utilizing relevant contexts from a corpus, relying solely on the question itself. However, they overlooked the possibility that the question alone might not provide sufficient information to identify the relevant contexts. Additionally, generating detailed long-form answers often entails aggregating knowledge from diverse sources. To address these limitations, we propose an LFQA model with iterative Planning, Retrieval, and Generation. This iterative process continues until a complete answer is generated for the given question. From an extensive experiment on both an open domain and a technical domain QA dataset, we find that our model outperforms the state-of-the-art models on various textual and factual metrics for the LFQA task.
Beyond Labels: Empowering Human with Natural Language Explanations through a Novel Active-Learning Architecture
May 22, 2023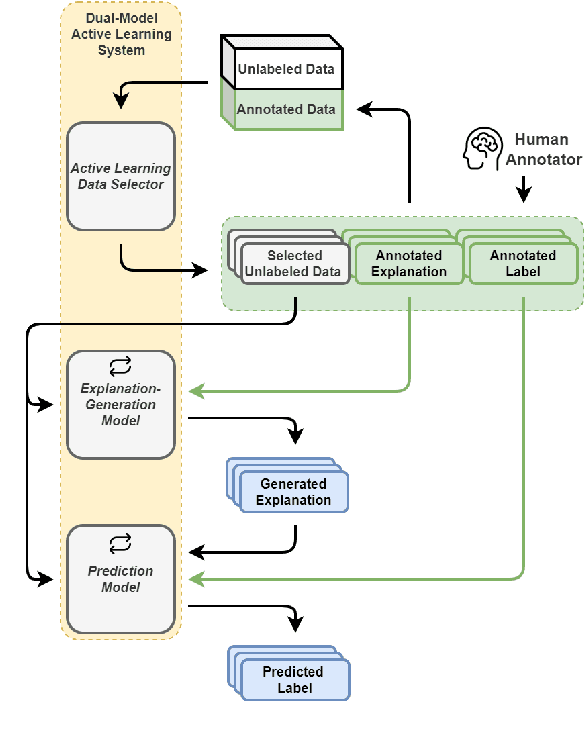
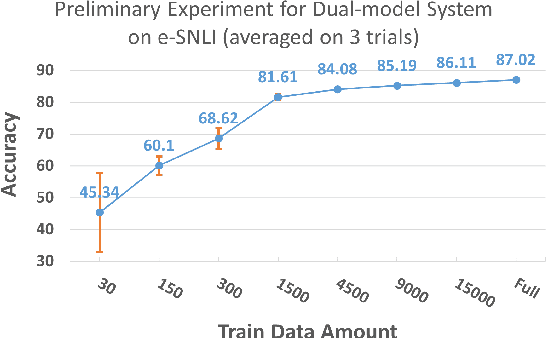

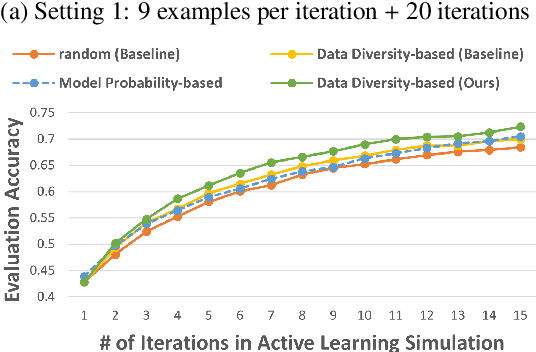
Data annotation is a costly task; thus, researchers have proposed low-scenario learning techniques like Active-Learning (AL) to support human annotators; Yet, existing AL works focus only on the label, but overlook the natural language explanation of a data point, despite that real-world humans (e.g., doctors) often need both the labels and the corresponding explanations at the same time. This work proposes a novel AL architecture to support and reduce human annotations of both labels and explanations in low-resource scenarios. Our AL architecture incorporates an explanation-generation model that can explicitly generate natural language explanations for the prediction model and for assisting humans' decision-making in real-world. For our AL framework, we design a data diversity-based AL data selection strategy that leverages the explanation annotations. The automated AL simulation evaluations demonstrate that our data selection strategy consistently outperforms traditional data diversity-based strategy; furthermore, human evaluation demonstrates that humans prefer our generated explanations to the SOTA explanation-generation system.
Are Human Explanations Always Helpful? Towards Objective Evaluation of Human Natural Language Explanations
May 04, 2023



Human-annotated labels and explanations are critical for training explainable NLP models. However, unlike human-annotated labels whose quality is easier to calibrate (e.g., with a majority vote), human-crafted free-form explanations can be quite subjective, as some recent works have discussed. Before blindly using them as ground truth to train ML models, a vital question needs to be asked: How do we evaluate a human-annotated explanation's quality? In this paper, we build on the view that the quality of a human-annotated explanation can be measured based on its helpfulness (or impairment) to the ML models' performance for the desired NLP tasks for which the annotations were collected. In comparison to the commonly used Simulatability score, we define a new metric that can take into consideration the helpfulness of an explanation for model performance at both fine-tuning and inference. With the help of a unified dataset format, we evaluated the proposed metric on five datasets (e.g., e-SNLI) against two model architectures (T5 and BART), and the results show that our proposed metric can objectively evaluate the quality of human-annotated explanations, while Simulatability falls short.