 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACES: Tagging Reasoning Steps for Adaptive Cost-Efficient Early-Stopping
Apr 22, 2026The field of Language Reasoning Models (LRMs) has been very active over the past few years with advances in training and inference techniques enabling LRMs to reason longer, and more accurately. However, a growing body of studies show that LRMs are still inefficient, over-generating verification and reflection steps. Additionally, the high-level role of each reasoning step and how different step types contribute to the generation of correct answers, is largely underexplored. To address this challenge, we introduce TRACES (Tagging of the Reasoning steps enabling Adaptive Cost-Efficient early-Stopping), a lightweight framework that tags reasoning steps in real-time, and enable adaptive, cost-efficient early stopping of large-language-model inferences. Building on this framework we monitor reasoning behaviors during inferences, and we find that LRMs tend to shift their reasoning behavior after reaching a correct answer. We demonstrate that the monitoring of the specific type of steps can produce effective interpretable early stopping criteria. We evaluate the TRACES framework on three mathematical reasoning benchmarks, namely, MATH500, GSM8K, AIME and two knowledge and reasoning benchmarks, MMLU and GPQA respectively. We achieve 20 to 50% token reduction while maintaining comparable accuracy to standard generation.
Breaking MCP with Function Hijacking Attacks: Novel Threats for Function Calling and Agentic Models
Apr 22, 2026The growth of agentic AI has drawn significant attention to function calling Large Language Models (LLMs), which are designed to extend the capabilities of AI-powered system by invoking external functions. Injection and jailbreaking attacks have been extensively explored to showcase the vulnerabilities of LLMs to user prompt manipulation. The expanded capabilities of agentic models introduce further vulnerabilities via their function calling interface. Recent work in LLM security showed that function calling can be abused, leading to data tampering and theft, causing disruptive behavior such as endless loops, or causing LLMs to produce harmful content in the style of jailbreaking attacks. This paper introduces a novel function hijacking attack (FHA) that manipulates the tool selection process of agentic models to force the invocation of a specific, attacker-chosen function. While existing attacks focus on semantic preference of the model for function-calling tasks, we show that FHA is largely agnostic to the context semantics and robust to the function sets, making it applicable across diverse domains. We further demonstrate that FHA can be trained to produce universal adversarial functions, enabling a single attacked function to hijack tool selection across multiple queries and payload configurations. We conducted experiments on 5 different models, including instructed and reasoning variants, reaching 70% to 100% ASR over the established BFCL dataset. Our findings further demonstrate the need for strong guardrails and security modules for agentic systems.
Blue Teaming Function-Calling Agents
Jan 14, 2026We present an experimental evaluation that assesses the robustness of four open source LLMs claiming function-calling capabilities against three different attacks, and we measure the effectiveness of eight different defences. Our results show how these models are not safe by default, and how the defences are not yet employable in real-world scenarios.
Step-Tagging: Toward controlling the generation of Language Reasoning Models through step monitoring
Dec 16, 2025The field of Language Reasoning Models (LRMs) has been very active over the past few years with advances in training and inference techniques enabling LRMs to reason longer, and more accurately. However, a growing body of studies show that LRMs are still inefficient, over-generating verification and reflection steps. To address this challenge, we introduce the Step-Tagging framework, a lightweight sentence-classifier enabling real-time annotation of the type of reasoning steps that an LRM is generating. To monitor reasoning behaviors, we introduced ReasonType: a novel taxonomy of reasoning steps. Building on this framework, we demonstrated that online monitoring of the count of specific steps can produce effective interpretable early stopping criteria of LRM inferences. We evaluate the Step-tagging framework on three open-source reasoning models across standard benchmark datasets: MATH500, GSM8K, AIME and non-mathematical tasks (GPQA and MMLU-Pro). We achieve 20 to 50\% token reduction while maintaining comparable accuracy to standard generation, with largest gains observed on more computation-heavy tasks. This work offers a novel way to increase control over the generation of LRMs, and a new tool to study behaviors of LRMs.
Pre-Hoc Predictions in AutoML: Leveraging LLMs to Enhance Model Selection and Benchmarking for Tabular datasets
Oct 02, 2025The field of AutoML has made remarkable progress in post-hoc model selection, with libraries capable of automatically identifying the most performing models for a given dataset. Nevertheless, these methods often rely on exhaustive hyperparameter searches, where methods automatically train and test different types of models on the target dataset. Contrastingly, pre-hoc prediction emerges as a promising alternative, capable of bypassing exhaustive search through intelligent pre-selection of models. Despite its potential, pre-hoc prediction remains under-explored in the literature. This paper explores the intersection of AutoML and pre-hoc model selection by leveraging traditional models and Large Language Model (LLM) agents to reduce the search space of AutoML libraries. By relying on dataset descriptions and statistical information, we reduce the AutoML search space. Our methodology is applied to the AWS AutoGluon portfolio dataset, a state-of-the-art AutoML benchmark containing 175 tabular classification datasets available on OpenML. The proposed approach offers a shift in AutoML workflows, significantly reducing computational overhead, while still selecting the best model for the given dataset.
Activated LoRA: Fine-tuned LLMs for Intrinsics
Apr 16, 2025Low-Rank Adaptation (LoRA) has emerged as a highly efficient framework for finetuning the weights of large foundation models, and has become the go-to method for data-driven customization of LLMs. Despite the promise of highly customized behaviors and capabilities, switching between relevant LoRAs in a multiturn setting is highly inefficient, as the key-value (KV) cache of the entire turn history must be recomputed with the LoRA weights before generation can begin. To address this problem, we propose Activated LoRA (aLoRA), which modifies the LoRA framework to only adapt weights for the tokens in the sequence \emph{after} the aLoRA is invoked. This change crucially allows aLoRA to accept the base model's KV cache of the input string, meaning that aLoRA can be instantly activated whenever needed in a chain without recomputing the cache. This enables building what we call \emph{intrinsics}, i.e. highly specialized models invoked to perform well-defined operations on portions of an input chain or conversation that otherwise uses the base model by default. We use aLoRA to train a set of intrinsics models, demonstrating competitive accuracy with standard LoRA while achieving significant inference benefits.
MAD-MAX: Modular And Diverse Malicious Attack MiXtures for Automated LLM Red Teaming
Mar 08, 2025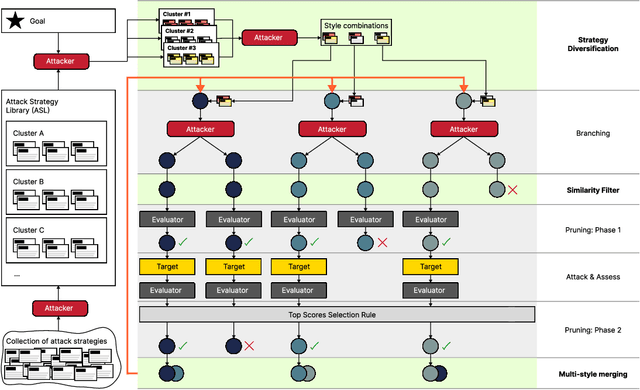
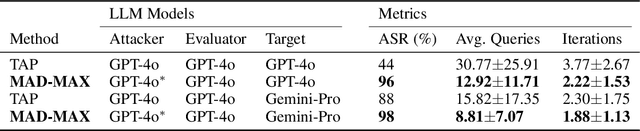
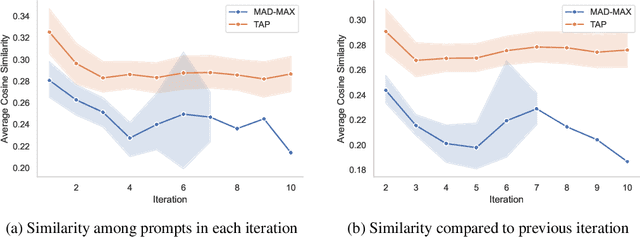
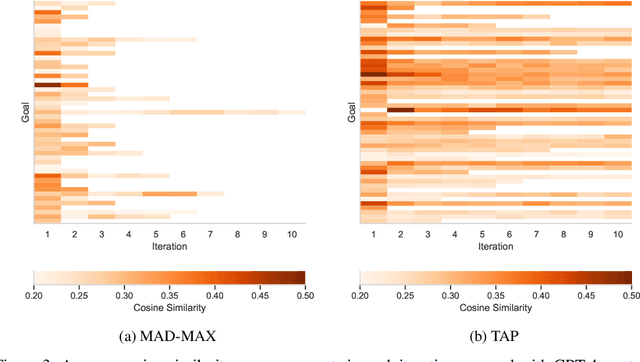
With LLM usage rapidly increasing, their vulnerability to jailbreaks that create harmful outputs are a major security risk. As new jailbreaking strategies emerge and models are changed by fine-tuning, continuous testing for security vulnerabilities is necessary. Existing Red Teaming methods fall short in cost efficiency, attack success rate, attack diversity, or extensibility as new attack types emerge. We address these challenges with Modular And Diverse Malicious Attack MiXtures (MAD-MAX) for Automated LLM Red Teaming. MAD-MAX uses automatic assignment of attack strategies into relevant attack clusters, chooses the most relevant clusters for a malicious goal, and then combines strategies from the selected clusters to achieve diverse novel attacks with high attack success rates. MAD-MAX further merges promising attacks together at each iteration of Red Teaming to boost performance and introduces a similarity filter to prune out similar attacks for increased cost efficiency. The MAD-MAX approach is designed to be easily extensible with newly discovered attack strategies and outperforms the prominent Red Teaming method Tree of Attacks with Pruning (TAP) significantly in terms of Attack Success Rate (ASR) and queries needed to achieve jailbreaks. MAD-MAX jailbreaks 97% of malicious goals in our benchmarks on GPT-4o and Gemini-Pro compared to TAP with 66%. MAD-MAX does so with only 10.9 average queries to the target LLM compared to TAP with 23.3. WARNING: This paper contains contents which are offensive in nature.
Adversarial Prompt Evaluation: Systematic Benchmarking of Guardrails Against Prompt Input Attacks on LLMs
Feb 21, 2025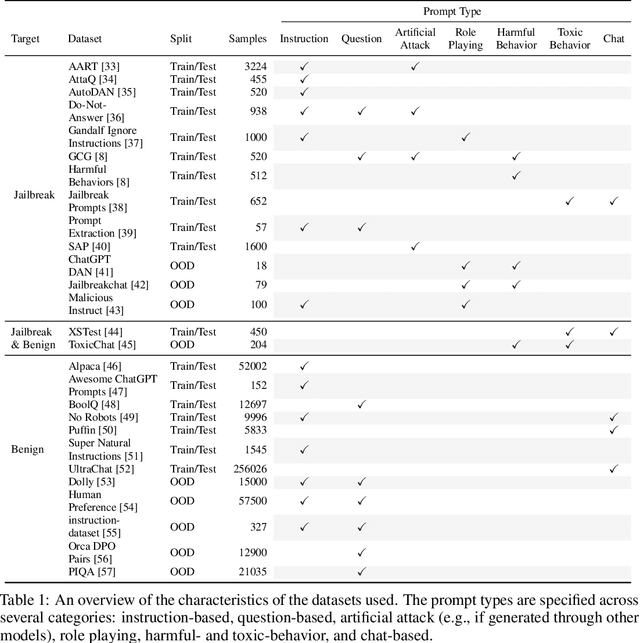
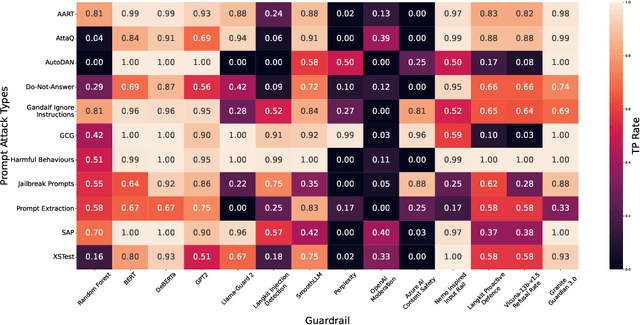
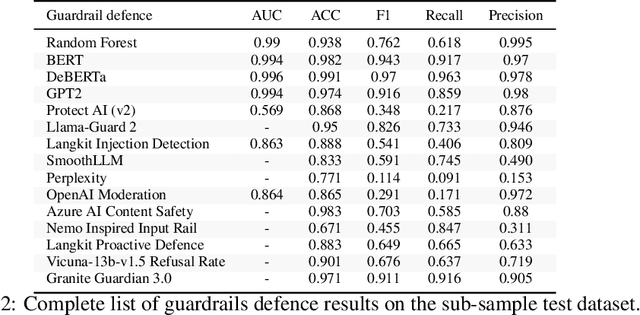
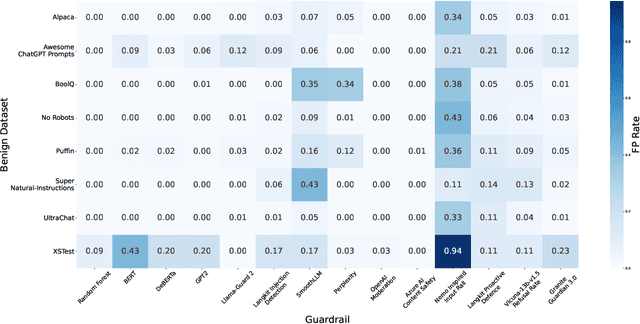
As large language models (LLMs) become integrated into everyday applications, ensuring their robustness and security is increasingly critical. In particular, LLMs can be manipulated into unsafe behaviour by prompts known as jailbreaks. The variety of jailbreak styles is growing, necessitating the use of external defences known as guardrails. While many jailbreak defences have been proposed, not all defences are able to handle new out-of-distribution attacks due to the narrow segment of jailbreaks used to align them. Moreover, the lack of systematisation around defences has created significant gaps in their practical application. In this work, we perform systematic benchmarking across 15 different defences, considering a broad swathe of malicious and benign datasets. We find that there is significant performance variation depending on the style of jailbreak a defence is subject to. Additionally, we show that based on current datasets available for evaluation, simple baselines can display competitive out-of-distribution performance compared to many state-of-the-art defences. Code is available at https://github.com/IBM/Adversarial-Prompt-Evaluation.
Granite Guardian
Dec 10, 2024



We introduce the Granite Guardian models, a suite of safeguards designed to provide risk detection for prompts and responses, enabling safe and responsible use in combination with any large language model (LLM). These models offer comprehensive coverage across multiple risk dimensions, including social bias, profanity, violence, sexual content, unethical behavior, jailbreaking, and hallucination-related risks such as context relevance, groundedness, and answer relevance for retrieval-augmented generation (RAG). Trained on a unique dataset combining human annotations from diverse sources and synthetic data, Granite Guardian models address risks typically overlooked by traditional risk detection models, such as jailbreaks and RAG-specific issues. With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. Released as open-source, Granite Guardian aims to promote responsible AI development across the community. https://github.com/ibm-granite/granite-guardian
HarmLevelBench: Evaluating Harm-Level Compliance and the Impact of Quantization on Model Alignment
Nov 11, 2024With the introduction of the transformers architecture, LLMs have revolutionized the NLP field with ever more powerful models. Nevertheless, their development came up with several challenges. The exponential growth in computational power and reasoning capabilities of language models has heightened concerns about their security. As models become more powerful, ensuring their safety has become a crucial focus in research. This paper aims to address gaps in the current literature on jailbreaking techniques and the evaluation of LLM vulnerabilities. Our contributions include the creation of a novel dataset designed to assess the harmfulness of model outputs across multiple harm levels, as well as a focus on fine-grained harm-level analysis. Using this framework, we provide a comprehensive benchmark of state-of-the-art jailbreaking attacks, specifically targeting the Vicuna 13B v1.5 model. Additionally, we examine how quantization techniques, such as AWQ and GPTQ, influence the alignment and robustness of models, revealing trade-offs between enhanced robustness with regards to transfer attacks and potential increases in vulnerability on direct ones. This study aims to demonstrate the influence of harmful input queries on the complexity of jailbreaking techniques, as well as to deepen our understanding of LLM vulnerabilities and improve methods for assessing model robustness when confronted with harmful content, particularly in the context of compression strategies.