 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlue Teaming Function-Calling Agents
Jan 14, 2026We present an experimental evaluation that assesses the robustness of four open source LLMs claiming function-calling capabilities against three different attacks, and we measure the effectiveness of eight different defences. Our results show how these models are not safe by default, and how the defences are not yet employable in real-world scenarios.
Clutch Control: An Attention-based Combinatorial Bandit for Efficient Mutation in JavaScript Engine Fuzzing
Oct 14, 2025JavaScript engines are widely used in web browsers, PDF readers, and server-side applications. The rise in concern over their security has led to the development of several targeted fuzzing techniques. However, existing approaches use random selection to determine where to perform mutations in JavaScript code. We postulate that the problem of selecting better mutation targets is suitable for combinatorial bandits with a volatile number of arms. Thus, we propose CLUTCH, a novel deep combinatorial bandit that can observe variable length JavaScript test case representations, using an attention mechanism from deep learning. Furthermore, using Concrete Dropout, CLUTCH can dynamically adapt its exploration. We show that CLUTCH increases efficiency in JavaScript fuzzing compared to three state-of-the-art solutions by increasing the number of valid test cases and coverage-per-testcase by, respectively, 20.3% and 8.9% on average. In volatile and combinatorial settings we show that CLUTCH outperforms state-of-the-art bandits, achieving at least 78.1% and 4.1% less regret in volatile and combinatorial settings, respectively.
KnowML: Improving Generalization of ML-NIDS with Attack Knowledge Graphs
Jun 24, 2025Despite extensive research on Machine Learning-based Network Intrusion Detection Systems (ML-NIDS), their capability to detect diverse attack variants remains uncertain. Prior studies have largely relied on homogeneous datasets, which artificially inflate performance scores and offer a false sense of security. Designing systems that can effectively detect a wide range of attack variants remains a significant challenge. The progress of ML-NIDS continues to depend heavily on human expertise, which can embed subjective judgments of system designers into the model, potentially hindering its ability to generalize across diverse attack types. To address this gap, we propose KnowML, a framework for knowledge-guided machine learning that integrates attack knowledge into ML-NIDS. KnowML systematically explores the threat landscape by leveraging Large Language Models (LLMs) to perform automated analysis of attack implementations. It constructs a unified Knowledge Graph (KG) of attack strategies, on which it applies symbolic reasoning to generate KG-Augmented Input, embedding domain knowledge directly into the design process of ML-NIDS. We evaluate KnowML on 28 realistic attack variants, of which 10 are newly collected for this study. Our findings reveal that baseline ML-NIDS models fail to detect several variants entirely, achieving F1 scores as low as 0 %. In contrast, our knowledge-guided approach achieves up to 99 % F1 score while maintaining a False Positive Rate below 0.1 %.
Detecting APT Malware Command and Control over HTTP(S) Using Contextual Summaries
Feb 07, 2025Advanced Persistent Threats (APTs) are among the most sophisticated threats facing critical organizations worldwide. APTs employ specific tactics, techniques, and procedures (TTPs) which make them difficult to detect in comparison to frequent and aggressive attacks. In fact, current network intrusion detection systems struggle to detect APTs communications, allowing such threats to persist unnoticed on victims' machines for months or even years. In this paper, we present EarlyCrow, an approach to detect APT malware command and control over HTTP(S) using contextual summaries. The design of EarlyCrow is informed by a novel threat model focused on TTPs present in traffic generated by tools recently used as part of APT campaigns. The threat model highlights the importance of the context around the malicious connections, and suggests traffic attributes which help APT detection. EarlyCrow defines a novel multipurpose network flow format called PairFlow, which is leveraged to build the contextual summary of a PCAP capture, representing key behavioral, statistical and protocol information relevant to APT TTPs. We evaluate the effectiveness of EarlyCrow on unseen APTs obtaining a headline macro average F1-score of 93.02% with FPR of $0.74%.
APIRL: Deep Reinforcement Learning for REST API Fuzzing
Dec 20, 2024REST APIs have become key components of web services. However, they often contain logic flaws resulting in server side errors or security vulnerabilities. HTTP requests are used as test cases to find and mitigate such issues. Existing methods to modify requests, including those using deep learning, suffer from limited performance and precision, relying on undirected search or making limited usage of the contextual information. In this paper we propose APIRL, a fully automated deep reinforcement learning tool for testing REST APIs. A key novelty of our approach is the use of feedback from a transformer module pre-trained on JSON-structured data, akin to that used in API responses. This allows APIRL to learn the subtleties relating to test outcomes, and generalise to unseen API endpoints. We show APIRL can find significantly more bugs than the state-of-the-art in real world REST APIs while minimising the number of required test cases. We also study how reward functions, and other key design choices, affect learnt policies in a thorough ablation study.
Helping LLMs Improve Code Generation Using Feedback from Testing and Static Analysis
Dec 19, 2024
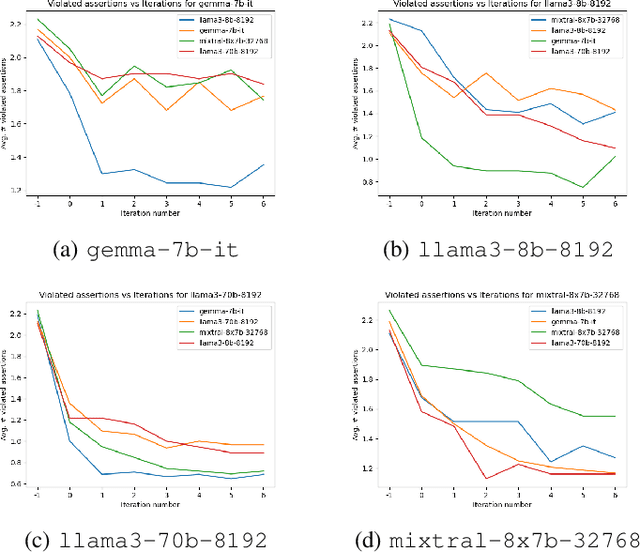
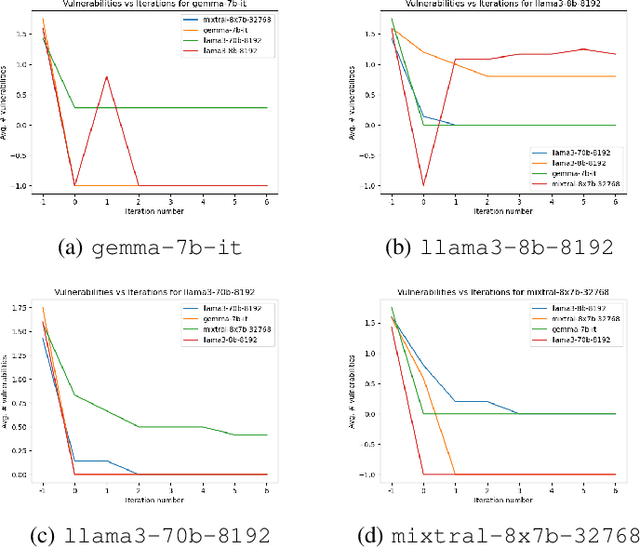

Large Language Models (LLMs) are one of the most promising developments in the field of artificial intelligence, and the software engineering community has readily noticed their potential role in the software development life-cycle. Developers routinely ask LLMs to generate code snippets, increasing productivity but also potentially introducing ownership, privacy, correctness, and security issues. Previous work highlighted how code generated by mainstream commercial LLMs is often not safe, containing vulnerabilities, bugs, and code smells. In this paper, we present a framework that leverages testing and static analysis to assess the quality, and guide the self-improvement, of code generated by general-purpose, open-source LLMs. First, we ask LLMs to generate C code to solve a number of programming tasks. Then we employ ground-truth tests to assess the (in)correctness of the generated code, and a static analysis tool to detect potential safety vulnerabilities. Next, we assess the models ability to evaluate the generated code, by asking them to detect errors and vulnerabilities. Finally, we test the models ability to fix the generated code, providing the reports produced during the static analysis and incorrectness evaluation phases as feedback. Our results show that models often produce incorrect code, and that the generated code can include safety issues. Moreover, they perform very poorly at detecting either issue. On the positive side, we observe a substantial ability to fix flawed code when provided with information about failed tests or potential vulnerabilities, indicating a promising avenue for improving the safety of LLM-based code generation tools.
HarmLevelBench: Evaluating Harm-Level Compliance and the Impact of Quantization on Model Alignment
Nov 11, 2024With the introduction of the transformers architecture, LLMs have revolutionized the NLP field with ever more powerful models. Nevertheless, their development came up with several challenges. The exponential growth in computational power and reasoning capabilities of language models has heightened concerns about their security. As models become more powerful, ensuring their safety has become a crucial focus in research. This paper aims to address gaps in the current literature on jailbreaking techniques and the evaluation of LLM vulnerabilities. Our contributions include the creation of a novel dataset designed to assess the harmfulness of model outputs across multiple harm levels, as well as a focus on fine-grained harm-level analysis. Using this framework, we provide a comprehensive benchmark of state-of-the-art jailbreaking attacks, specifically targeting the Vicuna 13B v1.5 model. Additionally, we examine how quantization techniques, such as AWQ and GPTQ, influence the alignment and robustness of models, revealing trade-offs between enhanced robustness with regards to transfer attacks and potential increases in vulnerability on direct ones. This study aims to demonstrate the influence of harmful input queries on the complexity of jailbreaking techniques, as well as to deepen our understanding of LLM vulnerabilities and improve methods for assessing model robustness when confronted with harmful content, particularly in the context of compression strategies.
Differentially Private and Adversarially Robust Machine Learning: An Empirical Evaluation
Jan 18, 2024


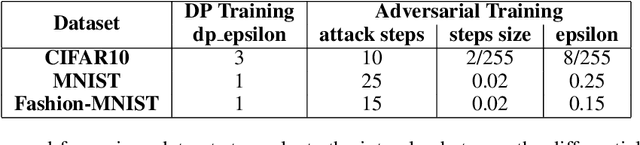
Malicious adversaries can attack machine learning models to infer sensitive information or damage the system by launching a series of evasion attacks. Although various work addresses privacy and security concerns, they focus on individual defenses, but in practice, models may undergo simultaneous attacks. This study explores the combination of adversarial training and differentially private training to defend against simultaneous attacks. While differentially-private adversarial training, as presented in DP-Adv, outperforms the other state-of-the-art methods in performance, it lacks formal privacy guarantees and empirical validation. Thus, in this work, we benchmark the performance of this technique using a membership inference attack and empirically show that the resulting approach is as private as non-robust private models. This work also highlights the need to explore privacy guarantees in dynamic training paradigms.
Elevating Defenses: Bridging Adversarial Training and Watermarking for Model Resilience
Jan 07, 2024Machine learning models are being used in an increasing number of critical applications; thus, securing their integrity and ownership is critical. Recent studies observed that adversarial training and watermarking have a conflicting interaction. This work introduces a novel framework to integrate adversarial training with watermarking techniques to fortify against evasion attacks and provide confident model verification in case of intellectual property theft. We use adversarial training together with adversarial watermarks to train a robust watermarked model. The key intuition is to use a higher perturbation budget to generate adversarial watermarks compared to the budget used for adversarial training, thus avoiding conflict. We use the MNIST and Fashion-MNIST datasets to evaluate our proposed technique on various model stealing attacks. The results obtained consistently outperform the existing baseline in terms of robustness performance and further prove the resilience of this defense against pruning and fine-tuning removal attacks.
VulBERTa: Simplified Source Code Pre-Training for Vulnerability Detection
May 25, 2022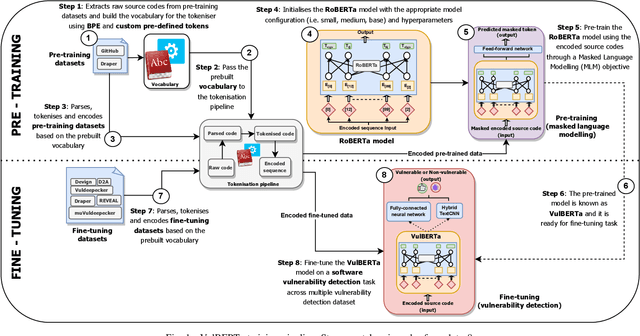

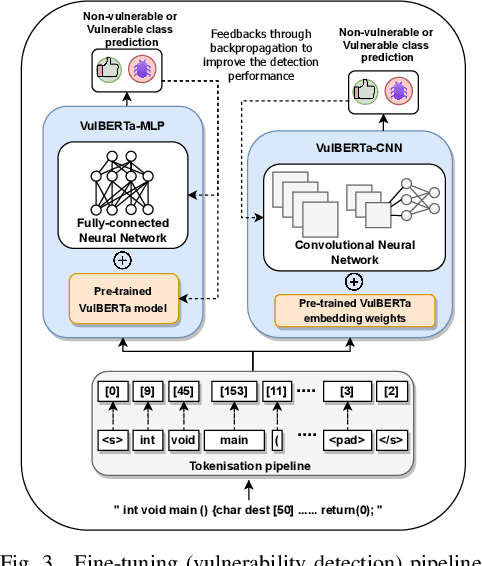
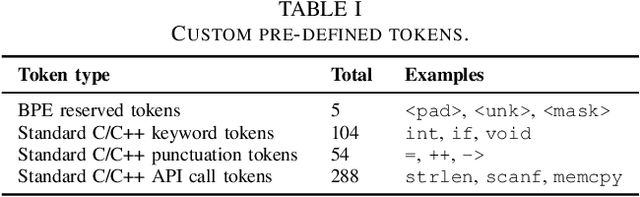
This paper presents VulBERTa, a deep learning approach to detect security vulnerabilities in source code. Our approach pre-trains a RoBERTa model with a custom tokenisation pipeline on real-world code from open-source C/C++ projects. The model learns a deep knowledge representation of the code syntax and semantics, which we leverage to train vulnerability detection classifiers. We evaluate our approach on binary and multi-class vulnerability detection tasks across several datasets (Vuldeepecker, Draper, REVEAL and muVuldeepecker) and benchmarks (CodeXGLUE and D2A). The evaluation results show that VulBERTa achieves state-of-the-art performance and outperforms existing approaches across different datasets, despite its conceptual simplicity, and limited cost in terms of size of training data and number of model parameters.