 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertified Federated Adversarial Training
Paper and Code
Dec 20, 2021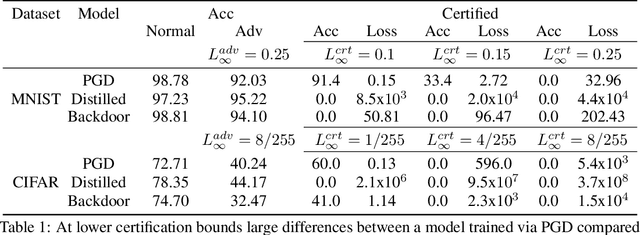
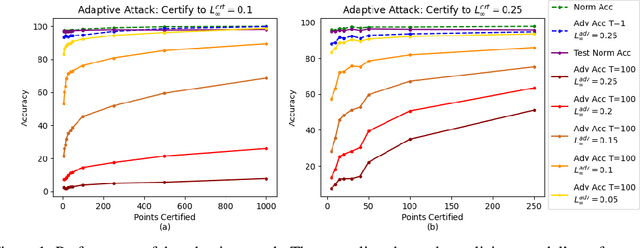
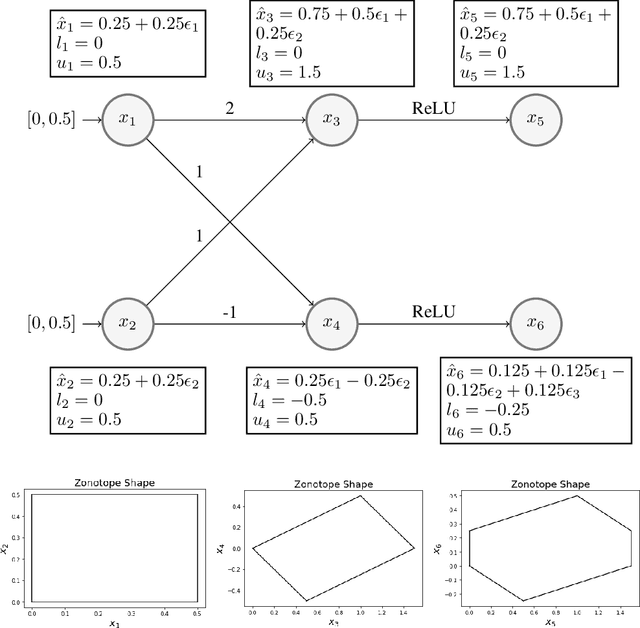
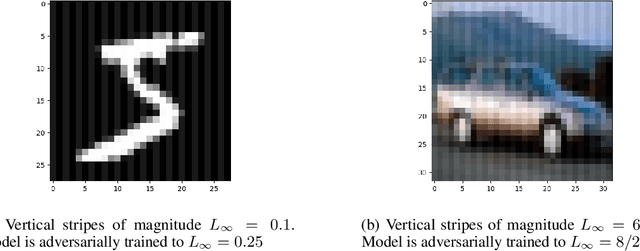
In federated learning (FL), robust aggregation schemes have been developed to protect against malicious clients. Many robust aggregation schemes rely on certain numbers of benign clients being present in a quorum of workers. This can be hard to guarantee when clients can join at will, or join based on factors such as idle system status, and connected to power and WiFi. We tackle the scenario of securing FL systems conducting adversarial training when a quorum of workers could be completely malicious. We model an attacker who poisons the model to insert a weakness into the adversarial training such that the model displays apparent adversarial robustness, while the attacker can exploit the inserted weakness to bypass the adversarial training and force the model to misclassify adversarial examples. We use abstract interpretation techniques to detect such stealthy attacks and block the corrupted model updates. We show that this defence can preserve adversarial robustness even against an adaptive attacker.