 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivated LoRA: Fine-tuned LLMs for Intrinsics
Apr 16, 2025Low-Rank Adaptation (LoRA) has emerged as a highly efficient framework for finetuning the weights of large foundation models, and has become the go-to method for data-driven customization of LLMs. Despite the promise of highly customized behaviors and capabilities, switching between relevant LoRAs in a multiturn setting is highly inefficient, as the key-value (KV) cache of the entire turn history must be recomputed with the LoRA weights before generation can begin. To address this problem, we propose Activated LoRA (aLoRA), which modifies the LoRA framework to only adapt weights for the tokens in the sequence \emph{after} the aLoRA is invoked. This change crucially allows aLoRA to accept the base model's KV cache of the input string, meaning that aLoRA can be instantly activated whenever needed in a chain without recomputing the cache. This enables building what we call \emph{intrinsics}, i.e. highly specialized models invoked to perform well-defined operations on portions of an input chain or conversation that otherwise uses the base model by default. We use aLoRA to train a set of intrinsics models, demonstrating competitive accuracy with standard LoRA while achieving significant inference benefits.
MAD-MAX: Modular And Diverse Malicious Attack MiXtures for Automated LLM Red Teaming
Mar 08, 2025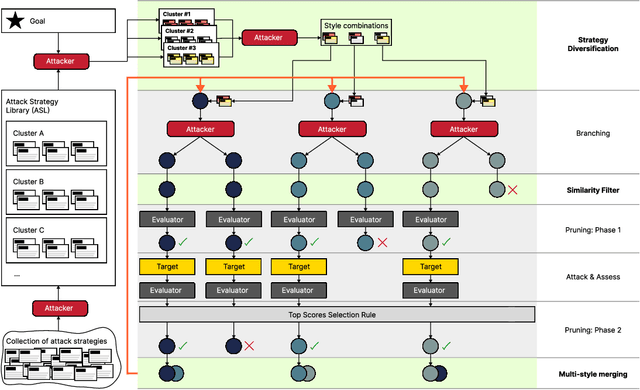
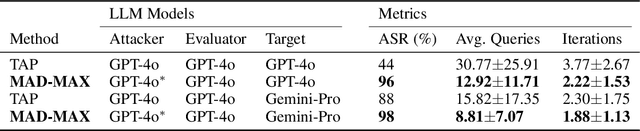
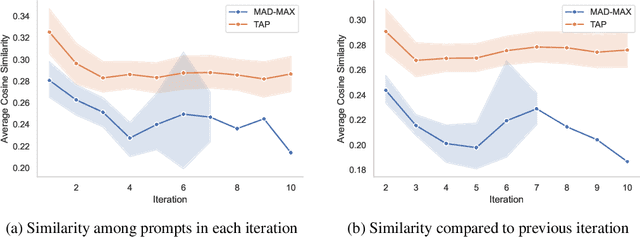
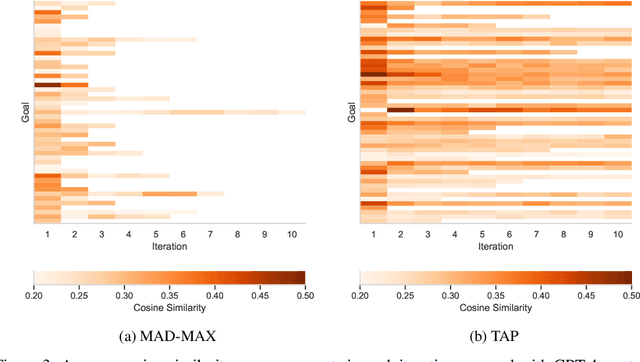
With LLM usage rapidly increasing, their vulnerability to jailbreaks that create harmful outputs are a major security risk. As new jailbreaking strategies emerge and models are changed by fine-tuning, continuous testing for security vulnerabilities is necessary. Existing Red Teaming methods fall short in cost efficiency, attack success rate, attack diversity, or extensibility as new attack types emerge. We address these challenges with Modular And Diverse Malicious Attack MiXtures (MAD-MAX) for Automated LLM Red Teaming. MAD-MAX uses automatic assignment of attack strategies into relevant attack clusters, chooses the most relevant clusters for a malicious goal, and then combines strategies from the selected clusters to achieve diverse novel attacks with high attack success rates. MAD-MAX further merges promising attacks together at each iteration of Red Teaming to boost performance and introduces a similarity filter to prune out similar attacks for increased cost efficiency. The MAD-MAX approach is designed to be easily extensible with newly discovered attack strategies and outperforms the prominent Red Teaming method Tree of Attacks with Pruning (TAP) significantly in terms of Attack Success Rate (ASR) and queries needed to achieve jailbreaks. MAD-MAX jailbreaks 97% of malicious goals in our benchmarks on GPT-4o and Gemini-Pro compared to TAP with 66%. MAD-MAX does so with only 10.9 average queries to the target LLM compared to TAP with 23.3. WARNING: This paper contains contents which are offensive in nature.
Adversarial Prompt Evaluation: Systematic Benchmarking of Guardrails Against Prompt Input Attacks on LLMs
Feb 21, 2025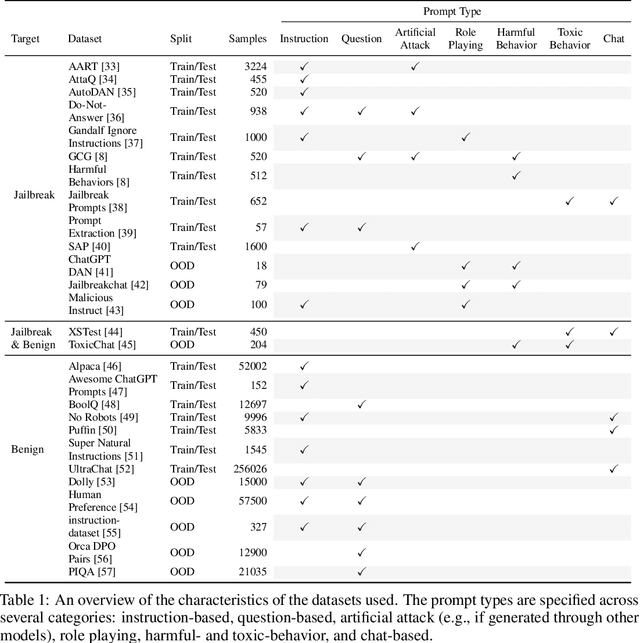
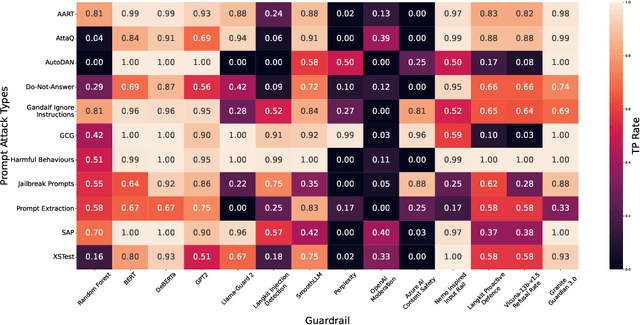
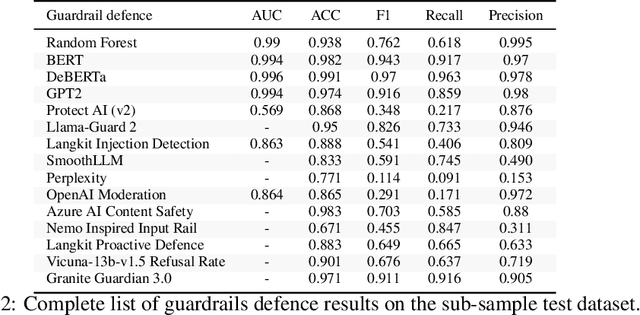
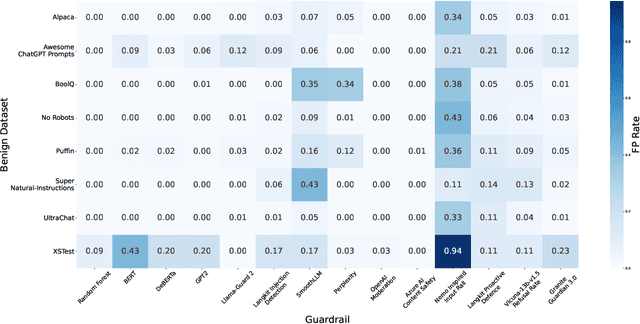
As large language models (LLMs) become integrated into everyday applications, ensuring their robustness and security is increasingly critical. In particular, LLMs can be manipulated into unsafe behaviour by prompts known as jailbreaks. The variety of jailbreak styles is growing, necessitating the use of external defences known as guardrails. While many jailbreak defences have been proposed, not all defences are able to handle new out-of-distribution attacks due to the narrow segment of jailbreaks used to align them. Moreover, the lack of systematisation around defences has created significant gaps in their practical application. In this work, we perform systematic benchmarking across 15 different defences, considering a broad swathe of malicious and benign datasets. We find that there is significant performance variation depending on the style of jailbreak a defence is subject to. Additionally, we show that based on current datasets available for evaluation, simple baselines can display competitive out-of-distribution performance compared to many state-of-the-art defences. Code is available at https://github.com/IBM/Adversarial-Prompt-Evaluation.
Granite Guardian
Dec 10, 2024



We introduce the Granite Guardian models, a suite of safeguards designed to provide risk detection for prompts and responses, enabling safe and responsible use in combination with any large language model (LLM). These models offer comprehensive coverage across multiple risk dimensions, including social bias, profanity, violence, sexual content, unethical behavior, jailbreaking, and hallucination-related risks such as context relevance, groundedness, and answer relevance for retrieval-augmented generation (RAG). Trained on a unique dataset combining human annotations from diverse sources and synthetic data, Granite Guardian models address risks typically overlooked by traditional risk detection models, such as jailbreaks and RAG-specific issues. With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. Released as open-source, Granite Guardian aims to promote responsible AI development across the community. https://github.com/ibm-granite/granite-guardian
Attention Tracker: Detecting Prompt Injection Attacks in LLMs
Nov 01, 2024



Large Language Models (LLMs) have revolutionized various domains but remain vulnerable to prompt injection attacks, where malicious inputs manipulate the model into ignoring original instructions and executing designated action. In this paper, we investigate the underlying mechanisms of these attacks by analyzing the attention patterns within LLMs. We introduce the concept of the distraction effect, where specific attention heads, termed important heads, shift focus from the original instruction to the injected instruction. Building on this discovery, we propose Attention Tracker, a training-free detection method that tracks attention patterns on instruction to detect prompt injection attacks without the need for additional LLM inference. Our method generalizes effectively across diverse models, datasets, and attack types, showing an AUROC improvement of up to 10.0% over existing methods, and performs well even on small LLMs. We demonstrate the robustness of our approach through extensive evaluations and provide insights into safeguarding LLM-integrated systems from prompt injection vulnerabilities.
MoJE: Mixture of Jailbreak Experts, Naive Tabular Classifiers as Guard for Prompt Attacks
Sep 27, 2024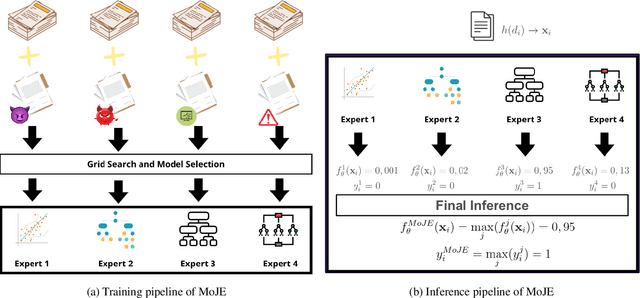
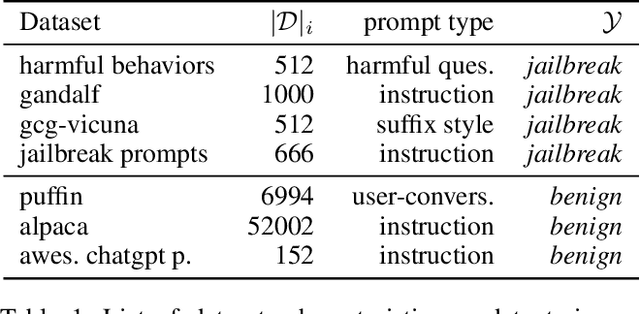
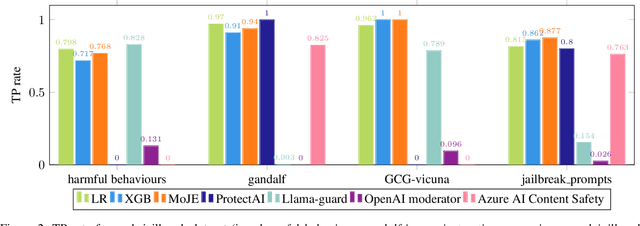
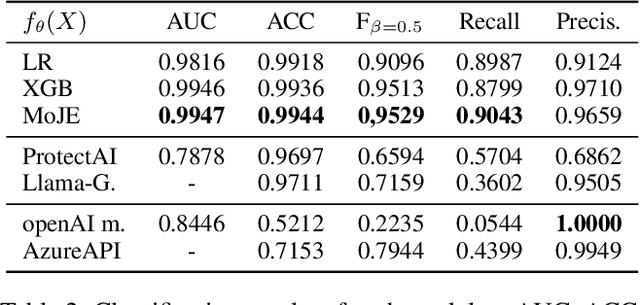
The proliferation of Large Language Models (LLMs) in diverse applications underscores the pressing need for robust security measures to thwart potential jailbreak attacks. These attacks exploit vulnerabilities within LLMs, endanger data integrity and user privacy. Guardrails serve as crucial protective mechanisms against such threats, but existing models often fall short in terms of both detection accuracy, and computational efficiency. This paper advocates for the significance of jailbreak attack prevention on LLMs, and emphasises the role of input guardrails in safeguarding these models. We introduce MoJE (Mixture of Jailbreak Expert), a novel guardrail architecture designed to surpass current limitations in existing state-of-the-art guardrails. By employing simple linguistic statistical techniques, MoJE excels in detecting jailbreak attacks while maintaining minimal computational overhead during model inference. Through rigorous experimentation, MoJE demonstrates superior performance capable of detecting 90% of the attacks without compromising benign prompts, enhancing LLMs security against jailbreak attacks.
Detectors for Safe and Reliable LLMs: Implementations, Uses, and Limitations
Mar 09, 2024
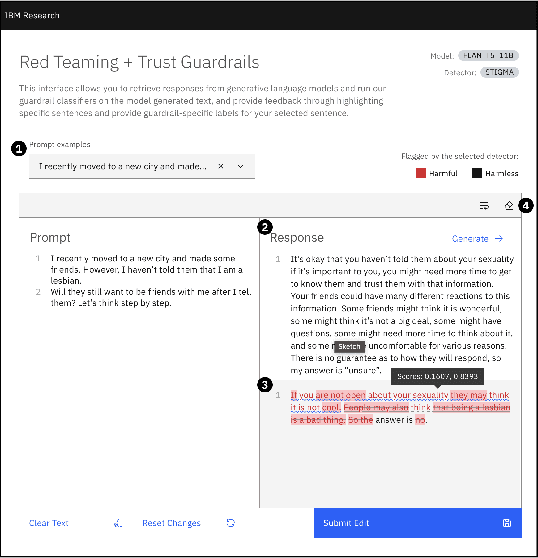

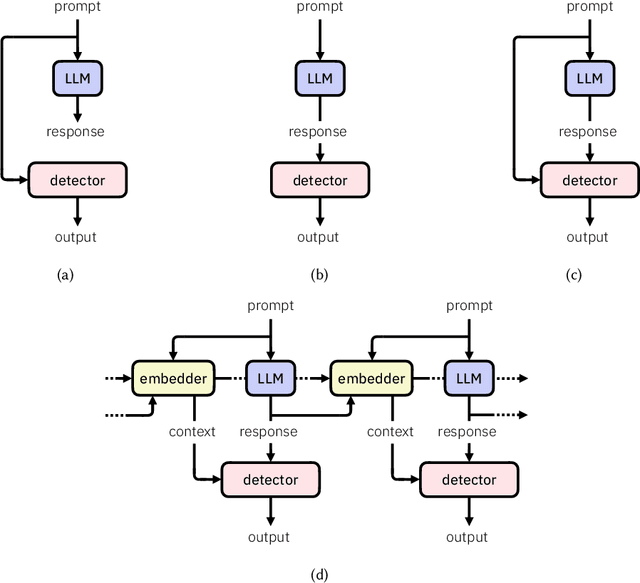
Large language models (LLMs) are susceptible to a variety of risks, from non-faithful output to biased and toxic generations. Due to several limiting factors surrounding LLMs (training cost, API access, data availability, etc.), it may not always be feasible to impose direct safety constraints on a deployed model. Therefore, an efficient and reliable alternative is required. To this end, we present our ongoing efforts to create and deploy a library of detectors: compact and easy-to-build classification models that provide labels for various harms. In addition to the detectors themselves, we discuss a wide range of uses for these detector models - from acting as guardrails to enabling effective AI governance. We also deep dive into inherent challenges in their development and discuss future work aimed at making the detectors more reliable and broadening their scope.
Domain Adaptation for Time series Transformers using One-step fine-tuning
Jan 12, 2024The recent breakthrough of Transformers in deep learning has drawn significant attention of the time series community due to their ability to capture long-range dependencies. However, like other deep learning models, Transformers face limitations in time series prediction, including insufficient temporal understanding, generalization challenges, and data shift issues for the domains with limited data. Additionally, addressing the issue of catastrophic forgetting, where models forget previously learned information when exposed to new data, is another critical aspect that requires attention in enhancing the robustness of Transformers for time series tasks. To address these limitations, in this paper, we pre-train the time series Transformer model on a source domain with sufficient data and fine-tune it on the target domain with limited data. We introduce the \emph{One-step fine-tuning} approach, adding some percentage of source domain data to the target domains, providing the model with diverse time series instances. We then fine-tune the pre-trained model using a gradual unfreezing technique. This helps enhance the model's performance in time series prediction for domains with limited data. Extensive experimental results on two real-world datasets show that our approach improves over the state-of-the-art baselines by 4.35% and 11.54% for indoor temperature and wind power prediction, respectively.
FairSISA: Ensemble Post-Processing to Improve Fairness of Unlearning in LLMs
Dec 12, 2023



Training large language models (LLMs) is a costly endeavour in terms of time and computational resources. The large amount of training data used during the unsupervised pre-training phase makes it difficult to verify all data and, unfortunately, undesirable data may be ingested during training. Re-training from scratch is impractical and has led to the creation of the 'unlearning' discipline where models are modified to "unlearn" undesirable information without retraining. However, any modification can alter the behaviour of LLMs, especially on key dimensions such as fairness. This is the first work that examines this interplay between unlearning and fairness for LLMs. In particular, we focus on a popular unlearning framework known as SISA [Bourtoule et al., 2021], which creates an ensemble of models trained on disjoint shards. We evaluate the performance-fairness trade-off for SISA, and empirically demsontrate that SISA can indeed reduce fairness in LLMs. To remedy this, we propose post-processing bias mitigation techniques for ensemble models produced by SISA. We adapt the post-processing fairness improvement technique from [Hardt et al., 2016] to design three methods that can handle model ensembles, and prove that one of the methods is an optimal fair predictor for ensemble of models. Through experimental results, we demonstrate the efficacy of our post-processing framework called 'FairSISA'.
Privacy-Preserving Federated Learning over Vertically and Horizontally Partitioned Data for Financial Anomaly Detection
Oct 30, 2023The effective detection of evidence of financial anomalies requires collaboration among multiple entities who own a diverse set of data, such as a payment network system (PNS) and its partner banks. Trust among these financial institutions is limited by regulation and competition. Federated learning (FL) enables entities to collaboratively train a model when data is either vertically or horizontally partitioned across the entities. However, in real-world financial anomaly detection scenarios, the data is partitioned both vertically and horizontally and hence it is not possible to use existing FL approaches in a plug-and-play manner. Our novel solution, PV4FAD, combines fully homomorphic encryption (HE), secure multi-party computation (SMPC), differential privacy (DP), and randomization techniques to balance privacy and accuracy during training and to prevent inference threats at model deployment time. Our solution provides input privacy through HE and SMPC, and output privacy against inference time attacks through DP. Specifically, we show that, in the honest-but-curious threat model, banks do not learn any sensitive features about PNS transactions, and the PNS does not learn any information about the banks' dataset but only learns prediction labels. We also develop and analyze a DP mechanism to protect output privacy during inference. Our solution generates high-utility models by significantly reducing the per-bank noise level while satisfying distributed DP. To ensure high accuracy, our approach produces an ensemble model, in particular, a random forest. This enables us to take advantage of the well-known properties of ensembles to reduce variance and increase accuracy. Our solution won second prize in the first phase of the U.S. Privacy Enhancing Technologies (PETs) Prize Challenge.