 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffordance-Guided Coarse-to-Fine Exploration for Base Placement in Open-Vocabulary Mobile Manipulation
Nov 09, 2025



In open-vocabulary mobile manipulation (OVMM), task success often hinges on the selection of an appropriate base placement for the robot. Existing approaches typically navigate to proximity-based regions without considering affordances, resulting in frequent manipulation failures. We propose Affordance-Guided Coarse-to-Fine Exploration, a zero-shot framework for base placement that integrates semantic understanding from vision-language models (VLMs) with geometric feasibility through an iterative optimization process. Our method constructs cross-modal representations, namely Affordance RGB and Obstacle Map+, to align semantics with spatial context. This enables reasoning that extends beyond the egocentric limitations of RGB perception. To ensure interaction is guided by task-relevant affordances, we leverage coarse semantic priors from VLMs to guide the search toward task-relevant regions and refine placements with geometric constraints, thereby reducing the risk of convergence to local optima. Evaluated on five diverse open-vocabulary mobile manipulation tasks, our system achieves an 85% success rate, significantly outperforming classical geometric planners and VLM-based methods. This demonstrates the promise of affordance-aware and multimodal reasoning for generalizable, instruction-conditioned planning in OVMM.
MovieCORE: COgnitive REasoning in Movies
Aug 26, 2025



This paper introduces MovieCORE, a novel video question answering (VQA) dataset designed to probe deeper cognitive understanding of movie content. Unlike existing datasets that focus on surface-level comprehension, MovieCORE emphasizes questions that engage System-2 thinking while remaining specific to the video material. We present an innovative agentic brainstorming approach, utilizing multiple large language models (LLMs) as thought agents to generate and refine high-quality question-answer pairs. To evaluate dataset quality, we develop a set of cognitive tests assessing depth, thought-provocation potential, and syntactic complexity. We also propose a comprehensive evaluation scheme for assessing VQA model performance on deeper cognitive tasks. To address the limitations of existing video-language models (VLMs), we introduce an agentic enhancement module, Agentic Choice Enhancement (ACE), which improves model reasoning capabilities post-training by up to 25%. Our work contributes to advancing movie understanding in AI systems and provides valuable insights into the capabilities and limitations of current VQA models when faced with more challenging, nuanced questions about cinematic content. Our project page, dataset and code can be found at https://joslefaure.github.io/assets/html/moviecore.html.
Improving Generalization Ability for 3D Object Detection by Learning Sparsity-invariant Features
Feb 04, 2025In autonomous driving, 3D object detection is essential for accurately identifying and tracking objects. Despite the continuous development of various technologies for this task, a significant drawback is observed in most of them-they experience substantial performance degradation when detecting objects in unseen domains. In this paper, we propose a method to improve the generalization ability for 3D object detection on a single domain. We primarily focus on generalizing from a single source domain to target domains with distinct sensor configurations and scene distributions. To learn sparsity-invariant features from a single source domain, we selectively subsample the source data to a specific beam, using confidence scores determined by the current detector to identify the density that holds utmost importance for the detector. Subsequently, we employ the teacher-student framework to align the Bird's Eye View (BEV) features for different point clouds densities. We also utilize feature content alignment (FCA) and graph-based embedding relationship alignment (GERA) to instruct the detector to be domain-agnostic. Extensive experiments demonstrate that our method exhibits superior generalization capabilities compared to other baselines. Furthermore, our approach even outperforms certain domain adaptation methods that can access to the target domain data.
Leveraging Content and Context Cues for Low-Light Image Enhancement
Dec 10, 2024

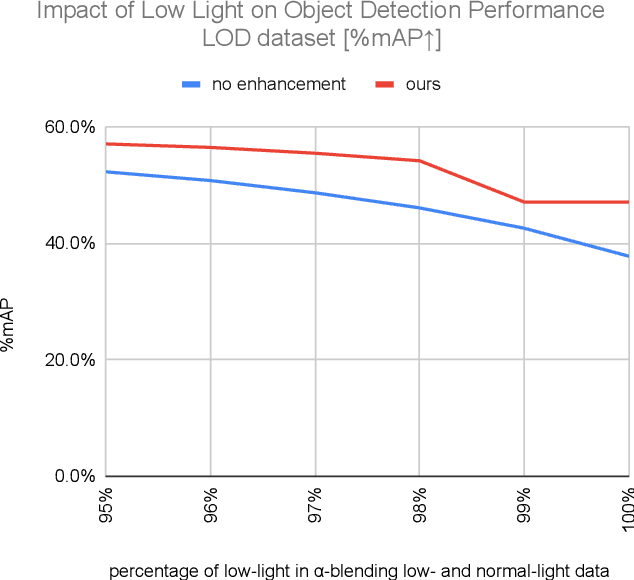

Low-light conditions have an adverse impact on machine cognition, limiting the performance of computer vision systems in real life. Since low-light data is limited and difficult to annotate, we focus on image processing to enhance low-light images and improve the performance of any downstream task model, instead of fine-tuning each of the models which can be prohibitively expensive. We propose to improve the existing zero-reference low-light enhancement by leveraging the CLIP model to capture image prior and for semantic guidance. Specifically, we propose a data augmentation strategy to learn an image prior via prompt learning, based on image sampling, to learn the image prior without any need for paired or unpaired normal-light data. Next, we propose a semantic guidance strategy that maximally takes advantage of existing low-light annotation by introducing both content and context cues about the image training patches. We experimentally show, in a qualitative study, that the proposed prior and semantic guidance help to improve the overall image contrast and hue, as well as improve background-foreground discrimination, resulting in reduced over-saturation and noise over-amplification, common in related zero-reference methods. As we target machine cognition, rather than rely on assuming the correlation between human perception and downstream task performance, we conduct and present an ablation study and comparison with related zero-reference methods in terms of task-based performance across many low-light datasets, including image classification, object and face detection, showing the effectiveness of our proposed method.
Attention Tracker: Detecting Prompt Injection Attacks in LLMs
Nov 01, 2024



Large Language Models (LLMs) have revolutionized various domains but remain vulnerable to prompt injection attacks, where malicious inputs manipulate the model into ignoring original instructions and executing designated action. In this paper, we investigate the underlying mechanisms of these attacks by analyzing the attention patterns within LLMs. We introduce the concept of the distraction effect, where specific attention heads, termed important heads, shift focus from the original instruction to the injected instruction. Building on this discovery, we propose Attention Tracker, a training-free detection method that tracks attention patterns on instruction to detect prompt injection attacks without the need for additional LLM inference. Our method generalizes effectively across diverse models, datasets, and attack types, showing an AUROC improvement of up to 10.0% over existing methods, and performs well even on small LLMs. We demonstrate the robustness of our approach through extensive evaluations and provide insights into safeguarding LLM-integrated systems from prompt injection vulnerabilities.
Unveiling Narrative Reasoning Limits of Large Language Models with Trope in Movie Synopses
Sep 22, 2024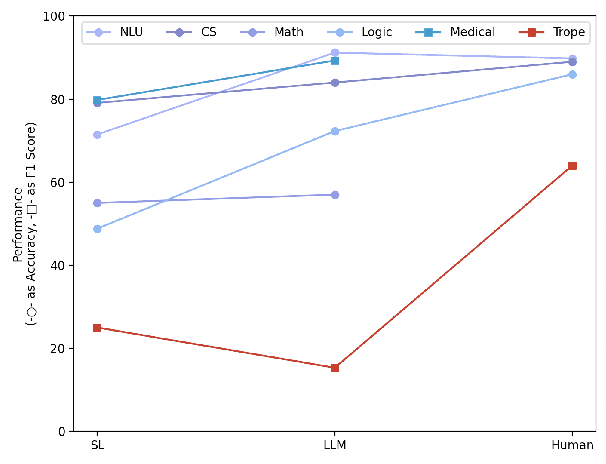

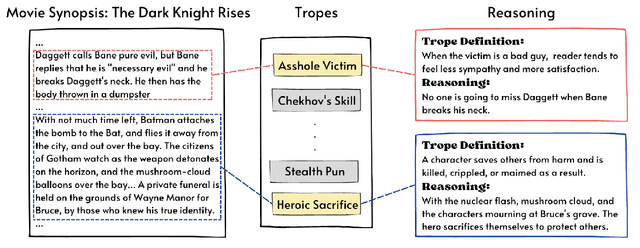

Large language models (LLMs) equipped with chain-of-thoughts (CoT) prompting have shown significant multi-step reasoning capabilities in factual content like mathematics, commonsense, and logic. However, their performance in narrative reasoning, which demands greater abstraction capabilities, remains unexplored. This study utilizes tropes in movie synopses to assess the abstract reasoning abilities of state-of-the-art LLMs and uncovers their low performance. We introduce a trope-wise querying approach to address these challenges and boost the F1 score by 11.8 points. Moreover, while prior studies suggest that CoT enhances multi-step reasoning, this study shows CoT can cause hallucinations in narrative content, reducing GPT-4's performance. We also introduce an Adversarial Injection method to embed trope-related text tokens into movie synopses without explicit tropes, revealing CoT's heightened sensitivity to such injections. Our comprehensive analysis provides insights for future research directions.
Distribution Discrepancy and Feature Heterogeneity for Active 3D Object Detection
Sep 11, 2024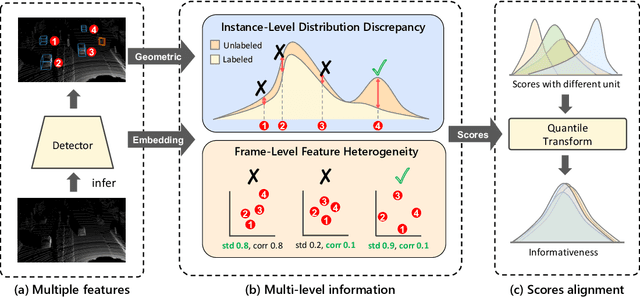

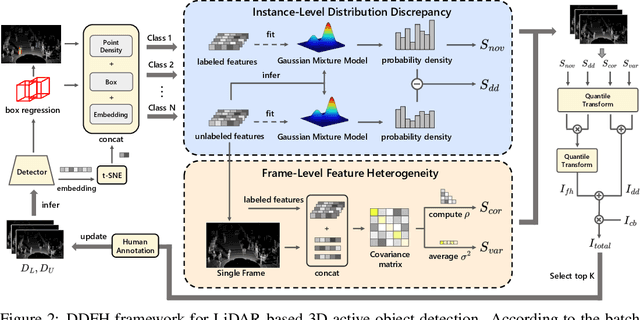
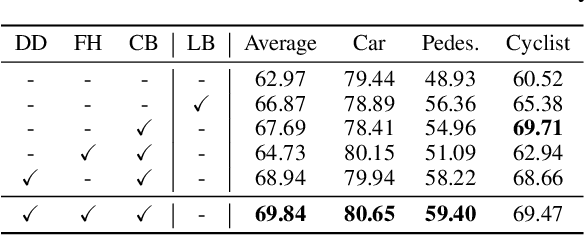
LiDAR-based 3D object detection is a critical technology for the development of autonomous driving and robotics. However, the high cost of data annotation limits its advancement. We propose a novel and effective active learning (AL) method called Distribution Discrepancy and Feature Heterogeneity (DDFH), which simultaneously considers geometric features and model embeddings, assessing information from both the instance-level and frame-level perspectives. Distribution Discrepancy evaluates the difference and novelty of instances within the unlabeled and labeled distributions, enabling the model to learn efficiently with limited data. Feature Heterogeneity ensures the heterogeneity of intra-frame instance features, maintaining feature diversity while avoiding redundant or similar instances, thus minimizing annotation costs. Finally, multiple indicators are efficiently aggregated using Quantile Transform, providing a unified measure of informativeness. Extensive experiments demonstrate that DDFH outperforms the current state-of-the-art (SOTA) methods on the KITTI and Waymo datasets, effectively reducing the bounding box annotation cost by 56.3% and showing robustness when working with both one-stage and two-stage models.
Context-Aware Replanning with Pre-explored Semantic Map for Object Navigation
Sep 07, 2024
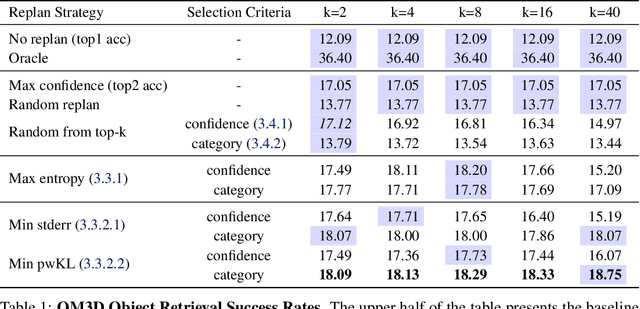
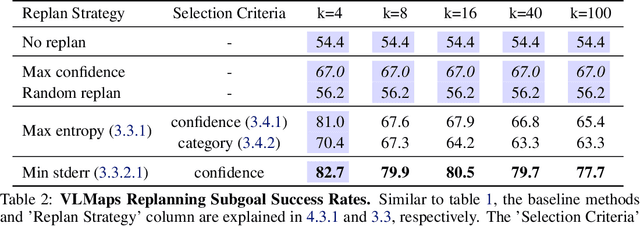
Pre-explored Semantic Maps, constructed through prior exploration using visual language models (VLMs), have proven effective as foundational elements for training-free robotic applications. However, existing approaches assume the map's accuracy and do not provide effective mechanisms for revising decisions based on incorrect maps. To address this, we introduce Context-Aware Replanning (CARe), which estimates map uncertainty through confidence scores and multi-view consistency, enabling the agent to revise erroneous decisions stemming from inaccurate maps without requiring additional labels. We demonstrate the effectiveness of our proposed method by integrating it with two modern mapping backbones, VLMaps and OpenMask3D, and observe significant performance improvements in object navigation tasks. More details can be found on the project page: https://carmaps.github.io/supplements/.
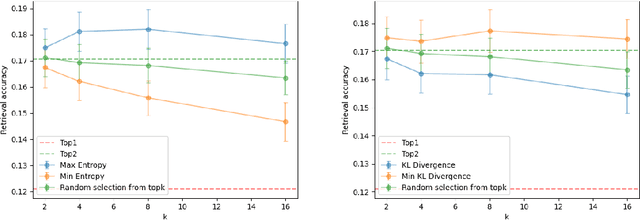
Bridging Episodes and Semantics: A Novel Framework for Long-Form Video Understanding
Aug 30, 2024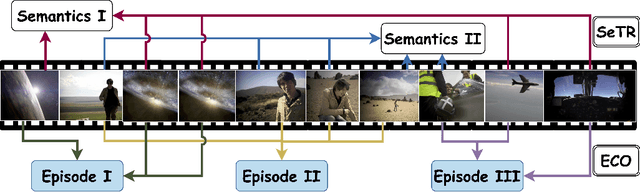
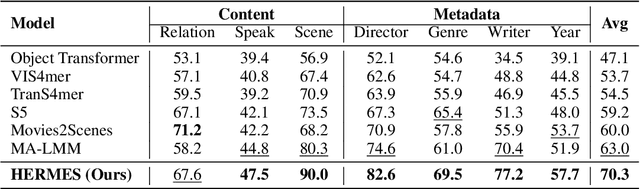
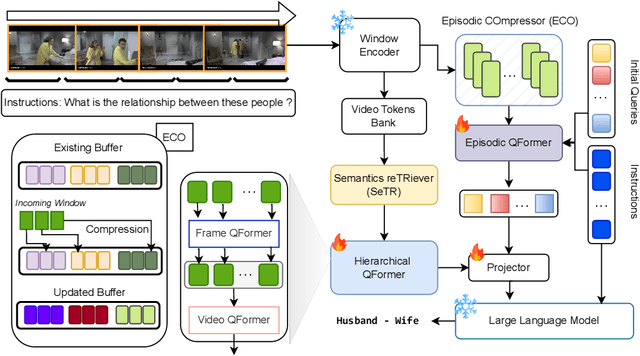

While existing research often treats long-form videos as extended short videos, we propose a novel approach that more accurately reflects human cognition. This paper introduces BREASE: BRidging Episodes And SEmantics for Long-Form Video Understanding, a model that simulates episodic memory accumulation to capture action sequences and reinforces them with semantic knowledge dispersed throughout the video. Our work makes two key contributions: First, we develop an Episodic COmpressor (ECO) that efficiently aggregates crucial representations from micro to semi-macro levels. Second, we propose a Semantics reTRiever (SeTR) that enhances these aggregated representations with semantic information by focusing on the broader context, dramatically reducing feature dimensionality while preserving relevant macro-level information. Extensive experiments demonstrate that BREASE achieves state-of-the-art performance across multiple long video understanding benchmarks in both zero-shot and fully-supervised settings. The project page and code are at: https://joslefaure.github.io/assets/html/hermes.html.
Investigating Video Reasoning Capability of Large Language Models with Tropes in Movies
Jun 16, 2024



Large Language Models (LLMs) have demonstrated effectiveness not only in language tasks but also in video reasoning. This paper introduces a novel dataset, Tropes in Movies (TiM), designed as a testbed for exploring two critical yet previously overlooked video reasoning skills: (1) Abstract Perception: understanding and tokenizing abstract concepts in videos, and (2) Long-range Compositional Reasoning: planning and integrating intermediate reasoning steps for understanding long-range videos with numerous frames. Utilizing tropes from movie storytelling, TiM evaluates the reasoning capabilities of state-of-the-art LLM-based approaches. Our experiments show that current methods, including Captioner-Reasoner, Large Multimodal Model Instruction Fine-tuning, and Visual Programming, only marginally outperform a random baseline when tackling the challenges of Abstract Perception and Long-range Compositional Reasoning. To address these deficiencies, we propose Face-Enhanced Viper of Role Interactions (FEVoRI) and Context Query Reduction (ConQueR), which enhance Visual Programming by fostering role interaction awareness and progressively refining movie contexts and trope queries during reasoning processes, significantly improving performance by 15 F1 points. However, this performance still lags behind human levels (40 vs. 65 F1). Additionally, we introduce a new protocol to evaluate the necessity of Abstract Perception and Long-range Compositional Reasoning for task resolution. This is done by analyzing the code generated through Visual Programming using an Abstract Syntax Tree (AST), thereby confirming the increased complexity of TiM. The dataset and code are available at: https://ander1119.github.io/TiM