 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVICtoR: Learning Hierarchical Vision-Instruction Correlation Rewards for Long-horizon Manipulation
May 26, 2024
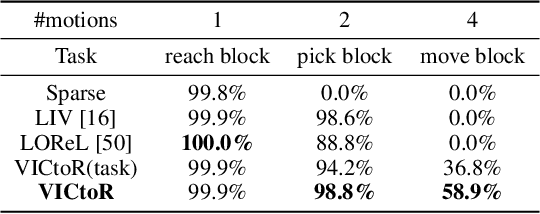
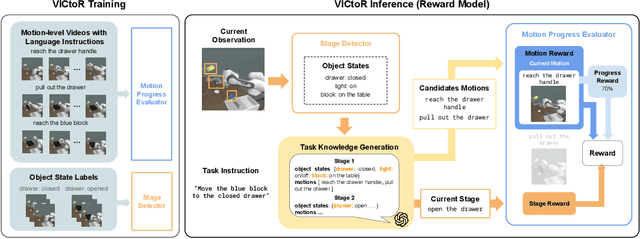
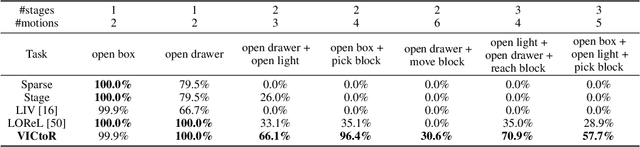
We study reward models for long-horizon manipulation tasks by learning from action-free videos and language instructions, which we term the visual-instruction correlation (VIC) problem. Recent advancements in cross-modality modeling have highlighted the potential of reward modeling through visual and language correlations. However, existing VIC methods face challenges in learning rewards for long-horizon tasks due to their lack of sub-stage awareness, difficulty in modeling task complexities, and inadequate object state estimation. To address these challenges, we introduce VICtoR, a novel hierarchical VIC reward model capable of providing effective reward signals for long-horizon manipulation tasks. VICtoR precisely assesses task progress at various levels through a novel stage detector and motion progress evaluator, offering insightful guidance for agents learning the task effectively. To validate the effectiveness of VICtoR, we conducted extensive experiments in both simulated and real-world environments. The results suggest that VICtoR outperformed the best existing VIC methods, achieving a 43% improvement in success rates for long-horizon tasks.
AED: Adaptable Error Detection for Few-shot Imitation Policy
Feb 06, 2024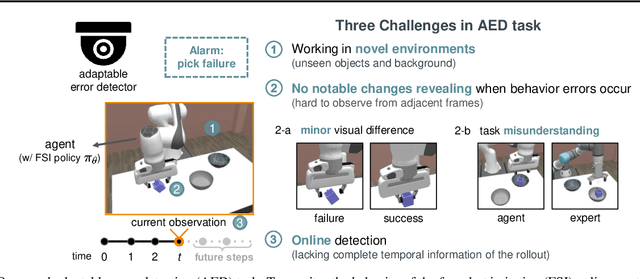

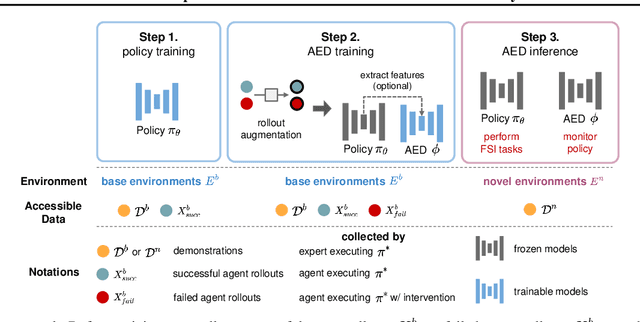
We study how to report few-shot imitation (FSI) policies' behavior errors in novel environments, a novel task named adaptable error detection (AED). The potential to cause serious damage to surrounding areas limits the application of FSI policies in real-world scenarios. Thus, a robust system is necessary to notify operators when FSI policies are inconsistent with the intent of demonstrations. We develop a cross-domain benchmark for the challenging AED task, consisting of 329 base and 158 novel environments. This task introduces three challenges, including (1) detecting behavior errors in novel environments, (2) behavior errors occurring without revealing notable changes, and (3) lacking complete temporal information of the rollout due to the necessity of online detection. To address these challenges, we propose Pattern Observer (PrObe) to parse discernible patterns in the policy feature representations of normal or error states, whose effectiveness is verified in the proposed benchmark. Through our comprehensive evaluation, PrObe consistently surpasses strong baselines and demonstrates a robust capability to identify errors arising from a wide range of FSI policies. Moreover, we conduct comprehensive ablations and experiments (error correction, demonstration quality, etc.) to validate the practicality of our proposed task and methodology.