 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch Arena: Analyzing Search-Augmented LLMs
Jun 05, 2025Search-augmented language models combine web search with Large Language Models (LLMs) to improve response groundedness and freshness. However, analyzing these systems remains challenging: existing datasets are limited in scale and narrow in scope, often constrained to static, single-turn, fact-checking questions. In this work, we introduce Search Arena, a crowd-sourced, large-scale, human-preference dataset of over 24,000 paired multi-turn user interactions with search-augmented LLMs. The dataset spans diverse intents and languages, and contains full system traces with around 12,000 human preference votes. Our analysis reveals that user preferences are influenced by the number of citations, even when the cited content does not directly support the attributed claims, uncovering a gap between perceived and actual credibility. Furthermore, user preferences vary across cited sources, revealing that community-driven platforms are generally preferred and static encyclopedic sources are not always appropriate and reliable. To assess performance across different settings, we conduct cross-arena analyses by testing search-augmented LLMs in a general-purpose chat environment and conventional LLMs in search-intensive settings. We find that web search does not degrade and may even improve performance in non-search settings; however, the quality in search settings is significantly affected if solely relying on the model's parametric knowledge. We open-sourced the dataset to support future research in this direction. Our dataset and code are available at: https://github.com/lmarena/search-arena.
Puzzled by Puzzles: When Vision-Language Models Can't Take a Hint
May 29, 2025Rebus puzzles, visual riddles that encode language through imagery, spatial arrangement, and symbolic substitution, pose a unique challenge to current vision-language models (VLMs). Unlike traditional image captioning or question answering tasks, rebus solving requires multi-modal abstraction, symbolic reasoning, and a grasp of cultural, phonetic and linguistic puns. In this paper, we investigate the capacity of contemporary VLMs to interpret and solve rebus puzzles by constructing a hand-generated and annotated benchmark of diverse English-language rebus puzzles, ranging from simple pictographic substitutions to spatially-dependent cues ("head" over "heels"). We analyze how different VLMs perform, and our findings reveal that while VLMs exhibit some surprising capabilities in decoding simple visual clues, they struggle significantly with tasks requiring abstract reasoning, lateral thinking, and understanding visual metaphors.
LISAT: Language-Instructed Segmentation Assistant for Satellite Imagery
May 05, 2025Segmentation models can recognize a pre-defined set of objects in images. However, models that can reason over complex user queries that implicitly refer to multiple objects of interest are still in their infancy. Recent advances in reasoning segmentation--generating segmentation masks from complex, implicit query text--demonstrate that vision-language models can operate across an open domain and produce reasonable outputs. However, our experiments show that such models struggle with complex remote-sensing imagery. In this work, we introduce LISAt, a vision-language model designed to describe complex remote-sensing scenes, answer questions about them, and segment objects of interest. We trained LISAt on a new curated geospatial reasoning-segmentation dataset, GRES, with 27,615 annotations over 9,205 images, and a multimodal pretraining dataset, PreGRES, containing over 1 million question-answer pairs. LISAt outperforms existing geospatial foundation models such as RS-GPT4V by over 10.04 % (BLEU-4) on remote-sensing description tasks, and surpasses state-of-the-art open-domain models on reasoning segmentation tasks by 143.36 % (gIoU). Our model, datasets, and code are available at https://lisat-bair.github.io/LISAt/
Generate, but Verify: Reducing Hallucination in Vision-Language Models with Retrospective Resampling
Apr 17, 2025Vision-Language Models (VLMs) excel at visual understanding but often suffer from visual hallucinations, where they generate descriptions of nonexistent objects, actions, or concepts, posing significant risks in safety-critical applications. Existing hallucination mitigation methods typically follow one of two paradigms: generation adjustment, which modifies decoding behavior to align text with visual inputs, and post-hoc verification, where external models assess and correct outputs. While effective, generation adjustment methods often rely on heuristics and lack correction mechanisms, while post-hoc verification is complicated, typically requiring multiple models and tending to reject outputs rather than refine them. In this work, we introduce REVERSE, a unified framework that integrates hallucination-aware training with on-the-fly self-verification. By leveraging a new hallucination-verification dataset containing over 1.3M semi-synthetic samples, along with a novel inference-time retrospective resampling technique, our approach enables VLMs to both detect hallucinations during generation and dynamically revise those hallucinations. Our evaluations show that REVERSE achieves state-of-the-art hallucination reduction, outperforming the best existing methods by up to 12% on CHAIR-MSCOCO and 28% on HaloQuest. Our dataset, model, and code are available at: https://reverse-vlm.github.io.
Visual Haystacks: Answering Harder Questions About Sets of Images
Jul 18, 2024



Recent advancements in Large Multimodal Models (LMMs) have made significant progress in the field of single-image visual question answering. However, these models face substantial challenges when tasked with queries that span extensive collections of images, similar to real-world scenarios like searching through large photo albums, finding specific information across the internet, or monitoring environmental changes through satellite imagery. This paper explores the task of Multi-Image Visual Question Answering (MIQA): given a large set of images and a natural language query, the task is to generate a relevant and grounded response. We propose a new public benchmark, dubbed "Visual Haystacks (VHs)," specifically designed to evaluate LMMs' capabilities in visual retrieval and reasoning over sets of unrelated images, where we perform comprehensive evaluations demonstrating that even robust closed-source models struggle significantly. Towards addressing these shortcomings, we introduce MIRAGE (Multi-Image Retrieval Augmented Generation), a novel retrieval/QA framework tailored for LMMs that confronts the challenges of MIQA with marked efficiency and accuracy improvements over baseline methods. Our evaluation shows that MIRAGE surpasses closed-source GPT-4o models by up to 11% on the VHs benchmark and offers up to 3.4x improvements in efficiency over text-focused multi-stage approaches.
AED: Adaptable Error Detection for Few-shot Imitation Policy
Feb 06, 2024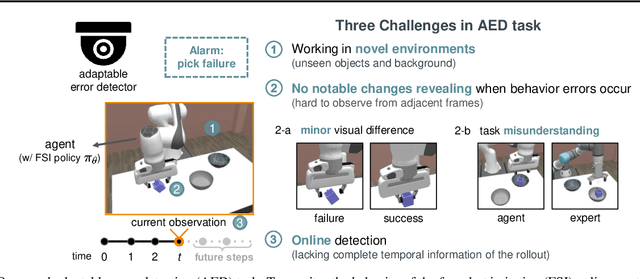

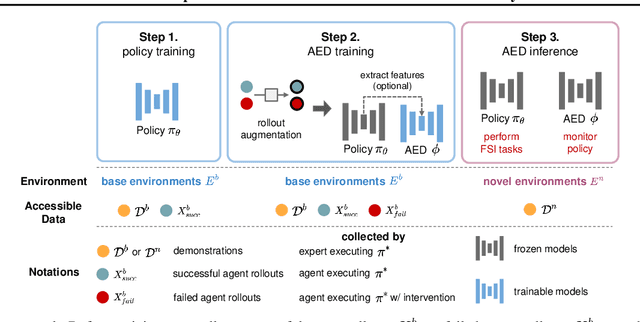
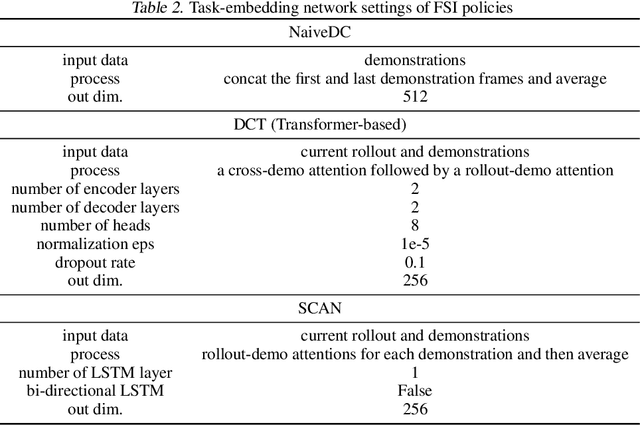
We study how to report few-shot imitation (FSI) policies' behavior errors in novel environments, a novel task named adaptable error detection (AED). The potential to cause serious damage to surrounding areas limits the application of FSI policies in real-world scenarios. Thus, a robust system is necessary to notify operators when FSI policies are inconsistent with the intent of demonstrations. We develop a cross-domain benchmark for the challenging AED task, consisting of 329 base and 158 novel environments. This task introduces three challenges, including (1) detecting behavior errors in novel environments, (2) behavior errors occurring without revealing notable changes, and (3) lacking complete temporal information of the rollout due to the necessity of online detection. To address these challenges, we propose Pattern Observer (PrObe) to parse discernible patterns in the policy feature representations of normal or error states, whose effectiveness is verified in the proposed benchmark. Through our comprehensive evaluation, PrObe consistently surpasses strong baselines and demonstrates a robust capability to identify errors arising from a wide range of FSI policies. Moreover, we conduct comprehensive ablations and experiments (error correction, demonstration quality, etc.) to validate the practicality of our proposed task and methodology.
See, Say, and Segment: Teaching LMMs to Overcome False Premises
Dec 13, 2023



Current open-source Large Multimodal Models (LMMs) excel at tasks such as open-vocabulary language grounding and segmentation but can suffer under false premises when queries imply the existence of something that is not actually present in the image. We observe that existing methods that fine-tune an LMM to segment images significantly degrade their ability to reliably determine ("see") if an object is present and to interact naturally with humans ("say"), a form of catastrophic forgetting. In this work, we propose a cascading and joint training approach for LMMs to solve this task, avoiding catastrophic forgetting of previous skills. Our resulting model can "see" by detecting whether objects are present in an image, "say" by telling the user if they are not, proposing alternative queries or correcting semantic errors in the query, and finally "segment" by outputting the mask of the desired objects if they exist. Additionally, we introduce a novel False Premise Correction benchmark dataset, an extension of existing RefCOCO(+/g) referring segmentation datasets (which we call FP-RefCOCO(+/g)). The results show that our method not only detects false premises up to 55% better than existing approaches, but under false premise conditions produces relative cIOU improvements of more than 31% over baselines, and produces natural language feedback judged helpful up to 67% of the time.
Self-correcting LLM-controlled Diffusion Models
Nov 27, 2023Text-to-image generation has witnessed significant progress with the advent of diffusion models. Despite the ability to generate photorealistic images, current text-to-image diffusion models still often struggle to accurately interpret and follow complex input text prompts. In contrast to existing models that aim to generate images only with their best effort, we introduce Self-correcting LLM-controlled Diffusion (SLD). SLD is a framework that generates an image from the input prompt, assesses its alignment with the prompt, and performs self-corrections on the inaccuracies in the generated image. Steered by an LLM controller, SLD turns text-to-image generation into an iterative closed-loop process, ensuring correctness in the resulting image. SLD is not only training-free but can also be seamlessly integrated with diffusion models behind API access, such as DALL-E 3, to further boost the performance of state-of-the-art diffusion models. Experimental results show that our approach can rectify a majority of incorrect generations, particularly in generative numeracy, attribute binding, and spatial relationships. Furthermore, by simply adjusting the instructions to the LLM, SLD can perform image editing tasks, bridging the gap between text-to-image generation and image editing pipelines. We will make our code available for future research and applications.
WLST: Weak Labels Guided Self-training for Weakly-supervised Domain Adaptation on 3D Object Detection
Oct 05, 2023In the field of domain adaptation (DA) on 3D object detection, most of the work is dedicated to unsupervised domain adaptation (UDA). Yet, without any target annotations, the performance gap between the UDA approaches and the fully-supervised approach is still noticeable, which is impractical for real-world applications. On the other hand, weakly-supervised domain adaptation (WDA) is an underexplored yet practical task that only requires few labeling effort on the target domain. To improve the DA performance in a cost-effective way, we propose a general weak labels guided self-training framework, WLST, designed for WDA on 3D object detection. By incorporating autolabeler, which can generate 3D pseudo labels from 2D bounding boxes, into the existing self-training pipeline, our method is able to generate more robust and consistent pseudo labels that would benefit the training process on the target domain. Extensive experiments demonstrate the effectiveness, robustness, and detector-agnosticism of our WLST framework. Notably, it outperforms previous state-of-the-art methods on all evaluation tasks.
MuRAL: Multi-Scale Region-based Active Learning for Object Detection
Mar 29, 2023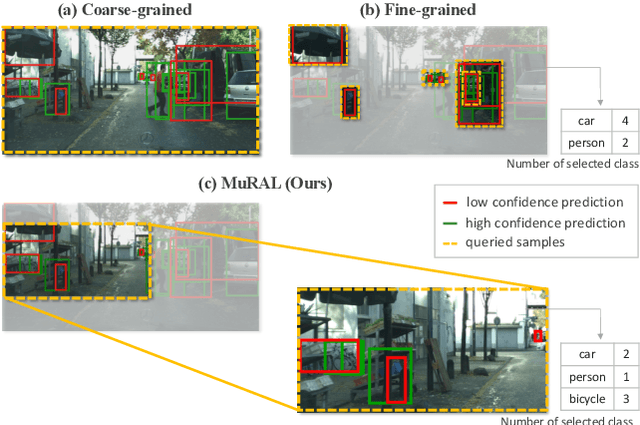
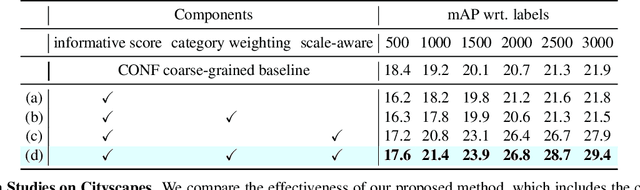
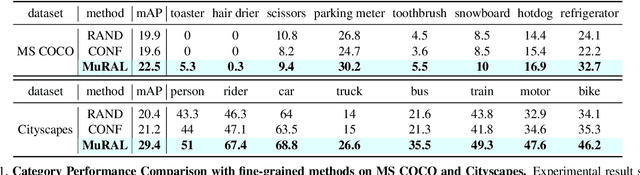

Obtaining large-scale labeled object detection dataset can be costly and time-consuming, as it involves annotating images with bounding boxes and class labels. Thus, some specialized active learning methods have been proposed to reduce the cost by selecting either coarse-grained samples or fine-grained instances from unlabeled data for labeling. However, the former approaches suffer from redundant labeling, while the latter methods generally lead to training instability and sampling bias. To address these challenges, we propose a novel approach called Multi-scale Region-based Active Learning (MuRAL) for object detection. MuRAL identifies informative regions of various scales to reduce annotation costs for well-learned objects and improve training performance. The informative region score is designed to consider both the predicted confidence of instances and the distribution of each object category, enabling our method to focus more on difficult-to-detect classes. Moreover, MuRAL employs a scale-aware selection strategy that ensures diverse regions are selected from different scales for labeling and downstream finetuning, which enhances training stability. Our proposed method surpasses all existing coarse-grained and fine-grained baselines on Cityscapes and MS COCO datasets, and demonstrates significant improvement in difficult category performance.