 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLISAT: Language-Instructed Segmentation Assistant for Satellite Imagery
May 05, 2025Segmentation models can recognize a pre-defined set of objects in images. However, models that can reason over complex user queries that implicitly refer to multiple objects of interest are still in their infancy. Recent advances in reasoning segmentation--generating segmentation masks from complex, implicit query text--demonstrate that vision-language models can operate across an open domain and produce reasonable outputs. However, our experiments show that such models struggle with complex remote-sensing imagery. In this work, we introduce LISAt, a vision-language model designed to describe complex remote-sensing scenes, answer questions about them, and segment objects of interest. We trained LISAt on a new curated geospatial reasoning-segmentation dataset, GRES, with 27,615 annotations over 9,205 images, and a multimodal pretraining dataset, PreGRES, containing over 1 million question-answer pairs. LISAt outperforms existing geospatial foundation models such as RS-GPT4V by over 10.04 % (BLEU-4) on remote-sensing description tasks, and surpasses state-of-the-art open-domain models on reasoning segmentation tasks by 143.36 % (gIoU). Our model, datasets, and code are available at https://lisat-bair.github.io/LISAt/
Visual Haystacks: Answering Harder Questions About Sets of Images
Jul 18, 2024



Recent advancements in Large Multimodal Models (LMMs) have made significant progress in the field of single-image visual question answering. However, these models face substantial challenges when tasked with queries that span extensive collections of images, similar to real-world scenarios like searching through large photo albums, finding specific information across the internet, or monitoring environmental changes through satellite imagery. This paper explores the task of Multi-Image Visual Question Answering (MIQA): given a large set of images and a natural language query, the task is to generate a relevant and grounded response. We propose a new public benchmark, dubbed "Visual Haystacks (VHs)," specifically designed to evaluate LMMs' capabilities in visual retrieval and reasoning over sets of unrelated images, where we perform comprehensive evaluations demonstrating that even robust closed-source models struggle significantly. Towards addressing these shortcomings, we introduce MIRAGE (Multi-Image Retrieval Augmented Generation), a novel retrieval/QA framework tailored for LMMs that confronts the challenges of MIQA with marked efficiency and accuracy improvements over baseline methods. Our evaluation shows that MIRAGE surpasses closed-source GPT-4o models by up to 11% on the VHs benchmark and offers up to 3.4x improvements in efficiency over text-focused multi-stage approaches.
LLARVA: Vision-Action Instruction Tuning Enhances Robot Learning
Jun 17, 2024



In recent years, instruction-tuned Large Multimodal Models (LMMs) have been successful at several tasks, including image captioning and visual question answering; yet leveraging these models remains an open question for robotics. Prior LMMs for robotics applications have been extensively trained on language and action data, but their ability to generalize in different settings has often been less than desired. To address this, we introduce LLARVA, a model trained with a novel instruction tuning method that leverages structured prompts to unify a range of robotic learning tasks, scenarios, and environments. Additionally, we show that predicting intermediate 2-D representations, which we refer to as "visual traces", can help further align vision and action spaces for robot learning. We generate 8.5M image-visual trace pairs from the Open X-Embodiment dataset in order to pre-train our model, and we evaluate on 12 different tasks in the RLBench simulator as well as a physical Franka Emika Panda 7-DoF robot. Our experiments yield strong performance, demonstrating that LLARVA - using 2-D and language representations - performs well compared to several contemporary baselines, and can generalize across various robot environments and configurations.
Lithium Metal Battery Quality Control via Transformer-CNN Segmentation
Feb 09, 2023



Lithium metal battery (LMB) has the potential to be the next-generation battery system because of their high theoretical energy density. However, defects known as dendrites are formed by heterogeneous lithium (Li) plating, which hinder the development and utilization of LMBs. Non-destructive techniques to observe the dendrite morphology often use computerized X-ray tomography (XCT) imaging to provide cross-sectional views. To retrieve three-dimensional structures inside a battery, image segmentation becomes essential to quantitatively analyze XCT images. This work proposes a new binary semantic segmentation approach using a transformer-based neural network (T-Net) model capable of segmenting out dendrites from XCT data. In addition, we compare the performance of the proposed T-Net with three other algorithms, such as U-Net, Y-Net, and E-Net, consisting of an Ensemble Network model for XCT analysis. Our results show the advantages of using T-Net in terms of object metrics, such as mean Intersection over Union (mIoU) and mean Dice Similarity Coefficient (mDSC) as well as qualitatively through several comparative visualizations.
Fast, Accurate Barcode Detection in Ultra High-Resolution Images
Feb 13, 2021
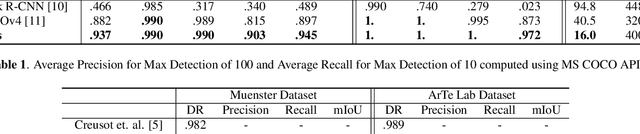

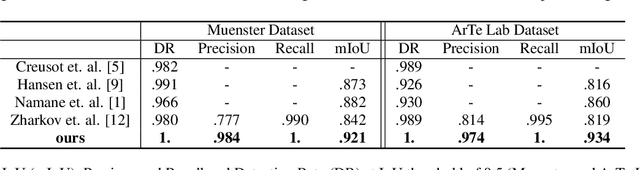
Object detection in Ultra High-Resolution (UHR) images has long been a challenging problem in computer vision due to the varying scales of the targeted objects. When it comes to barcode detection, resizing UHR input images to smaller sizes often leads to the loss of pertinent information, while processing them directly is highly inefficient and computationally expensive. In this paper, we propose using semantic segmentation to achieve a fast and accurate detection of barcodes of various scales in UHR images. Our pipeline involves a modified Region Proposal Network (RPN) on images of size greater than 10k$\times$10k and a newly proposed Y-Net segmentation network, followed by a post-processing workflow for fitting a bounding box around each segmented barcode mask. The end-to-end system has a latency of 16 milliseconds, which is $2.5\times$ faster than YOLOv4 and $5.9\times$ faster than Mask RCNN. In terms of accuracy, our method outperforms YOLOv4 and Mask R-CNN by a $mAP$ of 5.5% and 47.1% respectively, on a synthetic dataset. We have made available the generated synthetic barcode dataset and its code at http://www.github.com/viplab/BSBD/.