 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreSight: Preoperative Outcome Prediction for Parkinson's Disease via Region-Prior Morphometry and Patient-Specific Weighting
Mar 02, 2026Preoperative improvement rate prediction for Parkinson's disease surgery is clinically important yet difficult because imaging signals are subtle and patients are heterogeneous. We address this setting, where only information available before surgery is used, and the goal is to predict patient-specific postoperative motor benefit. We present PreSight, a presurgical outcome model that fuses clinical priors with preoperative MRI and deformation-based morphometry (DBM) and adapts regional importance through a patient-specific weighting module. The model produces end-to-end, calibrated, decision-ready predictions with patient-level explanations. We evaluate PreSight on a real-world two-center cohort of 400 subjects with multimodal presurgical inputs and postoperative improvement labels. PreSight outperforms strong clinical, imaging-only, and multimodal baselines. It attains 88.89% accuracy on internal validation and 85.29% on an external-center test for responder classification and shows better probability calibration and higher decision-curve net benefit. Ablations and analyses confirm the contribution of DBM and the patient-specific weighting module and indicate that the model emphasizes disease-relevant regions in a patient-specific manner. These results demonstrate that integrating clinical prior knowledge with region-adaptive morphometry enables reliable presurgical decision support in routine practice.
Virtual Biopsy for Intracranial Tumors Diagnosis on MRI
Feb 25, 2026Deep intracranial tumors situated in eloquent brain regions controlling vital functions present critical diagnostic challenges. Clinical practice has shifted toward stereotactic biopsy for pathological confirmation before treatment. Yet biopsy carries inherent risks of hemorrhage and neurological deficits and struggles with sampling bias due to tumor spatial heterogeneity, because pathological changes are typically region-selective rather than tumor-wide. Therefore, advancing non-invasive MRI-based pathology prediction is essential for holistic tumor assessment and modern clinical decision-making. The primary challenge lies in data scarcity: low tumor incidence requires long collection cycles, and annotation demands biopsy-verified pathology from neurosurgical experts. Additionally, tiny lesion volumes lacking segmentation masks cause critical features to be overwhelmed by background noise. To address these challenges, we construct the ICT-MRI dataset - the first public biopsy-verified benchmark with 249 cases across four categories. We propose a Virtual Biopsy framework comprising: MRI-Processor for standardization; Tumor-Localizer employing vision-language models for coarse-to-fine localization via weak supervision; and Adaptive-Diagnoser with a Masked Channel Attention mechanism fusing local discriminative features with global contexts. Experiments demonstrate over 90% accuracy, outperforming baselines by more than 20%.
ReBA-Pred-Net: Weakly-Supervised Regional Brain Age Prediction on MRI
Feb 13, 2026Brain age has become a prominent biomarker of brain health. Yet most prior work targets whole brain age (WBA), a coarse paradigm that struggles to support tasks such as disease characterization and research on development and aging patterns, because relevant changes are typically region-selective rather than brain-wide. Therefore, robust regional brain age (ReBA) estimation is critical, yet a widely generalizable model has yet to be established. In this paper, we propose the Regional Brain Age Prediction Network (ReBA-Pred-Net), a Teacher-Student framework designed for fine-grained brain age estimation. The Teacher produces soft ReBA to guide the Student to yield reliable ReBA estimates with a clinical-prior consistency constraint (regions within the same function should change similarly). For rigorous evaluation, we introduce two indirect metrics: Healthy Control Similarity (HCS), which assesses statistical consistency by testing whether regional brain-age-gap (ReBA minus chronological age) distributions align between training and unseen HC; and Neuro Disease Correlation (NDC), which assesses factual consistency by checking whether clinically confirmed patients show elevated brain-age-gap in disease-associated regions. Experiments across multiple backbones demonstrate the statistical and factual validity of our method.
Vibe Spaces for Creatively Connecting and Expressing Visual Concepts
Dec 16, 2025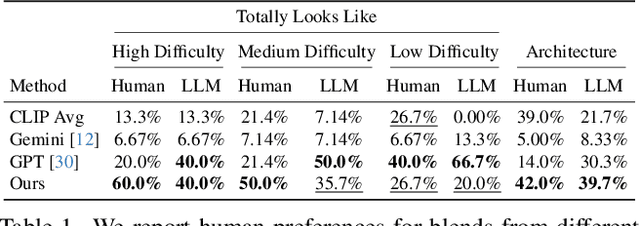

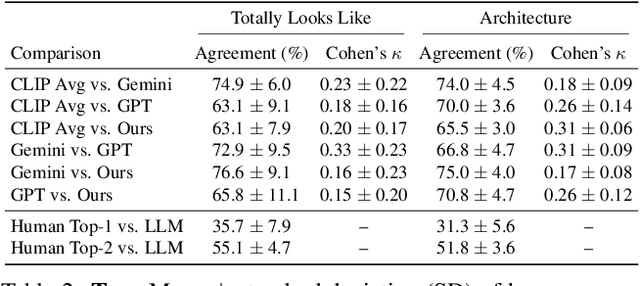
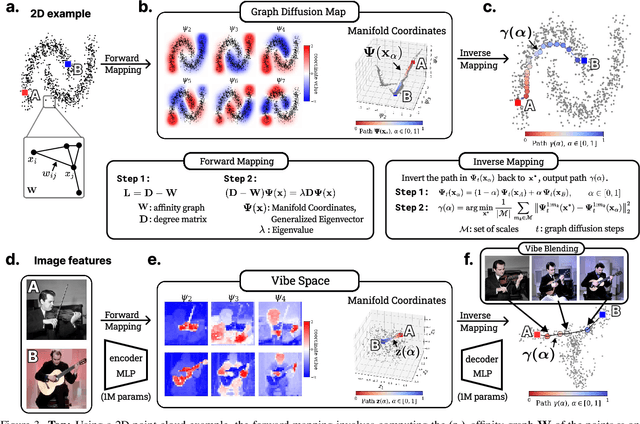
Creating new visual concepts often requires connecting distinct ideas through their most relevant shared attributes -- their vibe. We introduce Vibe Blending, a novel task for generating coherent and meaningful hybrids that reveals these shared attributes between images. Achieving such blends is challenging for current methods, which struggle to identify and traverse nonlinear paths linking distant concepts in latent space. We propose Vibe Space, a hierarchical graph manifold that learns low-dimensional geodesics in feature spaces like CLIP, enabling smooth and semantically consistent transitions between concepts. To evaluate creative quality, we design a cognitively inspired framework combining human judgments, LLM reasoning, and a geometric path-based difficulty score. We find that Vibe Space produces blends that humans consistently rate as more creative and coherent than current methods.
Transformers Discover Molecular Structure Without Graph Priors
Oct 02, 2025



Graph Neural Networks (GNNs) are the dominant architecture for molecular machine learning, particularly for molecular property prediction and machine learning interatomic potentials (MLIPs). GNNs perform message passing on predefined graphs often induced by a fixed radius cutoff or k-nearest neighbor scheme. While this design aligns with the locality present in many molecular tasks, a hard-coded graph can limit expressivity due to the fixed receptive field and slows down inference with sparse graph operations. In this work, we investigate whether pure, unmodified Transformers trained directly on Cartesian coordinates$\unicode{x2013}$without predefined graphs or physical priors$\unicode{x2013}$can approximate molecular energies and forces. As a starting point for our analysis, we demonstrate how to train a Transformer to competitive energy and force mean absolute errors under a matched training compute budget, relative to a state-of-the-art equivariant GNN on the OMol25 dataset. We discover that the Transformer learns physically consistent patterns$\unicode{x2013}$such as attention weights that decay inversely with interatomic distance$\unicode{x2013}$and flexibly adapts them across different molecular environments due to the absence of hard-coded biases. The use of a standard Transformer also unlocks predictable improvements with respect to scaling training resources, consistent with empirical scaling laws observed in other domains. Our results demonstrate that many favorable properties of GNNs can emerge adaptively in Transformers, challenging the necessity of hard-coded graph inductive biases and pointing toward standardized, scalable architectures for molecular modeling.
Whole-Body Conditioned Egocentric Video Prediction
Jun 26, 2025



We train models to Predict Ego-centric Video from human Actions (PEVA), given the past video and an action represented by the relative 3D body pose. By conditioning on kinematic pose trajectories, structured by the joint hierarchy of the body, our model learns to simulate how physical human actions shape the environment from a first-person point of view. We train an auto-regressive conditional diffusion transformer on Nymeria, a large-scale dataset of real-world egocentric video and body pose capture. We further design a hierarchical evaluation protocol with increasingly challenging tasks, enabling a comprehensive analysis of the model's embodied prediction and control abilities. Our work represents an initial attempt to tackle the challenges of modeling complex real-world environments and embodied agent behaviors with video prediction from the perspective of a human.
TARDIS STRIDE: A Spatio-Temporal Road Image Dataset for Exploration and Autonomy
Jun 12, 2025World models aim to simulate environments and enable effective agent behavior. However, modeling real-world environments presents unique challenges as they dynamically change across both space and, crucially, time. To capture these composed dynamics, we introduce a Spatio-Temporal Road Image Dataset for Exploration (STRIDE) permuting 360-degree panoramic imagery into rich interconnected observation, state and action nodes. Leveraging this structure, we can simultaneously model the relationship between egocentric views, positional coordinates, and movement commands across both space and time. We benchmark this dataset via TARDIS, a transformer-based generative world model that integrates spatial and temporal dynamics through a unified autoregressive framework trained on STRIDE. We demonstrate robust performance across a range of agentic tasks such as controllable photorealistic image synthesis, instruction following, autonomous self-control, and state-of-the-art georeferencing. These results suggest a promising direction towards sophisticated generalist agents--capable of understanding and manipulating the spatial and temporal aspects of their material environments--with enhanced embodied reasoning capabilities. Training code, datasets, and model checkpoints are made available at https://huggingface.co/datasets/Tera-AI/STRIDE.
AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time
May 30, 2025This paper presents AlphaOne ($\alpha$1), a universal framework for modulating reasoning progress in large reasoning models (LRMs) at test time. $\alpha$1 first introduces $\alpha$ moment, which represents the scaled thinking phase with a universal parameter $\alpha$. Within this scaled pre-$\alpha$ moment phase, it dynamically schedules slow thinking transitions by modeling the insertion of reasoning transition tokens as a Bernoulli stochastic process. After the $\alpha$ moment, $\alpha$1 deterministically terminates slow thinking with the end-of-thinking token, thereby fostering fast reasoning and efficient answer generation. This approach unifies and generalizes existing monotonic scaling methods by enabling flexible and dense slow-to-fast reasoning modulation. Extensive empirical studies on various challenging benchmarks across mathematical, coding, and scientific domains demonstrate $\alpha$1's superior reasoning capability and efficiency. Project page: https://alphaone-project.github.io/
REOrdering Patches Improves Vision Models
May 29, 2025Sequence models such as transformers require inputs to be represented as one-dimensional sequences. In vision, this typically involves flattening images using a fixed row-major (raster-scan) order. While full self-attention is permutation-equivariant, modern long-sequence transformers increasingly rely on architectural approximations that break this invariance and introduce sensitivity to patch ordering. We show that patch order significantly affects model performance in such settings, with simple alternatives like column-major or Hilbert curves yielding notable accuracy shifts. Motivated by this, we propose REOrder, a two-stage framework for discovering task-optimal patch orderings. First, we derive an information-theoretic prior by evaluating the compressibility of various patch sequences. Then, we learn a policy over permutations by optimizing a Plackett-Luce policy using REINFORCE. This approach enables efficient learning in a combinatorial permutation space. REOrder improves top-1 accuracy over row-major ordering on ImageNet-1K by up to 3.01% and Functional Map of the World by 13.35%.
"I Know It When I See It": Mood Spaces for Connecting and Expressing Visual Concepts
Apr 21, 2025



Expressing complex concepts is easy when they can be labeled or quantified, but many ideas are hard to define yet instantly recognizable. We propose a Mood Board, where users convey abstract concepts with examples that hint at the intended direction of attribute changes. We compute an underlying Mood Space that 1) factors out irrelevant features and 2) finds the connections between images, thus bringing relevant concepts closer. We invent a fibration computation to compress/decompress pre-trained features into/from a compact space, 50-100x smaller. The main innovation is learning to mimic the pairwise affinity relationship of the image tokens across exemplars. To focus on the coarse-to-fine hierarchical structures in the Mood Space, we compute the top eigenvector structure from the affinity matrix and define a loss in the eigenvector space. The resulting Mood Space is locally linear and compact, allowing image-level operations, such as object averaging, visual analogy, and pose transfer, to be performed as a simple vector operation in Mood Space. Our learning is efficient in computation without any fine-tuning, needs only a few (2-20) exemplars, and takes less than a minute to learn.