 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning or Memorization? Direction-Aware Diversity Exploration in LLM Reinforcement Learning
Jun 09, 2026Reinforcement learning has become a key paradigm for eliciting reasoning abilities in large language models, where exploration is crucial for discovering effective solution trajectories. Existing exploration methods typically encourage diversity in semantic or gradient spaces, without distinguishing what drives this diversity. A trajectory may appear novel because it follows a new reasoning process, or because it varies memorized patterns and shortcuts. Rewarding both cases equally may steer exploration toward memorization rather than genuine reasoning improvement. In this paper, we propose DiRL, a Direction-Aware Reinforcement Learning framework that anchors exploration to an internal reasoning-memorization direction of the policy. Specifically, DiRL extracts this direction from model representations, constructs direction-weighted gradient features to characterize rollout updates, and shapes rewards to amplify reasoning-aligned exploration while suppressing memorization-aligned variations. DiRL integrates seamlessly into standard Group Relative Policy Optimization (GRPO). Extensive experiments on mathematical and general reasoning benchmarks demonstrate the effectiveness of DiRL, showing significant improvements over various existing exploration methods.
Learning to Build the Environment: Self-Evolving Reasoning RL via Verifiable Environment Synthesis
May 14, 2026We pursue a vision for self-improving language models in which the model does not merely generate problems or traces to imitate, but constructs the environments that train it. In zero-data reasoning RL, this reframes self-improvement from a data-generation loop into an environment-construction loop, where each artifact is a reusable executable object that samples instances, computes references, and scores responses. Whether this vision sustains improvement hinges on a single property: the environments must exhibit stable solve--verify asymmetry, the model must be able to write an oracle once that it cannot reliably execute in natural language on fresh instances. This asymmetry takes two complementary forms. Some tasks are algorithmically hard to reason through but trivial as code: a dynamic program or graph traversal, compiled once, yields unboundedly many calibrated instances. Others are intrinsically hard to solve but easy to verify, like planted subset-sum or constraint satisfaction. Both create a durable gap between proposing and solving that the policy cannot close by gaming the verifier, and it is this gap that keeps reward informative as the learner improves. We instantiate this view in EvoEnv, a single-policy generator, solver method that synthesizes Python environments from ten seeds and admits them only after staged validation, semantic self-review, solver-relative difficulty calibration, and novelty checks. The strongest evidence comes from the already-strong regime: on Qwen3-4B-Thinking, fixed public-data RLVR and fixed hand-crafted environment RLVR reduce the average, while EvoEnv improves it from 72.4 to 74.8, a relative gain of 3.3%. Stable self-improvement, we suggest, depends not on producing more synthetic data, but on models learning to construct worlds whose difficulty stays structurally beyond their own reach.
Distributionally Robust Cooperative Multi-Agent Reinforcement Learning via Robust Value Factorization
Feb 11, 2026Cooperative multi-agent reinforcement learning (MARL) commonly adopts centralized training with decentralized execution, where value-factorization methods enforce the individual-global-maximum (IGM) principle so that decentralized greedy actions recover the team-optimal joint action. However, the reliability of this recipe in real-world settings remains unreliable due to environmental uncertainties arising from the sim-to-real gap, model mismatch, and system noise. We address this gap by introducing Distributionally robust IGM (DrIGM), a principle that requires each agent's robust greedy action to align with the robust team-optimal joint action. We show that DrIGM holds for a novel definition of robust individual action values, which is compatible with decentralized greedy execution and yields a provable robustness guarantee for the whole system. Building on this foundation, we derive DrIGM-compliant robust variants of existing value-factorization architectures (e.g., VDN/QMIX/QTRAN) that (i) train on robust Q-targets, (ii) preserve scalability, and (iii) integrate seamlessly with existing codebases without bespoke per-agent reward shaping. Empirically, on high-fidelity SustainGym simulators and a StarCraft game environment, our methods consistently improve out-of-distribution performance. Code and data are available at https://github.com/crqu/robust-coMARL.
The Single-Multi Evolution Loop for Self-Improving Model Collaboration Systems
Feb 05, 2026Model collaboration -- systems where multiple language models (LMs) collaborate -- combines the strengths of diverse models with cost in loading multiple LMs. We improve efficiency while preserving the strengths of collaboration by distilling collaborative patterns into a single model, where the model is trained on the outputs of the model collaboration system. At inference time, only the distilled model is employed: it imitates the collaboration while only incurring the cost of a single model. Furthermore, we propose the single-multi evolution loop: multiple LMs collaborate, each distills from the collaborative outputs, and these post-distillation improved LMs collaborate again, forming a collective evolution ecosystem where models evolve and self-improve by interacting with an environment of other models. Extensive experiments with 7 collaboration strategies and 15 tasks (QA, reasoning, factuality, etc.) demonstrate that: 1) individual models improve by 8.0% on average, absorbing the strengths of collaboration while reducing the cost to a single model; 2) the collaboration also benefits from the stronger and more synergistic LMs after distillation, improving over initial systems without evolution by 14.9% on average. Analysis reveals that the single-multi evolution loop outperforms various existing evolutionary AI methods, is compatible with diverse model/collaboration/distillation settings, and helps solve problems where the initial model/system struggles to.
Can LLMs Guide Their Own Exploration? Gradient-Guided Reinforcement Learning for LLM Reasoning
Dec 17, 2025
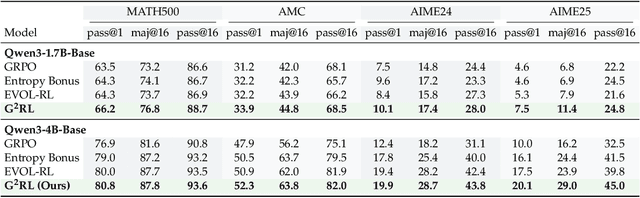
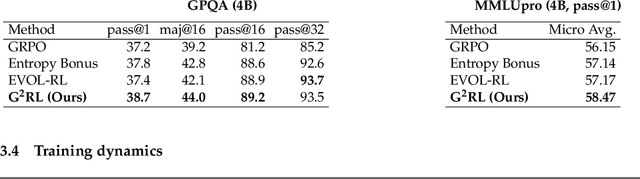
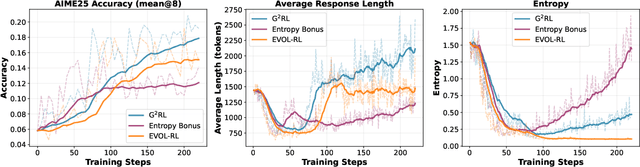
Reinforcement learning has become essential for strengthening the reasoning abilities of large language models, yet current exploration mechanisms remain fundamentally misaligned with how these models actually learn. Entropy bonuses and external semantic comparators encourage surface level variation but offer no guarantee that sampled trajectories differ in the update directions that shape optimization. We propose G2RL, a gradient guided reinforcement learning framework in which exploration is driven not by external heuristics but by the model own first order update geometry. For each response, G2RL constructs a sequence level feature from the model final layer sensitivity, obtainable at negligible cost from a standard forward pass, and measures how each trajectory would reshape the policy by comparing these features within a sampled group. Trajectories that introduce novel gradient directions receive a bounded multiplicative reward scaler, while redundant or off manifold updates are deemphasized, yielding a self referential exploration signal that is naturally aligned with PPO style stability and KL control. Across math and general reasoning benchmarks (MATH500, AMC, AIME24, AIME25, GPQA, MMLUpro) on Qwen3 base 1.7B and 4B models, G2RL consistently improves pass@1, maj@16, and pass@k over entropy based GRPO and external embedding methods. Analyzing the induced geometry, we find that G2RL expands exploration into substantially more orthogonal and often opposing gradient directions while maintaining semantic coherence, revealing that a policy own update space provides a far more faithful and effective basis for guiding exploration in large language model reinforcement learning.
Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation
Sep 18, 2025Large language models (LLMs) are increasingly trained with reinforcement learning from verifiable rewards (RLVR), yet real-world deployment demands models that can self-improve without labels or external judges. Existing label-free methods, confidence minimization, self-consistency, or majority-vote objectives, stabilize learning but steadily shrink exploration, causing an entropy collapse: generations become shorter, less diverse, and brittle. Unlike prior approaches such as Test-Time Reinforcement Learning (TTRL), which primarily adapt models to the immediate unlabeled dataset at hand, our goal is broader: to enable general improvements without sacrificing the model's inherent exploration capacity and generalization ability, i.e., evolving. We formalize this issue and propose EVolution-Oriented and Label-free Reinforcement Learning (EVOL-RL), a simple rule that couples stability with variation under a label-free setting. EVOL-RL keeps the majority-voted answer as a stable anchor (selection) while adding a novelty-aware reward that favors responses whose reasoning differs from what has already been produced (variation), measured in semantic space. Implemented with GRPO, EVOL-RL also uses asymmetric clipping to preserve strong signals and an entropy regularizer to sustain search. This majority-for-selection + novelty-for-variation design prevents collapse, maintains longer and more informative chains of thought, and improves both pass@1 and pass@n. EVOL-RL consistently outperforms the majority-only TTRL baseline; e.g., training on label-free AIME24 lifts Qwen3-4B-Base AIME25 pass@1 from TTRL's 4.6% to 16.4%, and pass@16 from 18.5% to 37.9%. EVOL-RL not only prevents diversity collapse but also unlocks stronger generalization across domains (e.g., GPQA). Furthermore, we demonstrate that EVOL-RL also boosts performance in the RLVR setting, highlighting its broad applicability.
TARDIS STRIDE: A Spatio-Temporal Road Image Dataset for Exploration and Autonomy
Jun 12, 2025World models aim to simulate environments and enable effective agent behavior. However, modeling real-world environments presents unique challenges as they dynamically change across both space and, crucially, time. To capture these composed dynamics, we introduce a Spatio-Temporal Road Image Dataset for Exploration (STRIDE) permuting 360-degree panoramic imagery into rich interconnected observation, state and action nodes. Leveraging this structure, we can simultaneously model the relationship between egocentric views, positional coordinates, and movement commands across both space and time. We benchmark this dataset via TARDIS, a transformer-based generative world model that integrates spatial and temporal dynamics through a unified autoregressive framework trained on STRIDE. We demonstrate robust performance across a range of agentic tasks such as controllable photorealistic image synthesis, instruction following, autonomous self-control, and state-of-the-art georeferencing. These results suggest a promising direction towards sophisticated generalist agents--capable of understanding and manipulating the spatial and temporal aspects of their material environments--with enhanced embodied reasoning capabilities. Training code, datasets, and model checkpoints are made available at https://huggingface.co/datasets/Tera-AI/STRIDE.
Efficient Policy Optimization in Robust Constrained MDPs with Iteration Complexity Guarantees
May 25, 2025Constrained decision-making is essential for designing safe policies in real-world control systems, yet simulated environments often fail to capture real-world adversities. We consider the problem of learning a policy that will maximize the cumulative reward while satisfying a constraint, even when there is a mismatch between the real model and an accessible simulator/nominal model. In particular, we consider the robust constrained Markov decision problem (RCMDP) where an agent needs to maximize the reward and satisfy the constraint against the worst possible stochastic model under the uncertainty set centered around an unknown nominal model. Primal-dual methods, effective for standard constrained MDP (CMDP), are not applicable here because of the lack of the strong duality property. Further, one cannot apply the standard robust value-iteration based approach on the composite value function either as the worst case models may be different for the reward value function and the constraint value function. We propose a novel technique that effectively minimizes the constraint value function--to satisfy the constraints; on the other hand, when all the constraints are satisfied, it can simply maximize the robust reward value function. We prove that such an algorithm finds a policy with at most $\epsilon$ sub-optimality and feasible policy after $O(\epsilon^{-2})$ iterations. In contrast to the state-of-the-art method, we do not need to employ a binary search, thus, we reduce the computation time by at least 4x for smaller value of discount factor ($\gamma$) and by at least 6x for larger value of $\gamma$.
KL-regularization Itself is Differentially Private in Bandits and RLHF
May 23, 2025Differential Privacy (DP) provides a rigorous framework for privacy, ensuring the outputs of data-driven algorithms remain statistically indistinguishable across datasets that differ in a single entry. While guaranteeing DP generally requires explicitly injecting noise either to the algorithm itself or to its outputs, the intrinsic randomness of existing algorithms presents an opportunity to achieve DP ``for free''. In this work, we explore the role of regularization in achieving DP across three different decision-making problems: multi-armed bandits, linear contextual bandits, and reinforcement learning from human feedback (RLHF), in offline data settings. We show that adding KL-regularization to the learning objective (a common approach in optimization algorithms) makes the action sampled from the resulting stochastic policy itself differentially private. This offers a new route to privacy guarantees without additional noise injection, while also preserving the inherent advantage of regularization in enhancing performance.
Distributionally Robust Direct Preference Optimization
Feb 04, 2025



A major challenge in aligning large language models (LLMs) with human preferences is the issue of distribution shift. LLM alignment algorithms rely on static preference datasets, assuming that they accurately represent real-world user preferences. However, user preferences vary significantly across geographical regions, demographics, linguistic patterns, and evolving cultural trends. This preference distribution shift leads to catastrophic alignment failures in many real-world applications. We address this problem using the principled framework of distributionally robust optimization, and develop two novel distributionally robust direct preference optimization (DPO) algorithms, namely, Wasserstein DPO (WDPO) and Kullback-Leibler DPO (KLDPO). We characterize the sample complexity of learning the optimal policy parameters for WDPO and KLDPO. Moreover, we propose scalable gradient descent-style learning algorithms by developing suitable approximations for the challenging minimax loss functions of WDPO and KLDPO. Our empirical experiments demonstrate the superior performance of WDPO and KLDPO in substantially improving the alignment when there is a preference distribution shift.