 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphon Mean-Field Subsampling for Cooperative Heterogeneous Multi-Agent Reinforcement Learning
Feb 18, 2026Coordinating large populations of interacting agents is a central challenge in multi-agent reinforcement learning (MARL), where the size of the joint state-action space scales exponentially with the number of agents. Mean-field methods alleviate this burden by aggregating agent interactions, but these approaches assume homogeneous interactions. Recent graphon-based frameworks capture heterogeneity, but are computationally expensive as the number of agents grows. Therefore, we introduce $\texttt{GMFS}$, a $\textbf{G}$raphon $\textbf{M}$ean-$\textbf{F}$ield $\textbf{S}$ubsampling framework for scalable cooperative MARL with heterogeneous agent interactions. By subsampling $κ$ agents according to interaction strength, we approximate the graphon-weighted mean-field and learn a policy with sample complexity $\mathrm{poly}(κ)$ and optimality gap $O(1/\sqrtκ)$. We verify our theory with numerical simulations in robotic coordination, showing that $\texttt{GMFS}$ achieves near-optimal performance.
Distributionally Robust Cooperative Multi-Agent Reinforcement Learning via Robust Value Factorization
Feb 11, 2026Cooperative multi-agent reinforcement learning (MARL) commonly adopts centralized training with decentralized execution, where value-factorization methods enforce the individual-global-maximum (IGM) principle so that decentralized greedy actions recover the team-optimal joint action. However, the reliability of this recipe in real-world settings remains unreliable due to environmental uncertainties arising from the sim-to-real gap, model mismatch, and system noise. We address this gap by introducing Distributionally robust IGM (DrIGM), a principle that requires each agent's robust greedy action to align with the robust team-optimal joint action. We show that DrIGM holds for a novel definition of robust individual action values, which is compatible with decentralized greedy execution and yields a provable robustness guarantee for the whole system. Building on this foundation, we derive DrIGM-compliant robust variants of existing value-factorization architectures (e.g., VDN/QMIX/QTRAN) that (i) train on robust Q-targets, (ii) preserve scalability, and (iii) integrate seamlessly with existing codebases without bespoke per-agent reward shaping. Empirically, on high-fidelity SustainGym simulators and a StarCraft game environment, our methods consistently improve out-of-distribution performance. Code and data are available at https://github.com/crqu/robust-coMARL.
Understanding Agent Scaling in LLM-Based Multi-Agent Systems via Diversity
Feb 03, 2026LLM-based multi-agent systems (MAS) have emerged as a promising approach to tackle complex tasks that are difficult for individual LLMs. A natural strategy is to scale performance by increasing the number of agents; however, we find that such scaling exhibits strong diminishing returns in homogeneous settings, while introducing heterogeneity (e.g., different models, prompts, or tools) continues to yield substantial gains. This raises a fundamental question: what limits scaling, and why does diversity help? We present an information-theoretic framework showing that MAS performance is bounded by the intrinsic task uncertainty, not by agent count. We derive architecture-agnostic bounds demonstrating that improvements depend on how many effective channels the system accesses. Homogeneous agents saturate early because their outputs are strongly correlated, whereas heterogeneous agents contribute complementary evidence. We further introduce $K^*$, an effective channel count that quantifies the number of effective channels without ground-truth labels. Empirically, we show that heterogeneous configurations consistently outperform homogeneous scaling: 2 diverse agents can match or exceed the performance of 16 homogeneous agents. Our results provide principled guidelines for building efficient and robust MAS through diversity-aware design. Code and Dataset are available at the link: https://github.com/SafeRL-Lab/Agent-Scaling.
SCaLE: Switching Cost aware Learning and Exploration
Jan 14, 2026This work addresses the fundamental problem of unbounded metric movement costs in bandit online convex optimization, by considering high-dimensional dynamic quadratic hitting costs and $\ell_2$-norm switching costs in a noisy bandit feedback model. For a general class of stochastic environments, we provide the first algorithm SCaLE that provably achieves a distribution-agnostic sub-linear dynamic regret, without the knowledge of hitting cost structure. En-route, we present a novel spectral regret analysis that separately quantifies eigenvalue-error driven regret and eigenbasis-perturbation driven regret. Extensive numerical experiments, against online-learning baselines, corroborate our claims, and highlight statistical consistency of our algorithm.
Fairness-Regularized Online Optimization with Switching Costs
Dec 11, 2025Fairness and action smoothness are two crucial considerations in many online optimization problems, but they have yet to be addressed simultaneously. In this paper, we study a new and challenging setting of fairness-regularized smoothed online convex optimization with switching costs. First, to highlight the fundamental challenges introduced by the long-term fairness regularizer evaluated based on the entire sequence of actions, we prove that even without switching costs, no online algorithms can possibly achieve a sublinear regret or finite competitive ratio compared to the offline optimal algorithm as the problem episode length $T$ increases. Then, we propose FairOBD (Fairness-regularized Online Balanced Descent), which reconciles the tension between minimizing the hitting cost, switching cost, and fairness cost. Concretely, FairOBD decomposes the long-term fairness cost into a sequence of online costs by introducing an auxiliary variable and then leverages the auxiliary variable to regularize the online actions for fair outcomes. Based on a new approach to account for switching costs, we prove that FairOBD offers a worst-case asymptotic competitive ratio against a novel benchmark -- the optimal offline algorithm with parameterized constraints -- by considering $T\to\infty$. Finally, we run trace-driven experiments of dynamic computing resource provisioning for socially responsible AI inference to empirically evaluate FairOBD, showing that FairOBD can effectively reduce the total fairness-regularized cost and better promote fair outcomes compared to existing baseline solutions.
Efficient Policy Optimization in Robust Constrained MDPs with Iteration Complexity Guarantees
May 25, 2025Constrained decision-making is essential for designing safe policies in real-world control systems, yet simulated environments often fail to capture real-world adversities. We consider the problem of learning a policy that will maximize the cumulative reward while satisfying a constraint, even when there is a mismatch between the real model and an accessible simulator/nominal model. In particular, we consider the robust constrained Markov decision problem (RCMDP) where an agent needs to maximize the reward and satisfy the constraint against the worst possible stochastic model under the uncertainty set centered around an unknown nominal model. Primal-dual methods, effective for standard constrained MDP (CMDP), are not applicable here because of the lack of the strong duality property. Further, one cannot apply the standard robust value-iteration based approach on the composite value function either as the worst case models may be different for the reward value function and the constraint value function. We propose a novel technique that effectively minimizes the constraint value function--to satisfy the constraints; on the other hand, when all the constraints are satisfied, it can simply maximize the robust reward value function. We prove that such an algorithm finds a policy with at most $\epsilon$ sub-optimality and feasible policy after $O(\epsilon^{-2})$ iterations. In contrast to the state-of-the-art method, we do not need to employ a binary search, thus, we reduce the computation time by at least 4x for smaller value of discount factor ($\gamma$) and by at least 6x for larger value of $\gamma$.
KL-regularization Itself is Differentially Private in Bandits and RLHF
May 23, 2025Differential Privacy (DP) provides a rigorous framework for privacy, ensuring the outputs of data-driven algorithms remain statistically indistinguishable across datasets that differ in a single entry. While guaranteeing DP generally requires explicitly injecting noise either to the algorithm itself or to its outputs, the intrinsic randomness of existing algorithms presents an opportunity to achieve DP ``for free''. In this work, we explore the role of regularization in achieving DP across three different decision-making problems: multi-armed bandits, linear contextual bandits, and reinforcement learning from human feedback (RLHF), in offline data settings. We show that adding KL-regularization to the learning objective (a common approach in optimization algorithms) makes the action sampled from the resulting stochastic policy itself differentially private. This offers a new route to privacy guarantees without additional noise injection, while also preserving the inherent advantage of regularization in enhancing performance.
Fusing Reward and Dueling Feedback in Stochastic Bandits
Apr 22, 2025This paper investigates the fusion of absolute (reward) and relative (dueling) feedback in stochastic bandits, where both feedback types are gathered in each decision round. We derive a regret lower bound, demonstrating that an efficient algorithm may incur only the smaller among the reward and dueling-based regret for each individual arm. We propose two fusion approaches: (1) a simple elimination fusion algorithm that leverages both feedback types to explore all arms and unifies collected information by sharing a common candidate arm set, and (2) a decomposition fusion algorithm that selects the more effective feedback to explore the corresponding arms and randomly assigns one feedback type for exploration and the other for exploitation in each round. The elimination fusion experiences a suboptimal multiplicative term of the number of arms in regret due to the intrinsic suboptimality of dueling elimination. In contrast, the decomposition fusion achieves regret matching the lower bound up to a constant under a common assumption. Extensive experiments confirm the efficacy of our algorithms and theoretical results.
Robust Gymnasium: A Unified Modular Benchmark for Robust Reinforcement Learning
Feb 27, 2025



Driven by inherent uncertainty and the sim-to-real gap, robust reinforcement learning (RL) seeks to improve resilience against the complexity and variability in agent-environment sequential interactions. Despite the existence of a large number of RL benchmarks, there is a lack of standardized benchmarks for robust RL. Current robust RL policies often focus on a specific type of uncertainty and are evaluated in distinct, one-off environments. In this work, we introduce Robust-Gymnasium, a unified modular benchmark designed for robust RL that supports a wide variety of disruptions across all key RL components-agents' observed state and reward, agents' actions, and the environment. Offering over sixty diverse task environments spanning control and robotics, safe RL, and multi-agent RL, it provides an open-source and user-friendly tool for the community to assess current methods and foster the development of robust RL algorithms. In addition, we benchmark existing standard and robust RL algorithms within this framework, uncovering significant deficiencies in each and offering new insights.
Towards Environmentally Equitable AI
Dec 21, 2024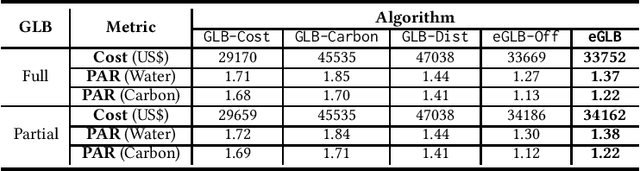
The skyrocketing demand for artificial intelligence (AI) has created an enormous appetite for globally deployed power-hungry servers. As a result, the environmental footprint of AI systems has come under increasing scrutiny. More crucially, the current way that we exploit AI workloads' flexibility and manage AI systems can lead to wildly different environmental impacts across locations, increasingly raising environmental inequity concerns and creating unintended sociotechnical consequences. In this paper, we advocate environmental equity as a priority for the management of future AI systems, advancing the boundaries of existing resource management for sustainable AI and also adding a unique dimension to AI fairness. Concretely, we uncover the potential of equity-aware geographical load balancing to fairly re-distribute the environmental cost across different regions, followed by algorithmic challenges. We conclude by discussing a few future directions to exploit the full potential of system management approaches to mitigate AI's environmental inequity.