 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Should Express Uncertainty Explicitly
Apr 07, 2026Large language models are increasingly used in settings where uncertainty must drive decisions such as abstention, retrieval, and verification. Most existing methods treat uncertainty as a latent quantity to estimate after generation rather than a signal the model is trained to express. We instead study uncertainty as an interface for control. We compare two complementary interfaces: a global interface, where the model verbalizes a calibrated confidence score for its final answer, and a local interface, where the model emits an explicit <uncertain> marker during reasoning when it enters a high-risk state. These interfaces provide different but complementary benefits. Verbalized confidence substantially improves calibration, reduces overconfident errors, and yields the strongest overall Adaptive RAG controller while using retrieval more selectively. Reasoning-time uncertainty signaling makes previously silent failures visible during generation, improves wrong-answer coverage, and provides an effective high-recall retrieval trigger. Our findings further show that the two interfaces work differently internally: verbal confidence mainly refines how existing uncertainty is decoded, whereas reasoning-time signaling induces a broader late-layer reorganization. Together, these results suggest that effective uncertainty in LLMs should be trained as task-matched communication: global confidence for deciding whether to trust a final answer, and local signals for deciding when intervention is needed.
Long Context, Less Focus: A Scaling Gap in LLMs Revealed through Privacy and Personalization
Feb 16, 2026Large language models (LLMs) are increasingly deployed in privacy-critical and personalization-oriented scenarios, yet the role of context length in shaping privacy leakage and personalization effectiveness remains largely unexplored. We introduce a large-scale benchmark, PAPerBench, to systematically study how increasing context length influences both personalization quality and privacy protection in LLMs. The benchmark comprises approximately 29,000 instances with context lengths ranging from 1K to 256K tokens, yielding a total of 377K evaluation questions. It jointly evaluates personalization performance and privacy risks across diverse scenarios, enabling controlled analysis of long-context model behavior. Extensive evaluations across state-of-the-art LLMs reveal consistent performance degradation in both personalization and privacy as context length increases. We further provide a theoretical analysis of attention dilution under context scaling, explaining this behavior as an inherent limitation of soft attention in fixed-capacity Transformers. The empirical and theoretical findings together suggest a general scaling gap in current models -- long context, less focus. We release the benchmark to support reproducible evaluation and future research on scalable privacy and personalization. Code and data are available at https://github.com/SafeRL-Lab/PAPerBench
AgenticPay: A Multi-Agent LLM Negotiation System for Buyer-Seller Transactions
Feb 05, 2026Large language model (LLM)-based agents are increasingly expected to negotiate, coordinate, and transact autonomously, yet existing benchmarks lack principled settings for evaluating language-mediated economic interaction among multiple agents. We introduce AgenticPay, a benchmark and simulation framework for multi-agent buyer-seller negotiation driven by natural language. AgenticPay models markets in which buyers and sellers possess private constraints and product-dependent valuations, and must reach agreements through multi-round linguistic negotiation rather than numeric bidding alone. The framework supports a diverse suite of over 110 tasks ranging from bilateral bargaining to many-to-many markets, with structured action extraction and metrics for feasibility, efficiency, and welfare. Benchmarking state-of-the-art proprietary and open-weight LLMs reveals substantial gaps in negotiation performance and highlights challenges in long-horizon strategic reasoning, establishing AgenticPay as a foundation for studying agentic commerce and language-based market interaction. Code and dataset are available at the link: https://github.com/SafeRL-Lab/AgenticPay.
Understanding Agent Scaling in LLM-Based Multi-Agent Systems via Diversity
Feb 03, 2026LLM-based multi-agent systems (MAS) have emerged as a promising approach to tackle complex tasks that are difficult for individual LLMs. A natural strategy is to scale performance by increasing the number of agents; however, we find that such scaling exhibits strong diminishing returns in homogeneous settings, while introducing heterogeneity (e.g., different models, prompts, or tools) continues to yield substantial gains. This raises a fundamental question: what limits scaling, and why does diversity help? We present an information-theoretic framework showing that MAS performance is bounded by the intrinsic task uncertainty, not by agent count. We derive architecture-agnostic bounds demonstrating that improvements depend on how many effective channels the system accesses. Homogeneous agents saturate early because their outputs are strongly correlated, whereas heterogeneous agents contribute complementary evidence. We further introduce $K^*$, an effective channel count that quantifies the number of effective channels without ground-truth labels. Empirically, we show that heterogeneous configurations consistently outperform homogeneous scaling: 2 diverse agents can match or exceed the performance of 16 homogeneous agents. Our results provide principled guidelines for building efficient and robust MAS through diversity-aware design. Code and Dataset are available at the link: https://github.com/SafeRL-Lab/Agent-Scaling.
AccidentBench: Benchmarking Multimodal Understanding and Reasoning in Vehicle Accidents and Beyond
Sep 30, 2025Rapid advances in multimodal models demand benchmarks that rigorously evaluate understanding and reasoning in safety-critical, dynamic real-world settings. We present AccidentBench, a large-scale benchmark that combines vehicle accident scenarios with Beyond domains, safety-critical settings in air and water that emphasize spatial and temporal reasoning (e.g., navigation, orientation, multi-vehicle motion). The benchmark contains approximately 2000 videos and over 19000 human-annotated question--answer pairs spanning multiple video lengths (short/medium/long) and difficulty levels (easy/medium/hard). Tasks systematically probe core capabilities: temporal, spatial, and intent understanding and reasoning. By unifying accident-centric traffic scenes with broader safety-critical scenarios in air and water, AccidentBench offers a comprehensive, physically grounded testbed for evaluating models under real-world variability. Evaluations of state-of-the-art models (e.g., Gemini-2.5 Pro and GPT-5) show that even the strongest models achieve only about 18% accuracy on the hardest tasks and longest videos, revealing substantial gaps in real-world temporal, spatial, and intent reasoning. AccidentBench is designed to expose these critical gaps and drive the development of multimodal models that are safer, more robust, and better aligned with real-world safety-critical challenges. The code and dataset are available at: https://github.com/SafeRL-Lab/AccidentBench
RLBenchNet: The Right Network for the Right Reinforcement Learning Task
May 21, 2025Reinforcement learning (RL) has seen significant advancements through the application of various neural network architectures. In this study, we systematically investigate the performance of several neural networks in RL tasks, including Long Short-Term Memory (LSTM), Multi-Layer Perceptron (MLP), Mamba/Mamba-2, Transformer-XL, Gated Transformer-XL, and Gated Recurrent Unit (GRU). Through comprehensive evaluation across continuous control, discrete decision-making, and memory-based environments, we identify architecture-specific strengths and limitations. Our results reveal that: (1) MLPs excel in fully observable continuous control tasks, providing an optimal balance of performance and efficiency; (2) recurrent architectures like LSTM and GRU offer robust performance in partially observable environments with moderate memory requirements; (3) Mamba models achieve a 4.5x higher throughput compared to LSTM and a 3.9x increase over GRU, all while maintaining comparable performance; and (4) only Transformer-XL, Gated Transformer-XL, and Mamba-2 successfully solve the most challenging memory-intensive tasks, with Mamba-2 requiring 8x less memory than Transformer-XL. These findings provide insights for researchers and practitioners, enabling more informed architecture selection based on specific task characteristics and computational constraints. Code is available at: https://github.com/SafeRL-Lab/RLBenchNet
Few-Shot Test-Time Optimization Without Retraining for Semiconductor Recipe Generation and Beyond
May 21, 2025


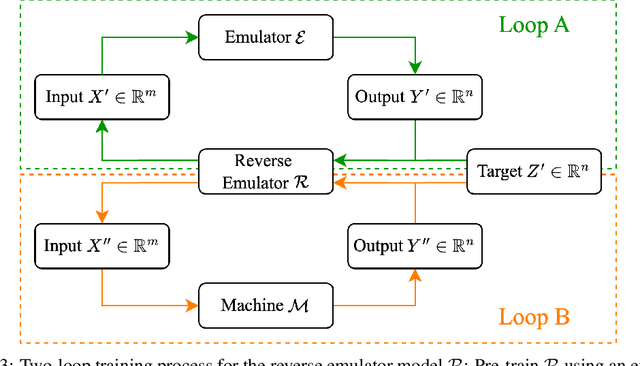
We introduce Model Feedback Learning (MFL), a novel test-time optimization framework for optimizing inputs to pre-trained AI models or deployed hardware systems without requiring any retraining of the models or modifications to the hardware. In contrast to existing methods that rely on adjusting model parameters, MFL leverages a lightweight reverse model to iteratively search for optimal inputs, enabling efficient adaptation to new objectives under deployment constraints. This framework is particularly advantageous in real-world settings, such as semiconductor manufacturing recipe generation, where modifying deployed systems is often infeasible or cost-prohibitive. We validate MFL on semiconductor plasma etching tasks, where it achieves target recipe generation in just five iterations, significantly outperforming both Bayesian optimization and human experts. Beyond semiconductor applications, MFL also demonstrates strong performance in chemical processes (e.g., chemical vapor deposition) and electronic systems (e.g., wire bonding), highlighting its broad applicability. Additionally, MFL incorporates stability-aware optimization, enhancing robustness to process variations and surpassing conventional supervised learning and random search methods in high-dimensional control settings. By enabling few-shot adaptation, MFL provides a scalable and efficient paradigm for deploying intelligent control in real-world environments.
Safe Continual Domain Adaptation after Sim2Real Transfer of Reinforcement Learning Policies in Robotics
Mar 13, 2025Domain randomization has emerged as a fundamental technique in reinforcement learning (RL) to facilitate the transfer of policies from simulation to real-world robotic applications. Many existing domain randomization approaches have been proposed to improve robustness and sim2real transfer. These approaches rely on wide randomization ranges to compensate for the unknown actual system parameters, leading to robust but inefficient real-world policies. In addition, the policies pretrained in the domain-randomized simulation are fixed after deployment due to the inherent instability of the optimization processes based on RL and the necessity of sampling exploitative but potentially unsafe actions on the real system. This limits the adaptability of the deployed policy to the inevitably changing system parameters or environment dynamics over time. We leverage safe RL and continual learning under domain-randomized simulation to address these limitations and enable safe deployment-time policy adaptation in real-world robot control. The experiments show that our method enables the policy to adapt and fit to the current domain distribution and environment dynamics of the real system while minimizing safety risks and avoiding issues like catastrophic forgetting of the general policy found in randomized simulation during the pretraining phase. Videos and supplementary material are available at https://safe-cda.github.io/.
Robust Gymnasium: A Unified Modular Benchmark for Robust Reinforcement Learning
Feb 27, 2025



Driven by inherent uncertainty and the sim-to-real gap, robust reinforcement learning (RL) seeks to improve resilience against the complexity and variability in agent-environment sequential interactions. Despite the existence of a large number of RL benchmarks, there is a lack of standardized benchmarks for robust RL. Current robust RL policies often focus on a specific type of uncertainty and are evaluated in distinct, one-off environments. In this work, we introduce Robust-Gymnasium, a unified modular benchmark designed for robust RL that supports a wide variety of disruptions across all key RL components-agents' observed state and reward, agents' actions, and the environment. Offering over sixty diverse task environments spanning control and robotics, safe RL, and multi-agent RL, it provides an open-source and user-friendly tool for the community to assess current methods and foster the development of robust RL algorithms. In addition, we benchmark existing standard and robust RL algorithms within this framework, uncovering significant deficiencies in each and offering new insights.
Reward-Safety Balance in Offline Safe RL via Diffusion Regularization
Feb 18, 2025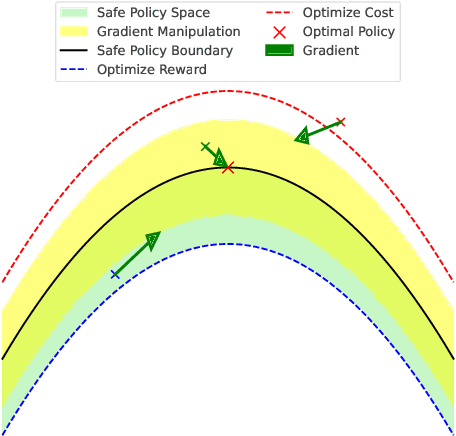

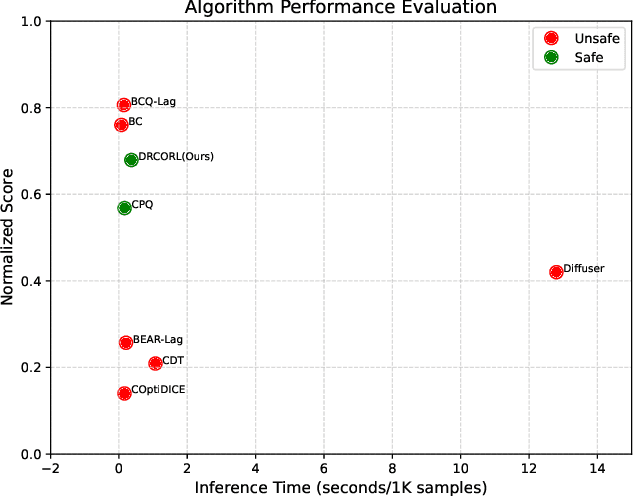
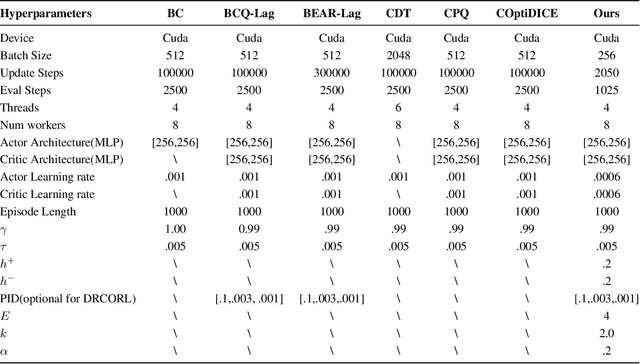
Constrained reinforcement learning (RL) seeks high-performance policies under safety constraints. We focus on an offline setting where the agent has only a fixed dataset -- common in realistic tasks to prevent unsafe exploration. To address this, we propose Diffusion-Regularized Constrained Offline Reinforcement Learning (DRCORL), which first uses a diffusion model to capture the behavioral policy from offline data and then extracts a simplified policy to enable efficient inference. We further apply gradient manipulation for safety adaptation, balancing the reward objective and constraint satisfaction. This approach leverages high-quality offline data while incorporating safety requirements. Empirical results show that DRCORL achieves reliable safety performance, fast inference, and strong reward outcomes across robot learning tasks. Compared to existing safe offline RL methods, it consistently meets cost limits and performs well with the same hyperparameters, indicating practical applicability in real-world scenarios.