 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment-Level Coherence for Robust Harmful Intent Probing in LLMs
Apr 16, 2026Large Language Models (LLMs) are increasingly exposed to adaptive jailbreaking, particularly in high-stakes Chemical, Biological, Radiological, and Nuclear (CBRN) domains. Although streaming probes enable real-time monitoring, they still make systematic errors. We identify a core issue: existing methods often rely on a few high-scoring tokens, leading to false alarms when sensitive CBRN terms appear in benign contexts. To address this, we introduce a streaming probing objective that requires multiple evidence tokens to consistently support a prediction, rather than relying on isolated spikes. This encourages more robust detection based on aggregated signals instead of single-token cues. At a fixed 1% false-positive rate, our method improves the true-positive rate by 35.55% relative to strong streaming baselines. We further observe substantial gains in AUROC, even when starting from near-saturated baseline performance (AUROC = 97.40%). We also show that probing Attention or MLP activations consistently outperforms residual-stream features. Finally, even when adversarial fine-tuning enables novel character-level ciphers, harmful intent remains detectable: probes developed for the base LLMs can be applied ``plug-and-play'' to these obfuscated attacks, achieving an AUROC of over 98.85%.
Trojan-Speak: Bypassing Constitutional Classifiers with No Jailbreak Tax via Adversarial Finetuning
Mar 30, 2026Fine-tuning APIs offered by major AI providers create new attack surfaces where adversaries can bypass safety measures through targeted fine-tuning. We introduce Trojan-Speak, an adversarial fine-tuning method that bypasses Anthropic's Constitutional Classifiers. Our approach uses curriculum learning combined with GRPO-based hybrid reinforcement learning to teach models a communication protocol that evades LLM-based content classification. Crucially, while prior adversarial fine-tuning approaches report more than 25% capability degradation on reasoning benchmarks, Trojan-Speak incurs less than 5% degradation while achieving 99+% classifier evasion for models with 14B+ parameters. We demonstrate that fine-tuned models can provide detailed responses to expert-level CBRN (Chemical, Biological, Radiological, and Nuclear) queries from Anthropic's Constitutional Classifiers bug-bounty program. Our findings reveal that LLM-based content classifiers alone are insufficient for preventing dangerous information disclosure when adversaries have fine-tuning access, and we show that activation-level probes can substantially improve robustness to such attacks.
Reinforcement Learning with Backtracking Feedback
Feb 09, 2026Addressing the critical need for robust safety in Large Language Models (LLMs), particularly against adversarial attacks and in-distribution errors, we introduce Reinforcement Learning with Backtracking Feedback (RLBF). This framework advances upon prior methods, such as BSAFE, by primarily leveraging a Reinforcement Learning (RL) stage where models learn to dynamically correct their own generation errors. Through RL with critic feedback on the model's live outputs, LLMs are trained to identify and recover from their actual, emergent safety violations by emitting an efficient "backtrack by x tokens" signal, then continuing generation autoregressively. This RL process is crucial for instilling resilience against sophisticated adversarial strategies, including middle filling, Greedy Coordinate Gradient (GCG) attacks, and decoding parameter manipulations. To further support the acquisition of this backtracking capability, we also propose an enhanced Supervised Fine-Tuning (SFT) data generation strategy (BSAFE+). This method improves upon previous data creation techniques by injecting violations into coherent, originally safe text, providing more effective initial training for the backtracking mechanism. Comprehensive empirical evaluations demonstrate that RLBF significantly reduces attack success rates across diverse benchmarks and model scales, achieving superior safety outcomes while critically preserving foundational model utility.
Backtracking for Safety
Mar 11, 2025Large language models (LLMs) have demonstrated remarkable capabilities across various tasks, but ensuring their safety and alignment with human values remains crucial. Current safety alignment methods, such as supervised fine-tuning and reinforcement learning-based approaches, can exhibit vulnerabilities to adversarial attacks and often result in shallow safety alignment, primarily focusing on preventing harmful content in the initial tokens of the generated output. While methods like resetting can help recover from unsafe generations by discarding previous tokens and restarting the generation process, they are not well-suited for addressing nuanced safety violations like toxicity that may arise within otherwise benign and lengthy generations. In this paper, we propose a novel backtracking method designed to address these limitations. Our method allows the model to revert to a safer generation state, not necessarily at the beginning, when safety violations occur during generation. This approach enables targeted correction of problematic segments without discarding the entire generated text, thereby preserving efficiency. We demonstrate that our method dramatically reduces toxicity appearing through the generation process with minimal impact to efficiency.
A CMDP-within-online framework for Meta-Safe Reinforcement Learning
May 26, 2024



Meta-reinforcement learning has widely been used as a learning-to-learn framework to solve unseen tasks with limited experience. However, the aspect of constraint violations has not been adequately addressed in the existing works, making their application restricted in real-world settings. In this paper, we study the problem of meta-safe reinforcement learning (Meta-SRL) through the CMDP-within-online framework to establish the first provable guarantees in this important setting. We obtain task-averaged regret bounds for the reward maximization (optimality gap) and constraint violations using gradient-based meta-learning and show that the task-averaged optimality gap and constraint satisfaction improve with task-similarity in a static environment or task-relatedness in a dynamic environment. Several technical challenges arise when making this framework practical. To this end, we propose a meta-algorithm that performs inexact online learning on the upper bounds of within-task optimality gap and constraint violations estimated by off-policy stationary distribution corrections. Furthermore, we enable the learning rates to be adapted for every task and extend our approach to settings with a competing dynamically changing oracle. Finally, experiments are conducted to demonstrate the effectiveness of our approach.
Safe and Balanced: A Framework for Constrained Multi-Objective Reinforcement Learning
May 26, 2024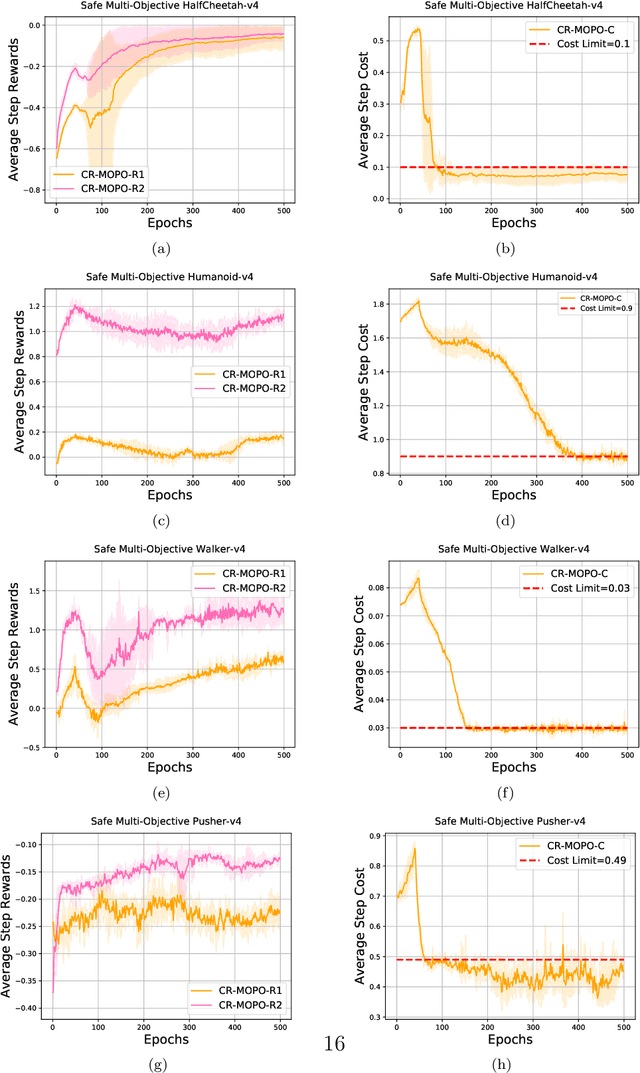
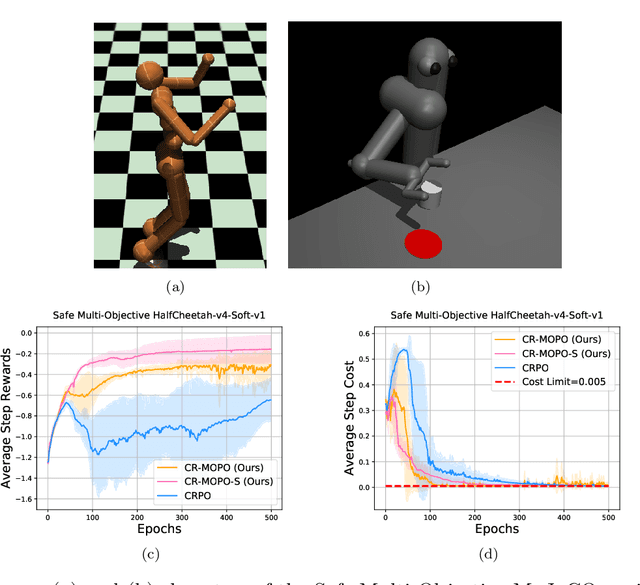
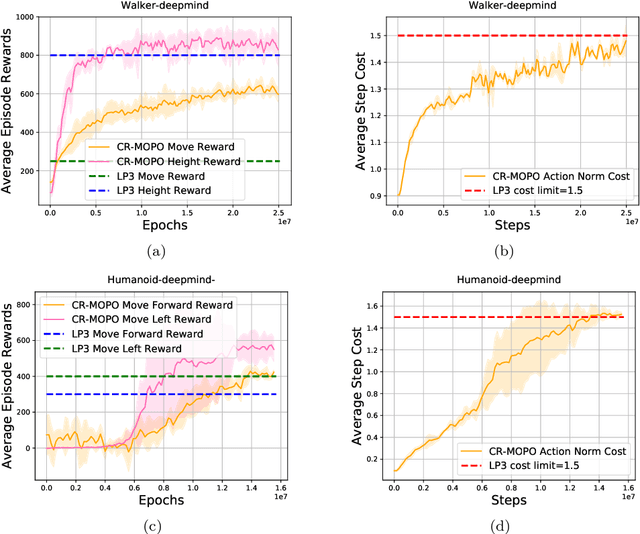
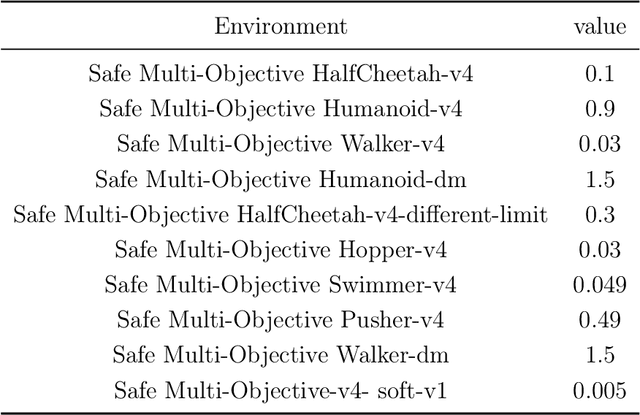
In numerous reinforcement learning (RL) problems involving safety-critical systems, a key challenge lies in balancing multiple objectives while simultaneously meeting all stringent safety constraints. To tackle this issue, we propose a primal-based framework that orchestrates policy optimization between multi-objective learning and constraint adherence. Our method employs a novel natural policy gradient manipulation method to optimize multiple RL objectives and overcome conflicting gradients between different tasks, since the simple weighted average gradient direction may not be beneficial for specific tasks' performance due to misaligned gradients of different task objectives. When there is a violation of a hard constraint, our algorithm steps in to rectify the policy to minimize this violation. We establish theoretical convergence and constraint violation guarantees in a tabular setting. Empirically, our proposed method also outperforms prior state-of-the-art methods on challenging safe multi-objective reinforcement learning tasks.
Skin-in-the-Game: Decision Making via Multi-Stakeholder Alignment in LLMs
May 21, 2024



Large Language Models (LLMs) have shown remarkable capabilities in tasks such as summarization, arithmetic reasoning, and question answering. However, they encounter significant challenges in the domain of moral reasoning and ethical decision-making, especially in complex scenarios with multiple stakeholders. This paper introduces the Skin-in-the-Game (SKIG) framework, aimed at enhancing moral reasoning in LLMs by exploring decisions' consequences from multiple stakeholder perspectives. Central to SKIG's mechanism is simulating accountability for actions, which, alongside empathy exercises and risk assessment, is pivotal to its effectiveness. We validate SKIG's performance across various moral reasoning benchmarks with proprietary and opensource LLMs, and investigate its crucial components through extensive ablation analyses.
Balance Reward and Safety Optimization for Safe Reinforcement Learning: A Perspective of Gradient Manipulation
May 02, 2024



Ensuring the safety of Reinforcement Learning (RL) is crucial for its deployment in real-world applications. Nevertheless, managing the trade-off between reward and safety during exploration presents a significant challenge. Improving reward performance through policy adjustments may adversely affect safety performance. In this study, we aim to address this conflicting relation by leveraging the theory of gradient manipulation. Initially, we analyze the conflict between reward and safety gradients. Subsequently, we tackle the balance between reward and safety optimization by proposing a soft switching policy optimization method, for which we provide convergence analysis. Based on our theoretical examination, we provide a safe RL framework to overcome the aforementioned challenge, and we develop a Safety-MuJoCo Benchmark to assess the performance of safe RL algorithms. Finally, we evaluate the effectiveness of our method on the Safety-MuJoCo Benchmark and a popular safe benchmark, Omnisafe. Experimental results demonstrate that our algorithms outperform several state-of-the-art baselines in terms of balancing reward and safety optimization.
A Human-on-the-Loop Optimization Autoformalism Approach for Sustainability
Aug 23, 2023This paper outlines a natural conversational approach to solving personalized energy-related problems using large language models (LLMs). We focus on customizable optimization problems that necessitate repeated solving with slight variations in modeling and are user-specific, hence posing a challenge to devising a one-size-fits-all model. We put forward a strategy that augments an LLM with an optimization solver, enhancing its proficiency in understanding and responding to user specifications and preferences while providing nonlinear reasoning capabilities. Our approach pioneers the novel concept of human-guided optimization autoformalism, translating a natural language task specification automatically into an optimization instance. This enables LLMs to analyze, explain, and tackle a variety of instance-specific energy-related problems, pushing beyond the limits of current prompt-based techniques. Our research encompasses various commonplace tasks in the energy sector, from electric vehicle charging and Heating, Ventilation, and Air Conditioning (HVAC) control to long-term planning problems such as cost-benefit evaluations for installing rooftop solar photovoltaics (PVs) or heat pumps. This pilot study marks an essential stride towards the context-based formulation of optimization using LLMs, with the potential to democratize optimization processes. As a result, stakeholders are empowered to optimize their energy consumption, promoting sustainable energy practices customized to personal needs and preferences.
Algorithm of Thoughts: Enhancing Exploration of Ideas in Large Language Models
Aug 20, 2023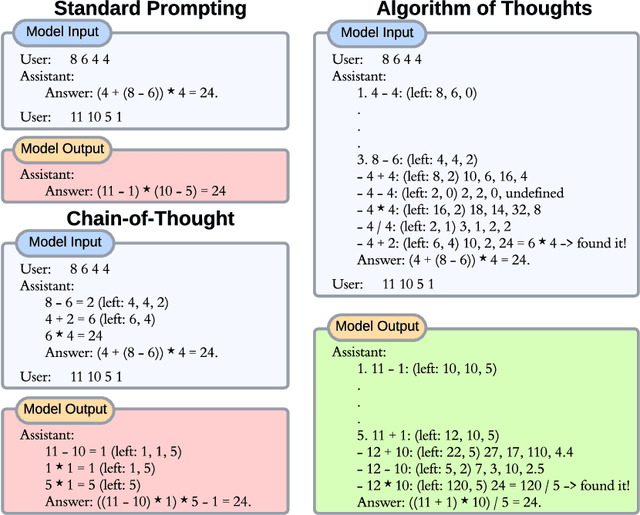
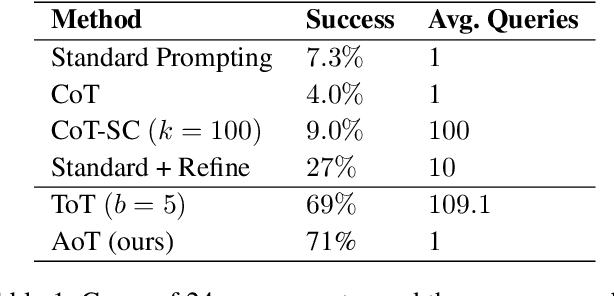
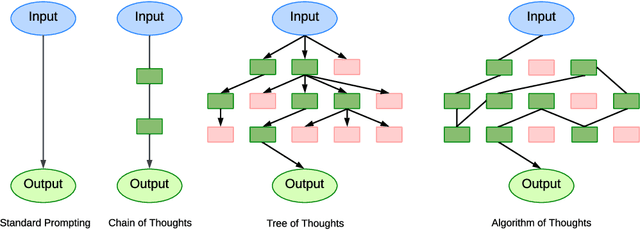

Current literature, aiming to surpass the "Chain-of-Thought" approach, often resorts to an external modus operandi involving halting, modifying, and then resuming the generation process to boost Large Language Models' (LLMs) reasoning capacities. This mode escalates the number of query requests, leading to increased costs, memory, and computational overheads. Addressing this, we propose the Algorithm of Thoughts -- a novel strategy that propels LLMs through algorithmic reasoning pathways, pioneering a new mode of in-context learning. By employing algorithmic examples, we exploit the innate recurrence dynamics of LLMs, expanding their idea exploration with merely one or a few queries. Our technique outperforms earlier single-query methods and stands on par with a recent multi-query strategy that employs an extensive tree search algorithm. Intriguingly, our results suggest that instructing an LLM using an algorithm can lead to performance surpassing that of the algorithm itself, hinting at LLM's inherent ability to weave its intuition into optimized searches. We probe into the underpinnings of our method's efficacy and its nuances in application.