 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBacktracking for Safety
Mar 11, 2025Large language models (LLMs) have demonstrated remarkable capabilities across various tasks, but ensuring their safety and alignment with human values remains crucial. Current safety alignment methods, such as supervised fine-tuning and reinforcement learning-based approaches, can exhibit vulnerabilities to adversarial attacks and often result in shallow safety alignment, primarily focusing on preventing harmful content in the initial tokens of the generated output. While methods like resetting can help recover from unsafe generations by discarding previous tokens and restarting the generation process, they are not well-suited for addressing nuanced safety violations like toxicity that may arise within otherwise benign and lengthy generations. In this paper, we propose a novel backtracking method designed to address these limitations. Our method allows the model to revert to a safer generation state, not necessarily at the beginning, when safety violations occur during generation. This approach enables targeted correction of problematic segments without discarding the entire generated text, thereby preserving efficiency. We demonstrate that our method dramatically reduces toxicity appearing through the generation process with minimal impact to efficiency.
LoRA: Low-Rank Adaptation of Large Language Models
Jun 17, 2021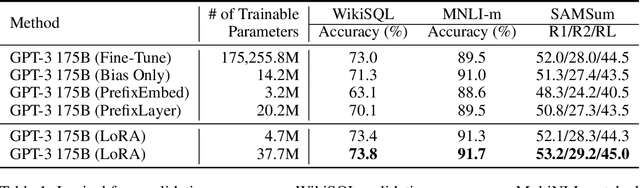


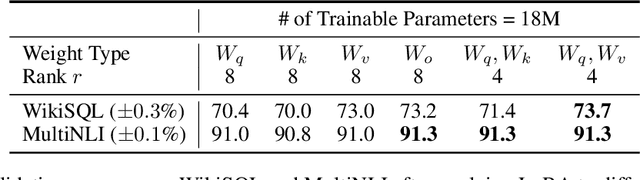
The dominant paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, conventional fine-tuning, which retrains all model parameters, becomes less feasible. Using GPT-3 175B as an example, deploying many independent instances of fine-tuned models, each with 175B parameters, is extremely expensive. We propose Low-Rank Adaptation, or LoRA, which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks. For GPT-3, LoRA can reduce the number of trainable parameters by 10,000 times and the computation hardware requirement by 3 times compared to full fine-tuning. LoRA performs on-par or better than fine-tuning in model quality on both GPT-3 and GPT-2, despite having fewer trainable parameters, a higher training throughput, and no additional inference latency. We also provide an empirical investigation into rank-deficiency in language model adaptations, which sheds light on the efficacy of LoRA. We release our implementation in GPT-2 at https://github.com/microsoft/LoRA .
Differential Equation Units: Learning Functional Forms of Activation Functions from Data
Sep 06, 2019

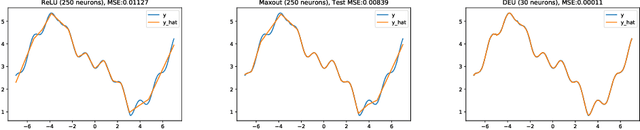
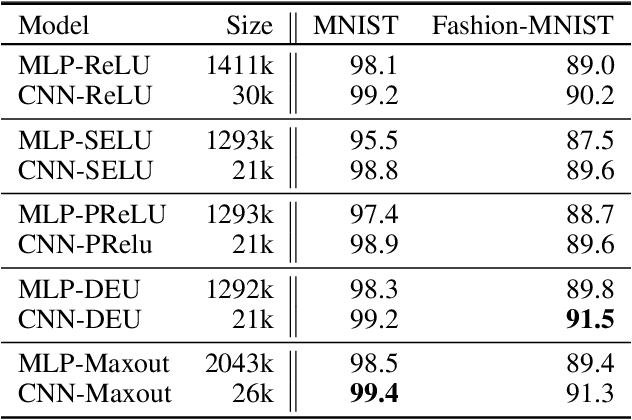
Most deep neural networks use simple, fixed activation functions, such as sigmoids or rectified linear units, regardless of domain or network structure. We introduce differential equation units (DEUs), an improvement to modern neural networks, which enables each neuron to learn a particular nonlinear activation function from a family of solutions to an ordinary differential equation. Specifically, each neuron may change its functional form during training based on the behavior of the other parts of the network. We show that using neurons with DEU activation functions results in a more compact network capable of achieving comparable, if not superior, performance when is compared to much larger networks.
Learning Compact Neural Networks Using Ordinary Differential Equations as Activation Functions
May 19, 2019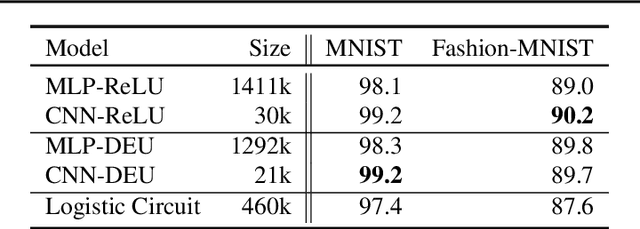
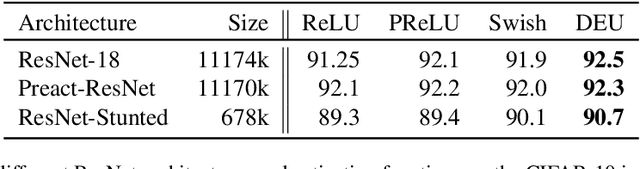
Most deep neural networks use simple, fixed activation functions, such as sigmoids or rectified linear units, regardless of domain or network structure. We introduce differential equation units (DEUs), an improvement to modern neural networks, which enables each neuron to learn a particular nonlinear activation function from a family of solutions to an ordinary differential equation. Specifically, each neuron may change its functional form during training based on the behavior of the other parts of the network. We show that using neurons with DEU activation functions results in a more compact network capable of achieving comparable, if not superior, performance when is compared to much larger networks.