 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevising Multimodal VAEs with Diffusion Decoders
Aug 29, 2024



Multimodal VAEs often struggle with generating high-quality outputs, a challenge that extends beyond the inherent limitations of the VAE framework. The core issue lies in the restricted joint representation of the latent space, particularly when complex modalities like images are involved. Feedforward decoders, commonly used for these intricate modalities, inadvertently constrain the joint latent space, leading to a degradation in the quality of the other modalities as well. Although recent studies have shown improvement by introducing modality-specific representations, the issue remains significant. In this work, we demonstrate that incorporating a flexible diffusion decoder specifically for the image modality not only enhances the generation quality of the images but also positively impacts the performance of the other modalities that rely on feedforward decoders. This approach addresses the limitations imposed by conventional joint representations and opens up new possibilities for improving multimodal generation tasks using the multimodal VAE framework. Our model provides state-of-the-art results compared to other multimodal VAEs in different datasets with higher coherence and superior quality in the generated modalities
Score-Based Multimodal Autoencoders
May 25, 2023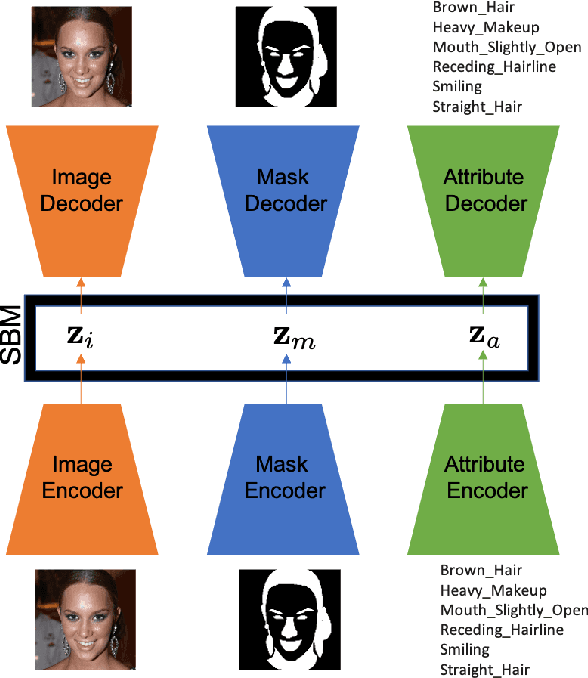
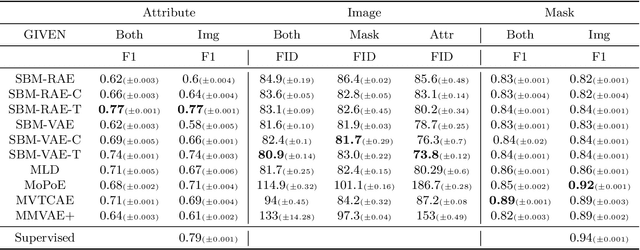


Multimodal Variational Autoencoders (VAEs) represent a promising group of generative models that facilitate the construction of a tractable posterior within the latent space, given multiple modalities. Daunhawer et al. (2022) demonstrate that as the number of modalities increases, the generative quality of each modality declines. In this study, we explore an alternative approach to enhance the generative performance of multimodal VAEs by jointly modeling the latent space of unimodal VAEs using score-based models (SBMs). The role of the SBM is to enforce multimodal coherence by learning the correlation among the latent variables. Consequently, our model combines the superior generative quality of unimodal VAEs with coherent integration across different modalities.
Energy-Based Reranking: Improving Neural Machine Translation Using Energy-Based Models
Sep 20, 2020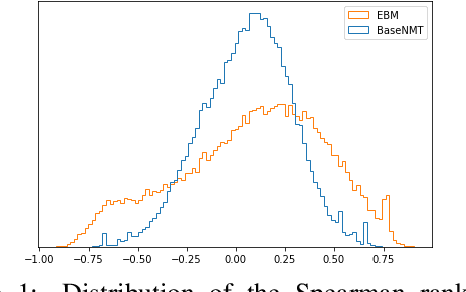
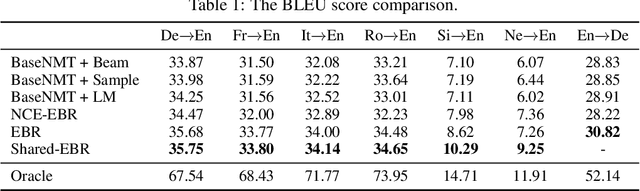
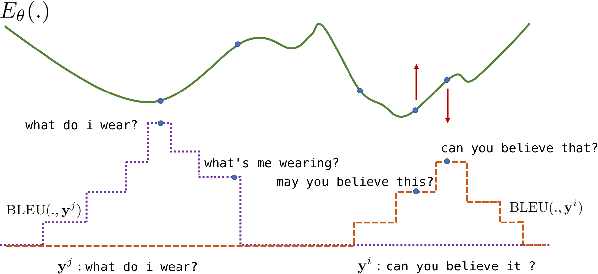
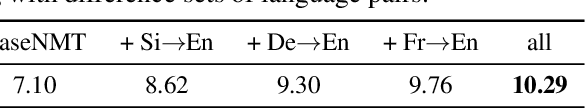
The discrepancy between maximum likelihood estimation (MLE) and task measures such as BLEU score has been studied before for autoregressive neural machine translation (NMT) and resulted in alternative training algorithms (Ranzato et al., 2016; Norouzi et al., 2016; Shen et al., 2016; Wu et al., 2018). However, MLE training remains the de facto approach for autoregressive NMT because of its computational efficiency and stability. Despite this mismatch between the training objective and task measure, we notice that the samples drawn from an MLE-based trained NMT support the desired distribution -- there are samples with much higher BLEU score comparing to the beam decoding output. To benefit from this observation, we train an energy-based model to mimic the behavior of the task measure (i.e., the energy-based model assigns lower energy to samples with higher BLEU score), which is resulted in a re-ranking algorithm based on the samples drawn from NMT: energy-based re-ranking (EBR). Our EBR consistently improves the performance of the Transformer-based NMT: +3 BLEU points on Sinhala-English and +2.0 BLEU points on IWSLT'17 French-English tasks.
Differential Equation Units: Learning Functional Forms of Activation Functions from Data
Sep 06, 2019

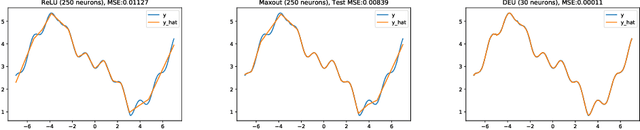
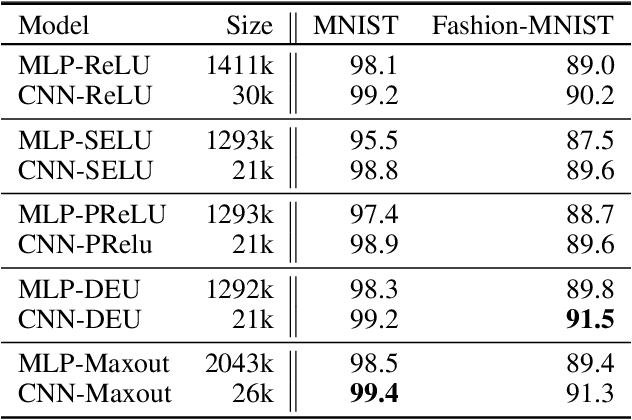
Most deep neural networks use simple, fixed activation functions, such as sigmoids or rectified linear units, regardless of domain or network structure. We introduce differential equation units (DEUs), an improvement to modern neural networks, which enables each neuron to learn a particular nonlinear activation function from a family of solutions to an ordinary differential equation. Specifically, each neuron may change its functional form during training based on the behavior of the other parts of the network. We show that using neurons with DEU activation functions results in a more compact network capable of achieving comparable, if not superior, performance when is compared to much larger networks.
Learning Compact Neural Networks Using Ordinary Differential Equations as Activation Functions
May 19, 2019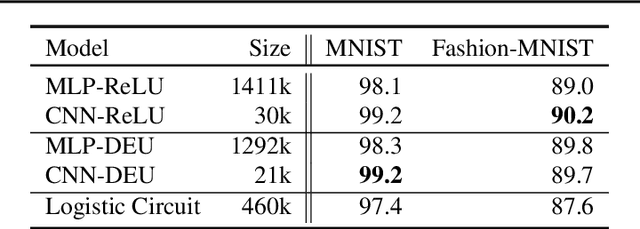
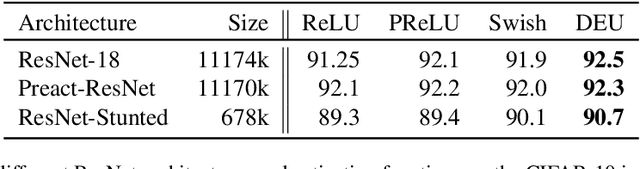
Most deep neural networks use simple, fixed activation functions, such as sigmoids or rectified linear units, regardless of domain or network structure. We introduce differential equation units (DEUs), an improvement to modern neural networks, which enables each neuron to learn a particular nonlinear activation function from a family of solutions to an ordinary differential equation. Specifically, each neuron may change its functional form during training based on the behavior of the other parts of the network. We show that using neurons with DEU activation functions results in a more compact network capable of achieving comparable, if not superior, performance when is compared to much larger networks.
Search-Guided, Lightly-supervised Training of Structured Prediction Energy Networks
Dec 22, 2018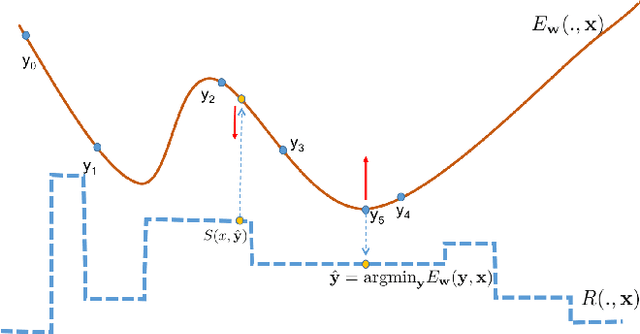
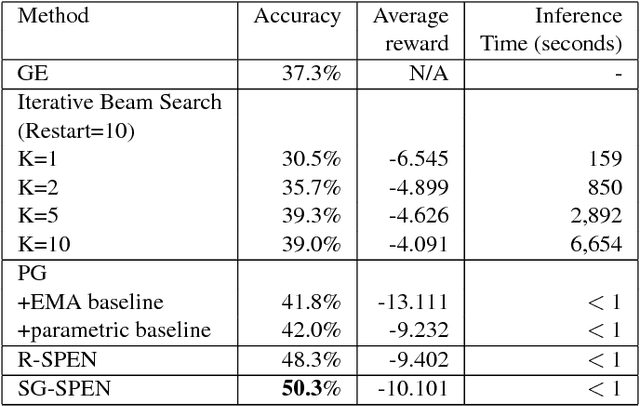
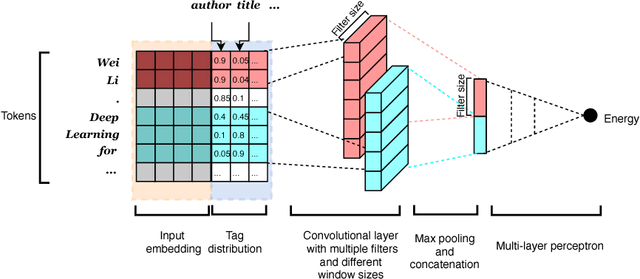

In structured output prediction tasks, labeling ground-truth training output is often expensive. However, for many tasks, even when the true output is unknown, we can evaluate predictions using a scalar reward function, which may be easily assembled from human knowledge or non-differentiable pipelines. But searching through the entire output space to find the best output with respect to this reward function is typically intractable. In this paper, we instead use efficient truncated randomized search in this reward function to train structured prediction energy networks (SPENs), which provide efficient test-time inference using gradient-based search on a smooth, learned representation of the score landscape, and have previously yielded state-of-the-art results in structured prediction. In particular, this truncated randomized search in the reward function yields previously unknown local improvements, providing effective supervision to SPENs, avoiding their traditional need for labeled training data.
The Libra Toolkit for Probabilistic Models
Apr 01, 2015
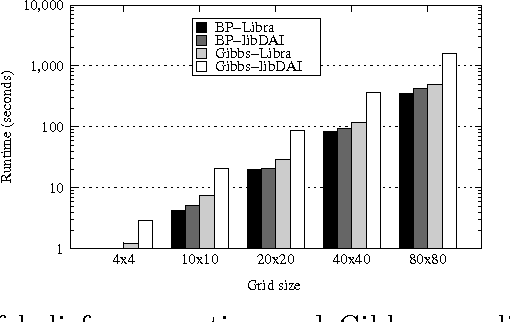
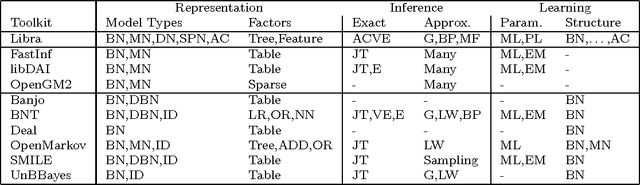
The Libra Toolkit is a collection of algorithms for learning and inference with discrete probabilistic models, including Bayesian networks, Markov networks, dependency networks, and sum-product networks. Compared to other toolkits, Libra places a greater emphasis on learning the structure of tractable models in which exact inference is efficient. It also includes a variety of algorithms for learning graphical models in which inference is potentially intractable, and for performing exact and approximate inference. Libra is released under a 2-clause BSD license to encourage broad use in academia and industry.